






摘要
本文介绍了一种训练类似 o1 的RAG 模型的方法,该方法在生成最终答案之前逐步检索和推理相关信息。传统的 RAG 方法通常在生成过程之前执行单个检索步骤,由于检索结果不完善,这限制了它们在处理复杂 query 方面的有效性。相比之下,我们提出的方法 CoRAG (Chain-of-Retrieval Augmented Generation) 允许模型根据不断变化的状态动态地重新制定 query。为了有效地训练 CoRAG,我们利用拒绝采样来自动生成中间检索链,从而增强仅提供正确最终答案的现有 RAG 数据集。在测试时,我们提出了各种解码策略,通过控制采样检索链的长度和数量来扩展模型的测试时计算。跨多个基准的实验结果验证了 CoRAG 的有效性,特别是在多跳问答任务中,我们观察到与强基线相比,EM 分数提高了 10 分以上。在 KILT 基准测试中,CoRAG 在各种知识密集型任务中建立了新的先进性能。此外,我们还提供全面的分析来了解 CoRAG 的扩展行为,为未来旨在开发事实和扎实基础模型的研究奠定基础。
1.介绍
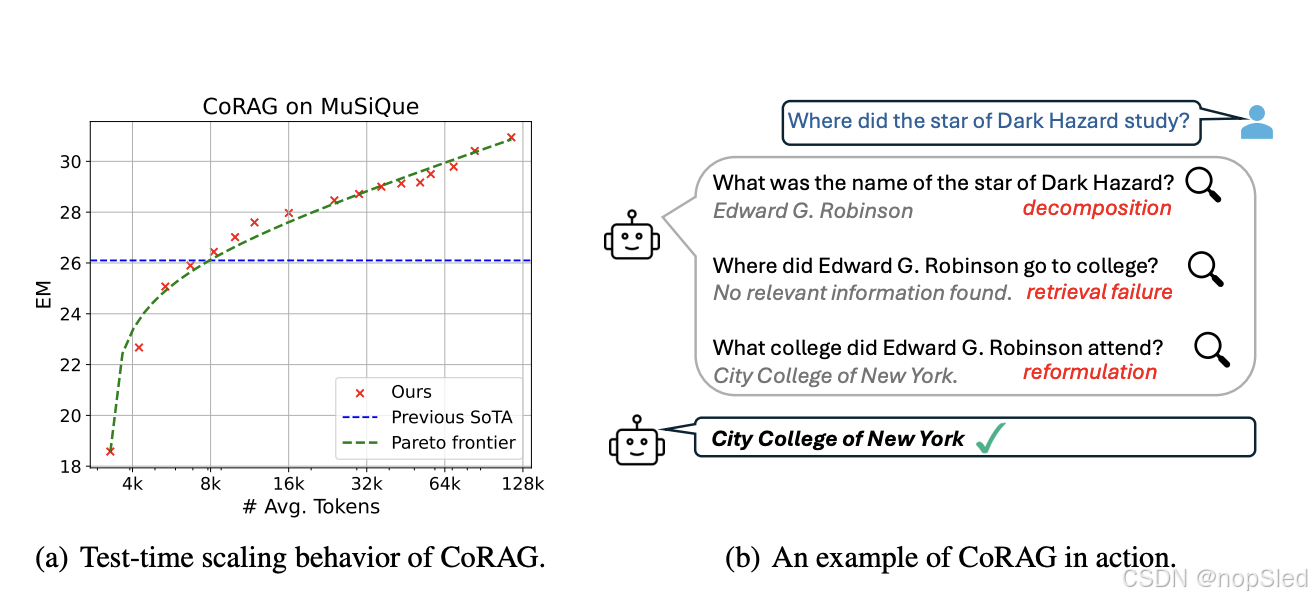
检索增强生成 (RAG) 是企业应用中的核心技术之一,需要将大型基础模型与专有数据源集成,以生成既有根据又符合事实的响应。传统上,基础模型是在包含数万亿个 token 的大规模数据集上进行训练的,并且在部署后保持冻结状态。尽管如此,这些模型经常难以记住长尾事实知识,或者可能产生虚假声明的幻觉,导致在现实场景中响应不可靠。RAG 通过使用检索到的信息增强生成过程来缓解这一挑战,从而提高模型生成内容的可信度并促进最新信息的整合。
当代 RAG 系统通常采用顺序的检索和生成流水线,其中检索到的信息作为生成模型的附加输入。RAG 系统的有效性主要取决于检索到的信息的质量。检索模型的设计旨在提高效率,以确保可扩展到大型语料库。例如,密集检索器通常使用双向编码器架构将文档和 query 压缩为固定大小的向量表示。这种架构选择允许使用快速近似最近邻搜索算法,但同时限制了检索模型处理复杂 query 的表达能力。此外,在多跳推理任务中,通常不清楚最初应该检索什么信息;必须根据推理过程的逐步发展状态做出决策。
为了突破检索质量的瓶颈,我们提出了一个框架,该框架可以动态检索相关信息并根据当前状态规划后续检索步骤。通过在测试时调整检索步骤的数量,我们的模型可以探索 query 的各个方面,并在检索器未产生有用信息时尝试不同的 query 重写策略。这个范例反映了人类解决问题的过程,我们迭代地寻找信息来解决复杂的问题。
我们主张直接训练语言模型以逐步检索,而不是仅仅依赖模型的上下文学习能力或专有模型的蒸馏。为此,我们利用拒绝抽样来增强现有 RAG 数据集的中间检索链。然后使用标准的下一个 token 预测目标在这些增强的数据集上对开源语言模型进行微调。为了检查我们模型的扩展行为,我们提出了各种测试时解码策略,包括贪心解码、best-of-N 采样和树搜索。可以采用多种解码策略和超参数配置来控制测试时 token 消耗和检索器调用的频率。
我们的实证评估表明,CoRAG 在需要多跳推理的 QA 任务中大大超越了强大的基线,在这些任务中,检索器经常难以在单个检索步骤中召回起所有必要的信息。在不同的解码策略中,帕累托前沿大致遵循总 token 消耗和模型性能之间的对数线性关系,尽管系数在不同的数据集中有所不同。
在涵盖更多不同任务的 KILT 基准测试中,几乎所有任务的隐藏测试集都取得了新的最佳分数。此外,我们发现 CoRAG 在不同任务类型中表现出不同的扩展行为。对于 NQ 等数据集,其中最佳检索器已经实现了高召回率,测试时间扩展的好处通常很小。这表明可以根据 query 的复杂性和检索器的质量动态分配测试时计算。经过进一步分析,我们发现 CoRAG 可以有效地分解复杂 query 并执行灵活的query 重新表示,以提高生成的响应的质量。它还显示出对不同质量的检索器的稳健性。我们认为 CoRAG 代表了 RAG 领域未来研究的有希望的途径,有可能减轻模型生成内容中的幻觉。
2.相关工作
Retrieval-Augmented Generation (RAG) 将信息检索技术与生成模型相结合,以提高生成内容的质量和事实准确性。通过为 LLM 配备网页浏览的能力,RAG 系统可以访问实时数据,从而提供最新且有根据的响应。检索到的信息的相关性和质量对于 RAG 系统的有效性至关重要。最近大量的研究集中在开发更好的通用文本嵌入上。然而,由于文本嵌入为了提高效率而依赖固定大小的向量表示,因此在处理复杂 query 时经常会受到限制。
为了缓解这一限制,当代研究扩展了传统的单一检索步骤后再生成的范式,发展为多步骤迭代检索和生成。FLARE 促使 LLM 主动确定在生成过程中何时检索什么。ITER-RETGEN 建议将检索增强生成与生成增强检索交错,展示多跳 QA 任务的增强功能。同样,IRCoT 采用思维链方法,以递归方式细化后续检索步骤的推理思维。Self-RAG 使 LLM 能够通过自我反思自适应地检索、生成和批评,从而提高开放域 QA 和长篇生成任务中的事实准确性和引用精度。Auto-RAG 利用启发式规则和精确答案匹配来构建中间检索步骤,但其性能仍远低于最先进的模型。在本研究中,我们提出了一种新的方法来明确训练 LLM 以迭代方式检索和推理相关信息,而不是仅仅依靠 few-shot 提示或专有模型的蒸馏。
Scaling Test-time Compute。思维链 (CoT) 不是让 LLM 直接生成最终答案,而是让模型一步一步思考,可以大幅提高数学推理任务的性能。思维树 (ToT) 通过采用树结构扩展了 CoT 的思想,让模型更全面地探索搜索空间。为了进一步增强 LLM 的推理能力,STaR 建议利用引导技术来生成用于训练的中间状态。OpenAI o1 进行大规模强化学习,并在高级推理数据集上表现出有希望的测试时间扩展行为,但技术细节尚未公开。这些方法的缺点是增加了 token 消耗,从而增加了响应延迟。
在 RAG 领域,可以通过检索更多文档或执行更多检索步骤来增加测试时计算。LongRAG 认为,通过将长上下文 LLM 与更多检索到的文档相结合,可以提高 RAG 性能。相比之下,IterDRAG 通过对多达 500 万个 token 进行 few-shot 提示和迭代检索,实证检验了测试时间扩展规律。并发工作 Search-o1 将开源 QwQ 模型与 Bing 的主动搜索相结合,在知识密集型任务上取得了有竞争力的结果。我们的工作将 RAG 中测试时间扩展的研究扩展到不同解码策略下的目标微调范式。
3.方法
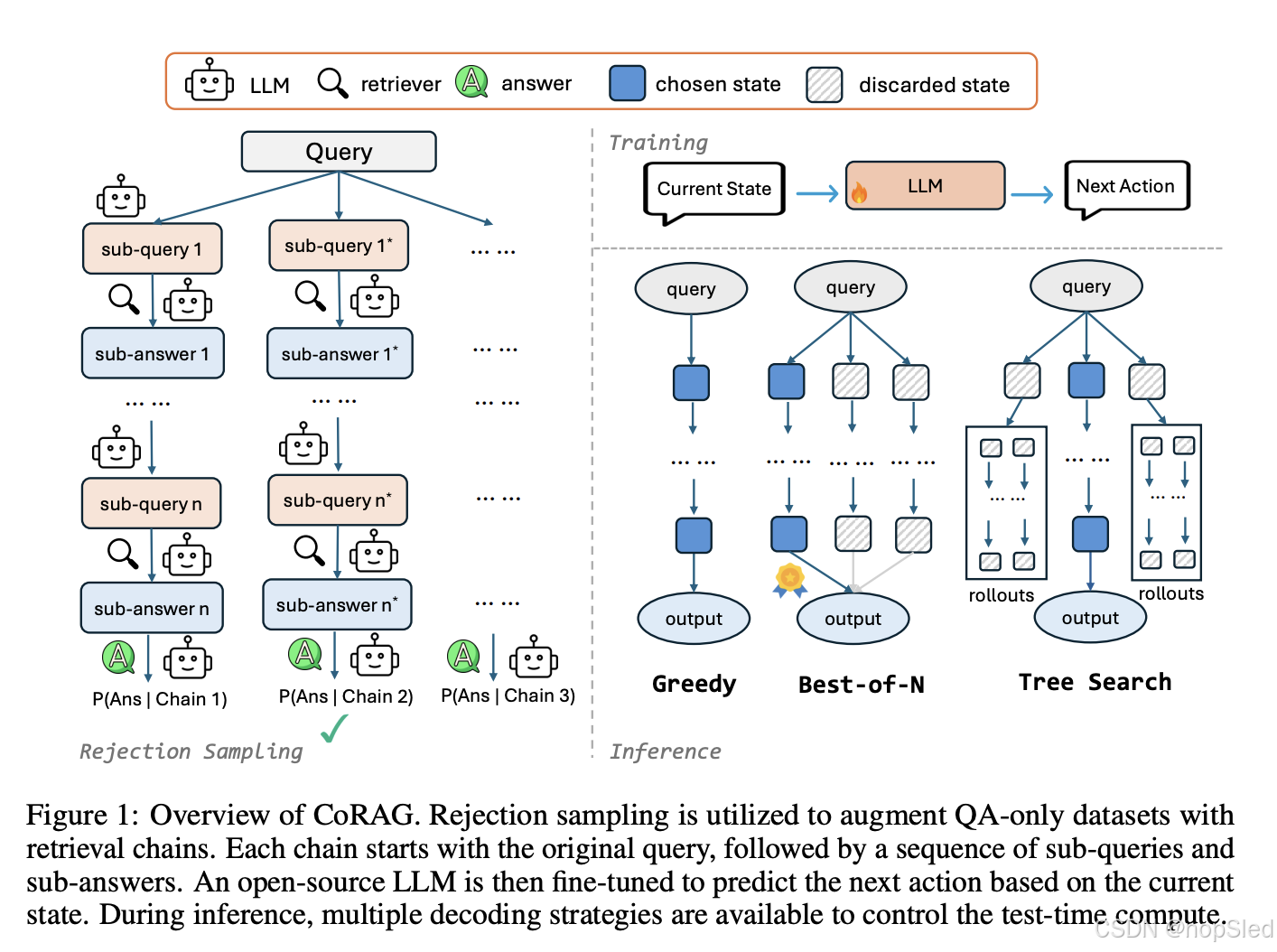
CoRAG 框架如图 1 所示。在本节中,我们描述 CoRAG 的关键组件,包括通过拒绝采样生成检索链、使用增强数据集进行模型训练以及扩展测试时计算的策略。
3.1 Retrieval Chain Generation
大多数 RAG 数据集仅带有query
Q
Q
Q 和相应的最终答案
A
A
A,而不提供中间检索步骤。我们提出了一种通过拒绝采样自动生成检索链的方法。每个采样链由一系列 sub-query
Q
1
:
L
=
{
Q
1
,
Q
2
,
.
.
.
,
Q
L
}
Q_{1:L} = \{Q_1, Q_2, . . . , Q_L\}
Q1:L={Q1,Q2,...,QL} 和相应的 sub-answer
A
1
:
L
A_{1:L}
A1:L 组成,其中
L
L
L 是预定的最大链长度。sub-query
Q
i
=
L
L
M
(
Q
<
i
,
A
<
i
,
Q
)
Q_i = LLM(Q_{<i}, A_{<i}, Q)
Qi=LLM(Q<i,A<i,Q) 是通过基于query
Q
Q
Q 和前面的sub-query 和 sub-answer 对 LLM 进行抽样生成的。为了生成sub-answer
A
i
A_i
Ai,我们首先使用以
Q
i
Q_i
Qi 为搜索 query 的文本检索器检索 top-k 个最相关的文档
D
1
:
k
(
i
)
D^{(i)}_{1:k}
D1:k(i),然后提示 LLM 得出答案
A
i
=
L
L
M
(
Q
i
,
D
1
:
k
(
i
)
)
A_i = LLM(Q_i, D^{(i)}_{1:k})
Ai=LLM(Qi,D1:k(i))。此过程
不断迭代,直到达到最大长度
L
L
L 或
A
i
A_i
Ai 与正确答案
A
A
A 匹配。
为了评估检索链的质量,我们根据链信息计算正确答案的对数似然
l
o
g
P
(
A
∣
Q
,
Q
1
:
L
,
A
1
:
L
)
log~P(A|Q, Q_{1:L}, A_{1:L})
log P(A∣Q,Q1:L,A1:L)。选择对数似然得分最高的检索链来扩充原始的 QA 专用数据集。
3.2 Training
增强数据集中的每个训练实例都表示为一个元组
(
Q
,
A
,
Q
1
:
L
,
A
1
:
L
)
(Q, A, Q_{1:L}, A_{1:L})
(Q,A,Q1:L,A1:L),并附有query
Q
Q
Q 和每个 sub-query 的相应 top-k 个检索文档。我们使用多任务学习框架中的标准下一个 token 预测目标对增强数据集上的 LLM 进行微调。
该模型同时针对三个任务进行训练:下一个 sub-query 预测、sub-answer 预测和最终答案预测。我们使用与检索链生成过程中相同的提示模板,不同之处在于我们还将原始query
Q
Q
Q 的对应检索文档
D
1
:
k
D_{1:k}
D1:k 纳入最终答案预测任务的输入。
L
s
u
b
_
q
u
e
r
y
=
−
l
o
g
P
(
Q
i
∣
Q
,
Q
<
i
,
A
<
i
)
,
i
∈
[
1
,
L
]
L_{sub\_query}=-log~P(Q_i|Q,Q_{\lt i},A_{\lt i}),i\in [1,L]
Lsub_query=−log P(Qi∣Q,Q<i,A<i),i∈[1,L]
L
s
u
b
_
a
n
s
w
e
r
=
−
l
o
g
P
(
A
i
∣
Q
i
,
D
1
:
k
(
i
)
)
,
i
∈
[
1
,
L
]
L_{sub\_answer}=-log~P(A_i|Q_{i},D^{(i)}_{1:k}),i\in [1,L]
Lsub_answer=−log P(Ai∣Qi,D1:k(i)),i∈[1,L]
L
f
i
n
a
l
_
a
n
s
w
e
r
=
−
l
o
g
P
(
A
∣
Q
,
Q
1
:
L
,
A
1
:
L
,
D
1
:
k
)
L_{final\_answer}=-log~P(A|Q,Q_{1:L},A_{1:L},D_{1:k})
Lfinal_answer=−log P(A∣Q,Q1:L,A1:L,D1:k)
交叉熵损失仅针对目标输出 token 进行计算。由于我们重复使用提示模板进行数据生成和模型训练,因此可以以迭代方式利用微调模型进行下一轮拒绝采样。
3.3 Test-time Scaling
给定一个经过训练的 CoRAG 模型,我们提出了几种解码策略来控制模型性能和测试时计算之间的权衡。测试时计算以 token 消耗的总数来衡量,不包括检索成本。与以前仅考虑提示 token 或生成 token 的方法不同,我们同时考虑了两者。为了简化进一步的讨论,提示 token 与生成 token 同等对待,尽管由于前缀缓存和预填充阶段的计算并行性,提示 token 通常更便宜。
Greedy Decoding。该策略利用贪心解码依次生成L个 sub-query 及其对应的 sub-answer,最终答案使用与训练阶段相同的提示模板生成。
Best-of-N Sampling。该方法涉及对 temperature 为 0.7 的 N 条检索链进行采样,然后选择最佳链来生成最终答案。由于测试时没有基本事实答案,因此我们改为计算“未找到相关信息”的条件对数似然作为每条链的惩罚分数。选择惩罚分数最低的检索链。
Tree Search。我们实现了具有检索链展开的广度优先搜索 (BFS) 变体。在每个步骤中,通过抽样几个 sub-query 来扩展当前状态。对于每个扩展状态,我们执行多个展开,然后计算这些展开的平均惩罚分数。保留平均惩罚分数最低的状态以供进一步扩展。
为了控制测试时计算,可以在所有解码策略中调整检索链
L
L
L 的最大长度。对于 best-of-N 采样,采样链的数量 N 提供了扩展测试时计算的另一种选择。在树搜索中,rollout 的数量和扩展大小是两个额外的超参数。
4.Experiments
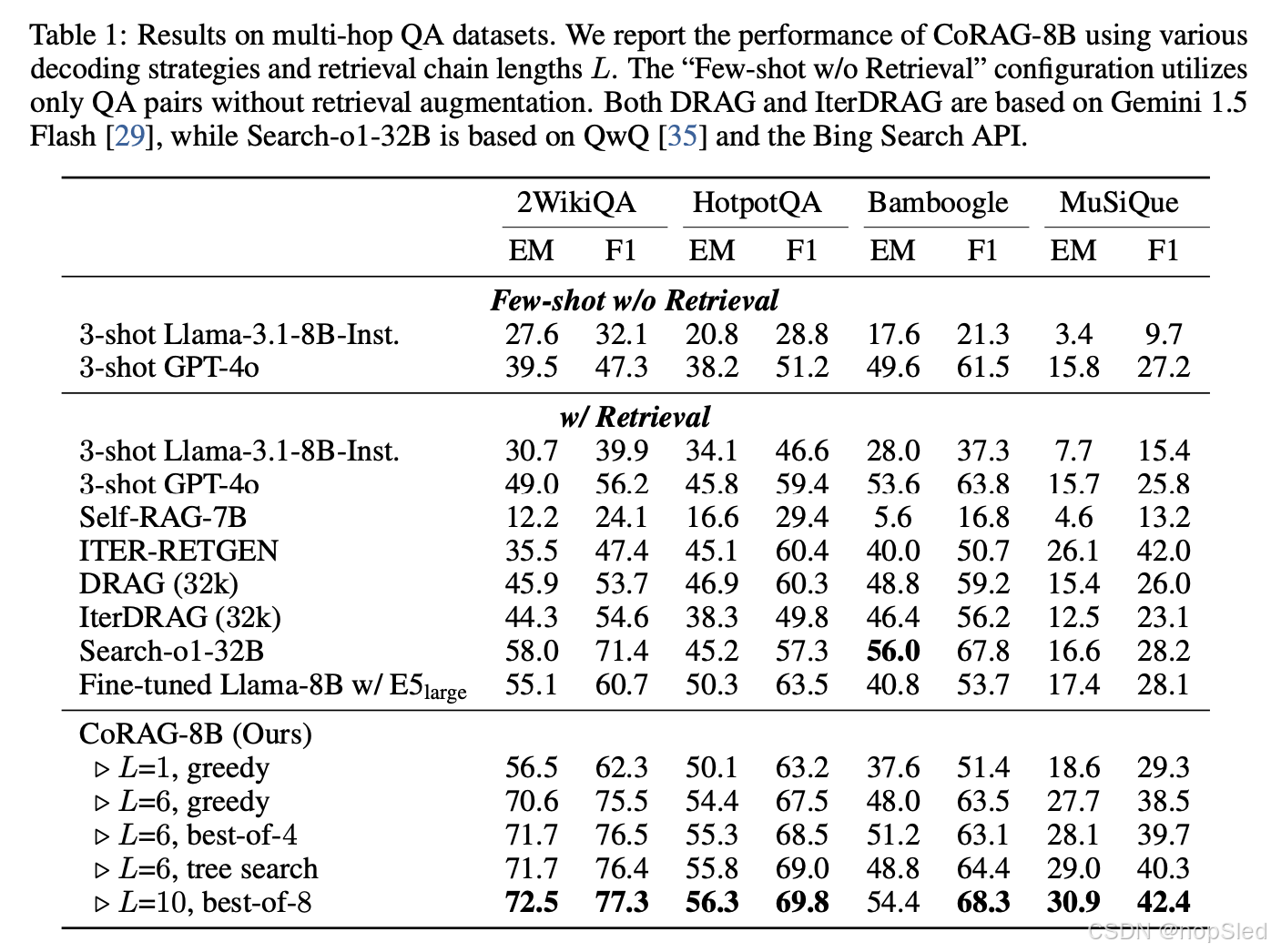


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









