






摘要
本研究提出了 ParGo,一种新的 Partial-Global 投影层,旨在连接多模态大型言模型 (MLLM) 中的视觉和语言模态。与以前依赖全局注意力投影层的工作不同,我们的 ParGo 通过整合全局和局部视图来弥合单独预训练的视觉编码器和 LLM 之间的表示差距,从而减轻对突出区域的过分强调。为了促进 ParGo 的有效训练,我们收集了一个名为 ParGoCap-1M-PT 的大型带细节字幕的图像文本数据集,该数据集包含 100 万张与高质量字幕配对的图像。在多个 MLLM 基准上进行的大量实验证明了我们的 ParGo 的有效性,突出了其在对齐视觉和语言模式方面的优势。与传统的 Q-Former 投影层相比,我们的 ParGo 在 MME 基准上实现了 259.96 的改进。此外,我们的实验表明 ParGo 明显优于其他投影层,特别是在强调细节感知能力的任务中。
1.介绍

最近的多模态大语言模型 (MLLM) 在各种任务(例如,视觉问答)中取得了显著进展。视觉语言投影层是 MLLM 中广泛使用的组件,旨在为 LLM 提供适当的视觉特征。由于其在桥接模态方面发挥的关键作用,它在最近的研究中引起了广泛关注。
先驱工作直接使用线性或多层感知器层 (MLP) 来投影视觉特征。然而,这种基于线性的投影仪很难控制提供给 LLM 视觉 token 的数量(例如,处理细粒度特征),从而导致计算成本高昂。另一系列工作采用基于全局注意的投影层,使用注意力操作将图像特征全局投影到固定数量的视觉 token。然而,这些基于全局投影的投影层导致生成的 token 集中在突出区域而忽略了更精细的细节。以图 1 中的图像为例,以前的方法往往专注于堡垒,很容易忽略顶部的两个个体。
在本文中,我们旨在构建一个视觉语言投影层,它可以为 LLM 提供更好地表示图像的视觉特征,同时使用固定数量的视觉 token 。灵感源于这样的观察:一幅图像可以用两种信息来正确描述,即全局信息代表对图像的整体理解,而多个局部信息则强调细微的细节,示例如图 1 所示。
受此启发,我们提出了一种基于部分/全局注意力机制的新型 Partial-Global projector (ParGo) (ParGo)。通过整合全局和部分视图,我们的 ParGo 有效地弥合了单独预训练的视觉编码器和 LLM 之间的表示差距,缓解了对突出区域的过分强调。此外,考虑到图像中不同部分区域之间的关系,ParGo 结合了级联部分感知块,从而实现了图像不同部分区域之间的交互。
此外,为了促进 ParGo 的有效训练,我们收集了一个名为 ParGoCap-1M-PT 的大规模带细节字幕的图像文本数据集用于预训练。大多数现有的预训练数据集通常来自互联网,包含的字幕通常很短,强调突出的视觉特征,但缺乏部分区域的详细描述。在这样的数据集上进行训练使得模型难以学习细粒度的细节。相比之下,我们的 ParGoCap-1M-PT 包含图像中多个区域的更长、更详细的描述。在两种带字幕的数据上进行预训练后,我们使用几个公开可用的指令微调数据集(例如 LLaVA-150k)将我们的模型转移到多个下游任务中。在几个基准上进行了广泛的实验,结果表明我们的 Partial-Global 投影层优于其他投影层。我们的贡献可以总结如下:
- 我们提出了一种新的部分全局投影层(ParGo),通过整合部分和全局视图,很好地对齐两个单独预训练的模型,减轻对突出区域的过分强调。
- 为了促进模态对齐,我们进一步提出了一个新的带有细节字幕的预训练数据集 ParGoCap1M-PT,其中包括 100 万张带有高质量字幕的图像。
- 在多个 MLLM 基准上进行的大量实验证明了我们提出的 ParGo 的有效性。与之前的投影层相比,我们的投影层取得了最先进的结果,尤其是在一些需要更多细节感知能力的任务中表现出色。
2.Related Work
2.1 Multi-modal Large Language Models
大语言模型 (LLM) 取得了显著进展,最近的研究将这一成功推广到更多模态,即多模态大语言模型 (MLLM)。在这些研究中,闭源研究取得了巨大进步,突出了它们在复杂任务上的高性能。相比之下,开源模型也取得了重大进展,促进了研究界的透明度和协作。先驱研究通过整合大量图像文本对建立了竞争基线。此外,最近的研究通过收集更多高质量的多模态指令,提升了各种下游任务的零样本能力。另一方面,最近的研究也侧重于细粒度理解(例如,文本识别、动作理解)。
2.2 Vision-language Projector
视觉语言投影层起着至关重要的作用,是 MLLM 中广泛使用的组件。它们旨在连接视觉特征空间和语言特征空间,可分为基于线性和基于注意力的投影层。基于线性的投影仪采用线性层将视觉编码器与语言模型 (LLM) 无缝连接。尽管基于线性的投影仪实现简单,但它们在为 LLM 生成大量视觉 token 时遇到挑战,导致计算成本高昂。另一条研究路线探索了基于注意力机制的更灵活的投影层(例如 Q-former 和 Perceiver Resampler)。这种基于注意力的方法通常会提取突出的图像特征,导致细节丢失和模型性能下降。最近的一项工作 Honeybee 也提到了类似的发现,它提出了一种 D-Abstractor,它使用可变形注意力来保留局部信息并实现卓越的性能。为了使用固定数量的视觉 token 有效地向 LLM 提供全面的信息,我们提出了部分全局投影层,它使用部分全局投影,同时提取部分和全局信息。
2.3 Multi-modal Pre-training Data
使用网络爬取的大规模图像文本数据集训练模型已成为 MLLM 最常见的策略。然而,网络爬取的数据集主要使用嘈杂且简短的字幕来呈现图像的主要特征,缺乏详细的描述。为了获得详细的描述,一些工作提供了 boxes(或 mask )级字幕,但受到 boxes 生成(基础)模型的限制。闭源 MLLM 近期取得的显著进展促使最近的研究人员考虑使用 MLLM 来合成带详细字幕的数据,以补充传统网络爬取数据集的局限性。在这项工作中,我们进一步贡献了一个带详细字幕的数据集用于预训练,旨在从数据角度增强两种模态之间的一致性。
3.方法
3.1 Overview
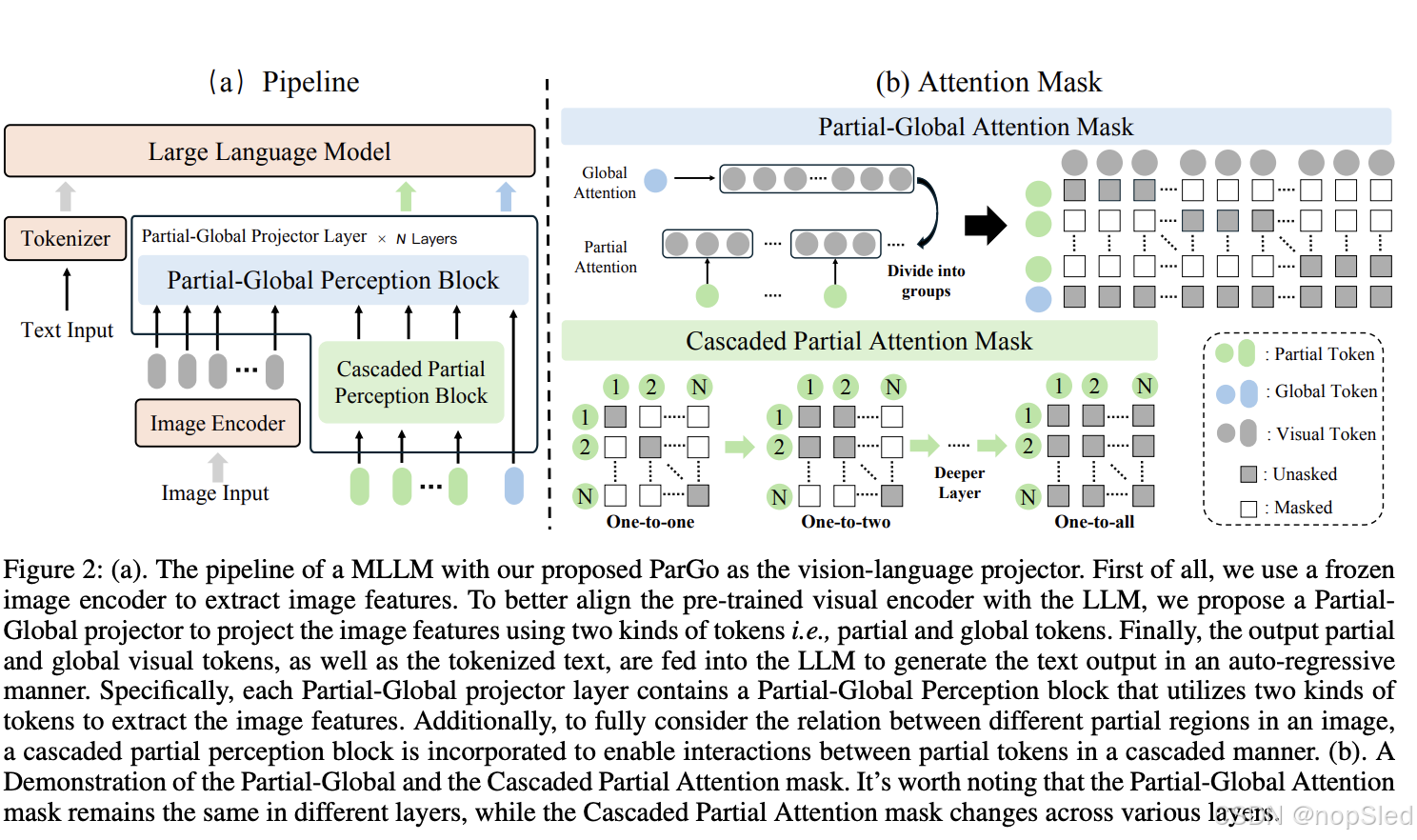
在图 2 (a) 中,我们说明了使用我们提出的 Partial-Global 投影层 (ParGo) 作为 MLLM 视觉语言投影层的流程。给定图像
I
I
I 和相关文本
T
T
T,我们首先使用冻结的图像编码器和 tokenizer 分别提取视觉特征
f
v
f_v
fv 和文本特征
f
t
f_t
ft。为了有效地对齐视觉和语言模态,我们提出了一个 Partial-Global 投影层将视觉特征投影到文本特征空间。具体来说,Partial-Global 投影层使用两种可学习的 token,从局部和全局视图投影视觉特征。随后,ParGo 的输出和的文本 token 被输入到大语言模型中以生成最终的文本输出。
3.2 Partial-Global Projector
为了更好地协调单独预训练的视觉编码器和大语言模型,我们提出了部分全局投影层(ParGo)。每个 ParGo 层主要包含两部分:即 Partial-Global Perception 块和 Cascaded Partial Perception 块,如下图所示。
Partial-Global Perception Block。首先,我们提出了一个部分全局感知块,它采用两种 token,即部分 token 和全局 token,分别来提取部分和全局信息。
具体来说,给定视觉特征
f
v
∈
R
n
v
×
c
f_v ∈\mathbb R^{n_v×c}
fv∈Rnv×c (由视觉编码器提取),我们随机初始化一定数量的全局token
q
g
∈
R
n
g
×
c
q_g ∈ \mathbb R^{n_g×c}
qg∈Rng×c 和部分token
q
p
∈
R
n
p
×
c
q_p ∈ \mathbb R^{n_p×c}
qp∈Rnp×c,其中
c
c
c 是特征维度,
n
v
,
n
g
,
n
p
n_v, n_g, n_p
nv,ng,np 分别是视觉特征、全局 token 和部分 token 的数量。这些 token 在交叉注意力层中与图像特征交互。对于交叉注意力 MASK,我们使用预定义的MASK矩阵
M
∈
R
(
n
p
+
n
g
)
×
n
v
M ∈\mathbb R^{(n_p+n_g)×n_v}
M∈R(np+ng)×nv,这确保每个部分标记仅与对应部分视觉特征交互,而全局 token 与所有视觉特征交互。每个部分 token 与视觉特征 交互的数量
n
s
n_s
ns计算如下:
n
s
=
n
v
/
n
p
,
(1)
n_s=n_v/n_p,\tag{1}
ns=nv/np,(1)
图
2
(
b
)
2(b)
2(b) 显示了 Partial-Global Perception 块中使用的 MASK 示例。直观地看,每个部分 token 只能看到图像的一部分,而全局 token 则可以看到整个图像。
Cascaded Partial Perception Block。在上述部注意力过程中,部分 token 在不同的层中看到一致的视觉token。然而,这样的过程专注于使用一个 token 来投射图像的一部分,因此可能无法充分考虑图像中不同部分区域之间的关系。因此,为了充分考虑部分图像的上下文,我们提出了一个 Cascaded Partial Perception (CPP) 块,它允许不同的部分 token 之间进行交互。
具体来说,对于每个 Partial-Global Perception 块,我们在它前面插入了一个 Cascaded Partial Perception (CPP) 模块。CPP 模块采用 masked self-attention 模块实现,以专门设计的 mask 作为核心。输入是部分 token
{
q
p
i
}
i
=
1
n
p
\{q^i_p\}^{n_p}_{i=1}
{qpi}i=1np,随着深度
l
l
l 的增加,每个部分 token 能看到的相邻 token 数量
n
v
i
s
l
(
0
≤
n
v
i
s
l
≤
n
p
)
n^l_{vis}(0 ≤ n^l_{vis} ≤ n_p)
nvisl(0≤nvisl≤np) 也呈线性增加。这个过程可以表述如下:
n
v
i
s
l
=
k
×
l
,
k
=
n
p
/
d
(2)
n^l_{vis}=k\times l,k=n_p/d\tag{2}
nvisl=k×l,k=np/d(2)
其中
l
l
l 是层的索引,np 是部分 token 的数量,
d
d
d 是 Partial-Global 投影层的数量。如图 2. (b) 所示,可视化了不同层中不同 CPP 块中的掩码的示例。
3.3 ParGoCap-1M-PT
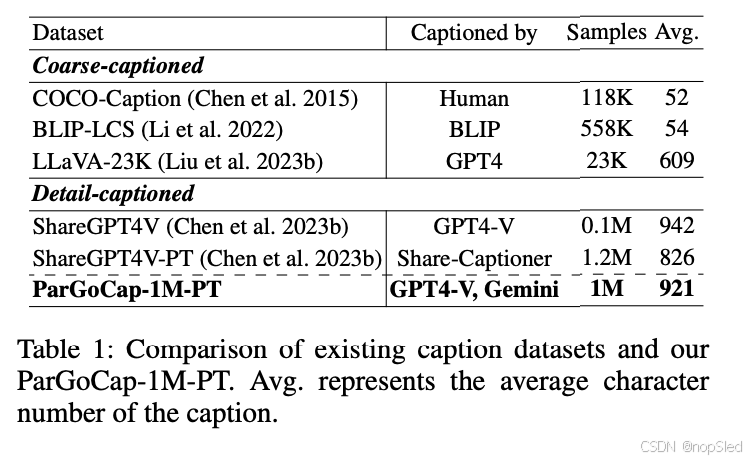
在本节中,我们重点介绍如何预训练整体模型以利用 Partial-Global 投影层的优势。现有的预训练语料库通常是粗字幕的,并从互联网上收集。这样的字幕数据很嘈杂,通常很短(平均字符数少于 100),仅描述图像的一部分。使用这种粗略的数据会阻碍两种模态之间的对齐。因此,我们使用现成的闭源 MLLM 构建了一个新的大规模细节字幕图像文本数据集,名为 ParGoCap-1MPT。表 1 比较了现有的字幕数据集和我们的 ParGoCap-1M-PT。ParGoCap-1M-PT 提供了大量高质量的详细字幕样本,这与现有数据集有所不同。数据收集流程主要包括两个步骤:
Detailed caption generation。为了便于视觉和语言特征空间之间的对齐,需要大规模和多样化的图像数据。我们首先从 Laion 数据集中随机选择大量图像。然后,为了生成能够很好地描述图像的详细字幕,我们使用功能强大的闭源 MLLM(即 GPT4-V 和 Gemini)根据指定的提示生成字幕。由于我们的目标是生成考虑到图像的部分和全局信息的字幕数据,我们设计了提示,要求 MLLM 对图像进行全局和部分描述。
Quality control。得益于现有模型的强大能力,生成的数据质量已经非常优秀。但是,由于幻觉问题,可能仍会存在一些错误数据。为了进一步筛选出高质量的数据,我们采用了一种简单但有效的质量控制方法。我们沿用前人的研究,直接使用几个模型来计算图像和生成的字幕之间的相似度。相似度较低的图像-字幕对将被丢弃。这一步过滤掉了一小部分数据,证明了我们的数据质量非常出色。有关数据集的更多详细信息,请参阅补充材料。
4.Experiment
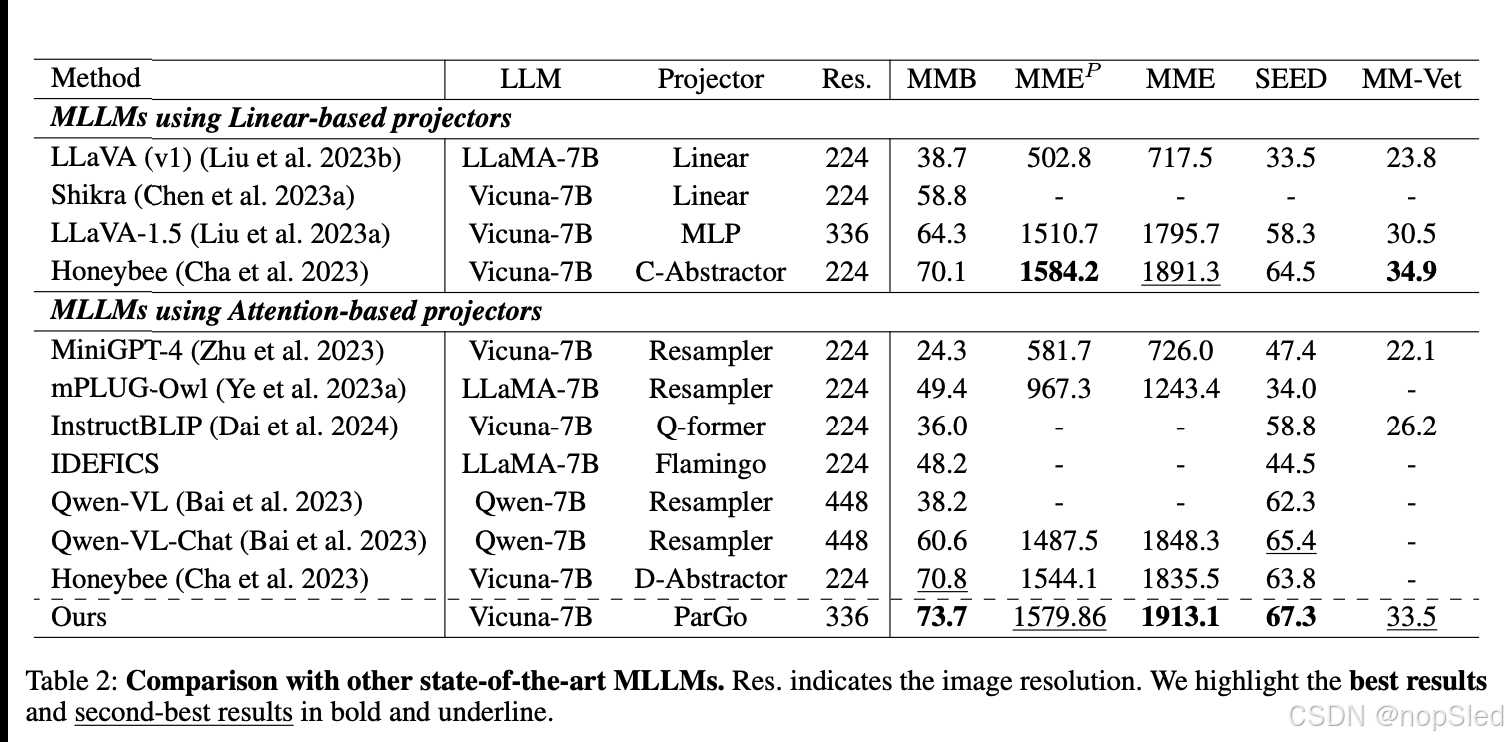


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









