






摘要
大语言模型 (LLM) 通常会在数十亿个 token 上进行预训练,但一旦有新数据可用,就必须重新开始该过程。一个更便宜、更有效的解决方案是启用这些模型的持续预训练,即使用新数据更新预训练模型,而不是从头开始重新训练它们。然而,新数据引起的分布变化通常会导致过去数据的性能下降。为了朝着高效的持续预训练迈出一步,在这项工作中,我们研究了不同预热策略的效果。我们的假设是,在新的数据集上进行训练时,必须重新增加学习率以提高计算效率。我们研究了在 Pile(上游数据,300B 个 token)上预训练的模型的预热阶段,并继续在 SlimPajama(下游数据,297B 个 token)上进行预训练,遵循线性预热和余弦衰减计划。我们在 Pythia 410M 语言模型架构上进行了所有实验,并通过验证困惑度评估性能。我们尝试了不同的预训练检查点、各种最大学习率和各种预热长度。我们的结果表明,虽然重新预热模型首先会增加上游和下游数据的损失,但从长远来看,它会提高下游性能,优于从头开始训练的模型——即使对于大型下游数据集也是如此。
1.介绍
大型预训练模型已使视觉和语言领域的许多下游任务的性能得到大幅提升。然而,训练这些基础模型的成本过高。现有研究旨在通过实现低成本超参数优化或提供在给定计算预算下最大化性能的指导方针来降低大规模模型开发的成本。然而,这些研究假设模型将从头开始训练。随着可用于预训练的数据量不断增长,新的和改进的数据集(例如 RedPajama 和 SlimPajama)将不断涌现。从业者是否应该始终结合现有数据集(例如 Pile)并从头开始训练以获得最佳性能?这样做很快就会变得成本过高,并且无法利用现有的预训练模型。
我们的方法通过继续在新数据上对现有模型进行预训练,从而避免了完全重新训练的需要。我们将此称为“持续预训练”,目标是在保持先前数据损失较低的同时,最大限度地减少新数据的损失。持续预训练是一项关键挑战,因为它可能导致灾难性的遗忘。此外,潜在的长序列训练阶段可能会使常见的持续学习技术(如回放或正则化)计算效率不够高。在这种情况下,限制遗忘的一个简单且(从计算成本的角度来看)可扩展的解决方案是(仅)在每次有新数据可用时逐步降低学习率。然而,这种解决方案是有限的,因为如果训练阶段的数量变多,反复降低学习率最终会导致学习率变得太小。
在这项工作中,我们通过研究如何重新增加小的学习率来继续在新的数据上训练预训练语言模型,朝着高效的持续预训练迈出了一步。我们将此称为重新预热模型。重新预热模型应该可以避免学习率消失,从而提高学习效率。我们研究了 Pythia 410M 模型的预热策略,该模型具有各种数据量、最大学习率和不同的预训练检查点。这将使最初在大型数据集上训练的模型能够从在较新的大型数据集上恢复训练中受益,而无需从头开始重新训练。为了模拟这种设置,我们将初始预训练数据集固定为 Pile,将较新的数据集固定为 SlimPajama。我们希望这可以指导现有 LLM 适应未来的新数据集。
我们的结果表明:
- 逐步增加学习率来进行热身是没有必要的,但直接从最大学习率开始会导致损失(混乱阶段,又称稳定差距)最初出现大幅飙升,而之后不会产生任何后果。
- 调整最大学习率有助于权衡上游和下游性能;增加最大学习率可以更好地适应下游数据集(SlimPajama),而较小的学习率则可以在上游数据集(Pile)上保留更多的性能。
- 使用最新的预训练检查点进行持续的预训练可以提高性能。
2. Setup
在我们的设置中,上游(或预训练)数据集是 Pile。下游(或微调)数据集是 SlimPajama。SlimPajama 是 RedPajama 的广泛去重版本,它基于 LLama 数据集构建。在这项工作中,我们交替使用“微调”和下游持续预训练。然而,在我们的持续预训练设置中,我们注意到下游数据集与之前的预训练数据集规模相当(即非常大,与许多微调数据集不同)。
SlimPajama 数据集的构建来源与 Pile 类似,但数据量更大。因此,在下游预训练期间可能会重复一些上游数据。我们的实验设置与 (Ash & Adams, 2020) 的设置相当,他们首先在数据集的一半样本上训练分类器,然后在所有样本上对其进行微调。他们表明,图像分类的热启动具有挑战性。使用在 Pile 上预训练的模型并继续在 SlimPajama 上进行预训练,我们遵循因果语言建模的类似设置。
Datasets。我们使用与 Black et al. (2022) 相同权重的 Pile 进行验证。我们对 SlimPajama 数据集进行打乱和随机采样,以形成 ∼297B token 训练数据集和 ∼316M token 验证数据集。我们不使用回放。我们使用与 (Black et al., 2022) 相同的tokenizer,该标记器专门在 Pile 上进行训练。
Model。我们使用在 Pile 上预训练的 410M Pythia,即 GPT-NeoX 模型。我们不使用 flash 注意力机制。
Hyperparameters。我们使用 AdamW 优化器,其中
β
1
=
0.9
,
β
2
=
0.95
,
ϵ
=
1
0
−
8
β_1 = 0.9, β_2 = 0.95, ϵ = 10^{−8}
β1=0.9,β2=0.95,ϵ=10−8,权重衰减为 0.1。最大学习率在我们的实验中有所不同
{
1.5
⋅
1
0
−
4
,
3
⋅
1
0
−
4
,
6
⋅
1
0
−
4
}
\{1.5 · 10^{−4},3 · 10^{−4},6 · 10^{−4}\}
{1.5⋅10−4,3⋅10−4,6⋅10−4}。我们使用余弦学习率衰减到最小 0.1 · MaxLr。所有预热长度均基于完整的下游数据集大小(297B 个 token)计算。我们注意到我们的余弦衰减计划在 240B 个 token 时达到最小学习率,此后保持不变。我们将梯度裁剪设置为 1.0。训练以半精度(FP16)进行,没有 dropout。
3.相关工作
Large Language Models。LLM 通常使用 Adam(例如 GPT3、BLOOM、Gopher、Pythia)或 AdamW(例如 Chinchilla、LLaMA)进行训练。在所有上述模型中,学习率计划都包括预热,然后余弦衰减至最大学习率的 10%。
Unsupervised Continual Learning。在本文中,我们研究了 LLM 持续预训练的各种预热策略。持续预训练使用与持续自监督训练类似的训练目标。自监督预训练也在视觉数据集中进行了研究,用于图像生成或表示学习。在语言中,持续预训练以领域自适应预训练的名义进行了研究,其中新数据集来自新领域。另一种设置是在不同时间点生成不同的数据集。在我们的设置中,该场景更接近领域自适应预训练,因为我们不考虑数据的时间性。
Monitoring Learning Rate for Continual Training of Language Models。在持续学习 (CL) 中,模型是在一系列数据集上进行训练的。因此,数据不是独立的且分布不均等的,这可能导致模型失去可塑性或遗忘。在这种情况下,特别监控学习率计划可能会有所帮助。在语言模型的 CL 中,已经评估了不同的方法:恒定学习率、逐步降低或预热然后降低。
然而,据我们所知,目前还没有现有的研究专门研究在大语言模型的持续预训练背景下热身阶段的影响。
4.Continual Warm-up
4.1. How long to warm up?
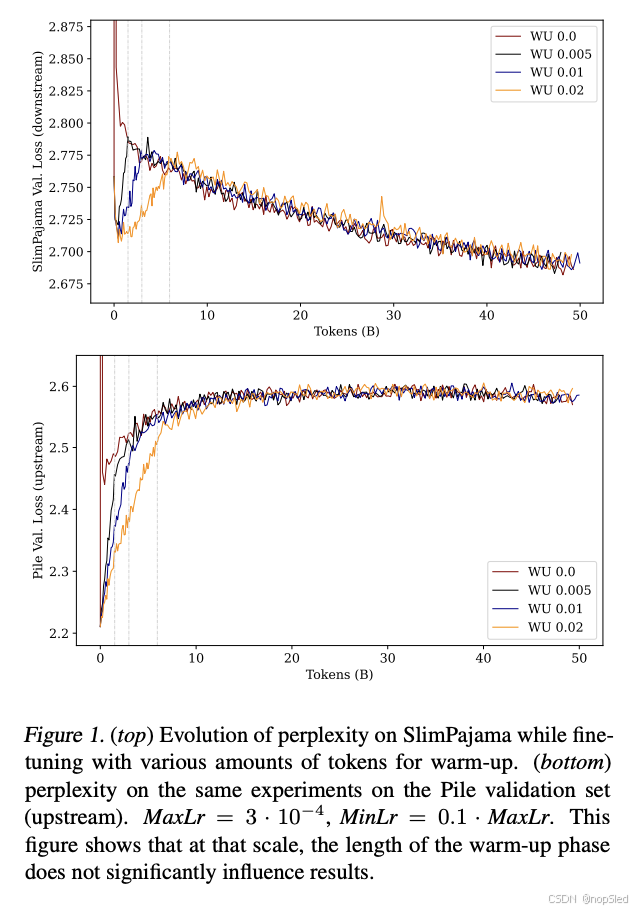
在文献中,通常最多对 1% 进行预热。在本实验中,我们调查了模型是否对该超参数敏感。
Setup。我们针对 297B 个 token 的调度尝试了不同的预热长度:0%、0.5%、1% 和 2% 的数据,并测量了前 50B 个 token 后的性能。从另一个角度来看,我们可以将此实验视为对不同数量的数据运行 1% 的预热。我们假设,对更多迭代进行预热可以实现更平稳的过渡,并随后提高性能。
Results。图 1 给出了该实验的结果。结果表明,用于预热学习率的数据量不会显著影响下游任务(学习)或上游任务(遗忘)的困惑度。这些结果推翻了我们的假设,即使用更多 token 进行预热可以平滑过渡,并表明线性预热在这种情况下毫无用处。然而,在没有任何渐进式预热的情况下训练的模型会经历一个初始的“混沌阶段”,导致损失在训练的前几次迭代中激增,这种现象也称为稳定性差距。

4.2. How high to warm up?
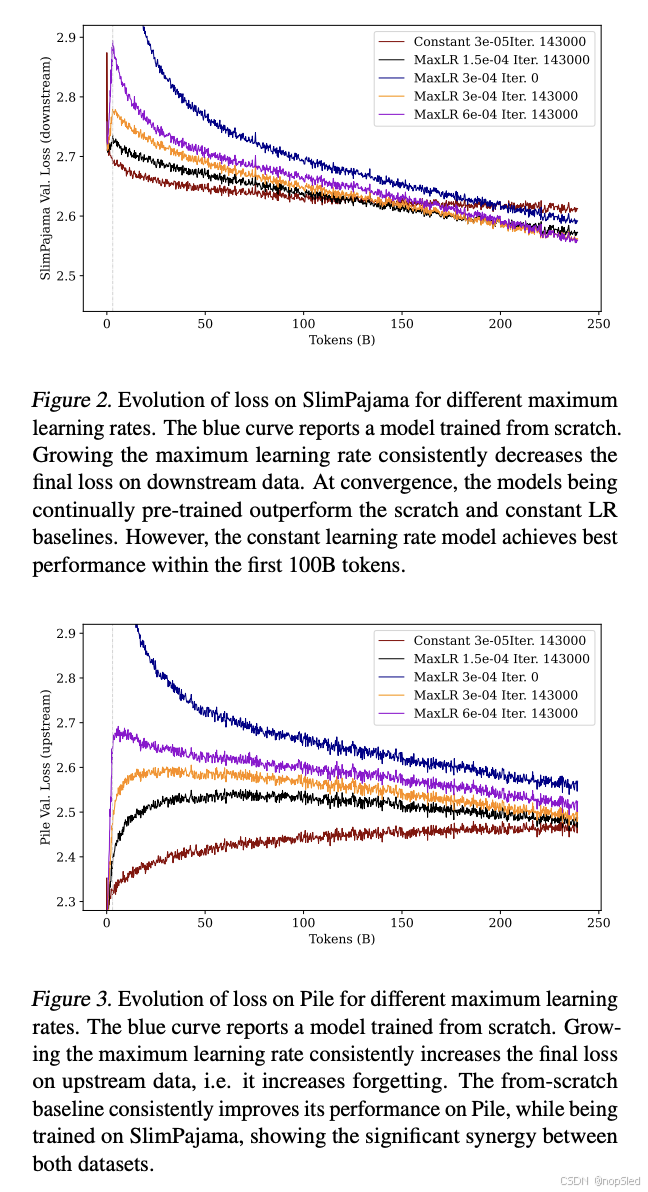
重新调整学习率的一个目的是实现计算效率高的持续预训练。学习率太小可能会导致下游数据集的学习效率低下,而学习率太大可能会导致上游数据集的灾难性遗忘。重新调整学习率的一个重要方面是决定将其提高到多高。因此,在这个实验中,我们改变了最大学习率来评估其对性能的影响。
Setup。我们将预热阶段的长度固定为训练数据的默认数量 1%,并改变最大学习率。我们尝试了用于预训练 Pythia 410M 的默认值
3
⋅
1
0
−
4
,
1.5
⋅
1
0
−
4
,
6
⋅
1
0
−
4
3 · 10^{−4}, 1.5 · 10^{−4}, 6 · 10^{−4}
3⋅10−4,1.5⋅10−4,6⋅10−4。对于预热后余弦衰减阶段,我们将最终学习率设置为最大学习率的 10%。我们使用的学习率计划在 240B 个 token 时衰减到最小学习率,此后保持不变。运行报告到 240B 个 token 结束(衰减期结束)。
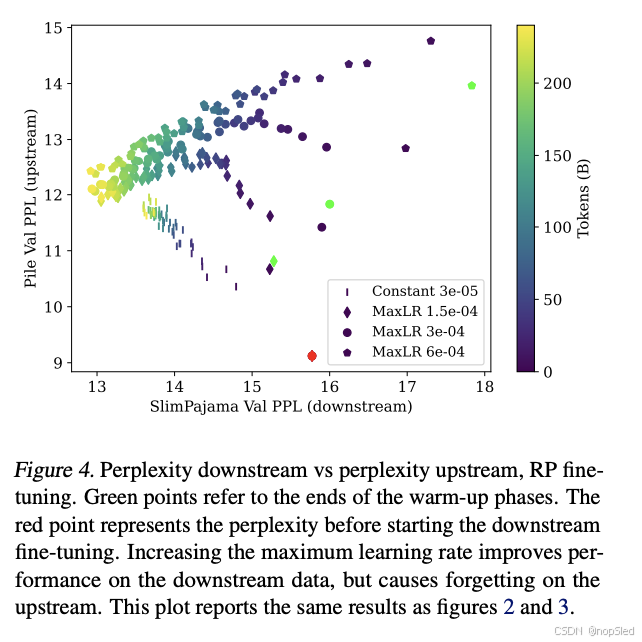
Results。图 2、3 和 4 提供了该实验的结果。我们在训练结束时观察到,较大的最大学习率会提高下游数据的性能,但会损害上游数据的性能。相反,较小的最大学习率会提高上游数据的性能,同时限制对下游数据的适应,从而导致性能下降。这些发现表明,改变最大学习率是权衡下游和上游性能的有效方法。此外,我们观察到一个总体趋势:对 SlimPajama 进行微调会导致模型忘记在 Pile 上学到的内容,从而导致 Pile 验证困惑度增加。最后,我们注意到,对从恒定学习率训练的模型采用早期停止(类似于传统的微调)是一种经济的方式,可以适应新的数据分布,同时保持上游数据集的强大性能。
4.3. Comparing with from Scratch Training
在这个实验中,我们想要比较微调的模型和从头训练的模型。

4.4. Re-warming on the same data

4.5. Evaluating Earlier Checkpoints



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









