






摘要
尽管通用大语言模型 (LLM) 性能卓越,但它们在特定领域(例如低数据量和知识密集型)的许多应用仍然面临重大挑战。有监督微调 (SFT)——通过在小型标注数据集上进一步训练通用 LLM,使其适应特定任务或领域——已在开发特定领域 LLM 方面展现出强大的能力。然而,现有的 SFT 数据主要由问答 (Q&A) 对组成,这对 LLM 理解问答背后知识的关联性和逻辑性提出了严峻挑战。为了应对这一挑战,我们提出了一个概念灵活且通用的框架来提升 SFT,即 Knowledge Graph-Driven Supervised Fine-Tuning (KG-SF)。KG-SFT 的核心思想是通过结构化知识图谱为每个问答对生成高质量的解释,以增强 LLM 的知识理解和操作能力。具体而言,KG-SFT 由三个组件组成:Extractor、Generator 和 Detector。对于给定的问答对,(i) Extractor 首先识别问答对中的实体,并从外部知识图谱 (KG) 中提取相关的推理子图;(ii) Generator 利用这些推理子图生成相应的流畅解释;(iii) 最后,Detector 对这些解释进行句子级知识冲突检测,以保证解释的可靠性。KG-SFT 专注于生成高质量的解释,以提升问答对的质量,这为补充现有的数据增强方法提供了一个有前景的方向。在 15 个不同领域和 6 种不同语言上进行的大量实验证明了 KG-SFT 的有效性,在低数据场景下准确率提升高达 18.1%,平均提升 8.7%。
1.INTRODUCTION
大语言模型 (LLM),例如 GPT-4、LlaMA 3 和 Claude 3,已在众多领域展现出卓越的性能和令人印象深刻的多功能性。然而,将 LLM 应用于低数据量和知识密集型领域(例如,特定的医疗领域或具有特定协议的私有数据)仍然具有挑战性。
近年来,大量的研究致力于提升通用LLM在特定领域的性能。一种创新的训练范式——有监督微调(SFT)——已成为一种新的趋势,并展现出卓越的性能,能够提升通用LLM在某些领域的性能和可控性。SFT的核心思想是通过在标注的数据集上持续训练,使预训练的LLM适应特定任务,这使得模型能够优化其参数,从而提升与任务相关的特征的性能。然而,对于某些领域,知识密集型和低数据量领域的现成SFT数据通常稀缺,而创建高质量SFT数据的过程需要大量的人力和专业知识,这限制了该领域LLM构建的广泛应用。丰富SFT数据中问答内容数量并提升LLM性能的典型方法是数据增强。目前仍使用传统的自然语言处理方法,例如简易数据增强(EDA),包括同义词替换、字符替换、随机交换和反向翻译。最近,一些研究尝试使用 LLM 来扩展 SFT 数据集。AugGPT 利用 LLM(例如 ChatGPT)来重新表述问题。GPT3Mix 通过少量提示,促使 LLM 生成与 SFT 数据中类似的问题,从而增强了 SFT 数据。
尽管这些增强方法在扩展 SFT 数据量方面取得了显著成效,但原生的 SFT 数据增强方法仍然面临一个重大挑战,这可能会阻碍 LLM 进行领域特定微调——SFT 数据底层知识之间缺乏关联性和逻辑性。现有的 SFT 数据主要以问答形式构建,因此 SFT 过程中的 LLM 仅获取问答的表面模式(例如输出空间和格式),而无法理解问答对底层知识的关联性和逻辑性。例如,对于这个问题:持续发烧和体重增加哪个不是癌症的常见症状?答案是:体重增加。这涉及多个知识点,例如“癌症会导致身体抵抗力下降”、“抵抗力下降通常会导致持续发烧”、“癌细胞会消耗大量能量”以及“能量消耗会导致体重减轻”。预训练中知识的碎片化使得LLM在回答问题时难以回忆起进行逻辑推理所需的相关知识。因此,即使使用充足的SFT数据进行了大量训练,经过微调的LLM仍然无法有效地操纵预训练数据中的知识,尤其是在回忆、推理和迁移方面。
因此,本文旨在回答这个问题:我们能否不仅关注SFT训练数据的数量,更关注其质量,即揭示SFT数据背后知识的关联性和逻辑性?以之前的问答对为例,它涉及的知识关联性和逻辑性如下:“癌症-可能导致->抵抗力下降-可能导致->持续发烧”,以及“癌细胞-可能导致->能量消耗-可能导致->体重减轻”。这与知识图谱(KG)中一系列三元组(即子图)中的内容非常吻合。我们探索如何引入知识图谱来生成高质量的解释,从而提升每个问答对的理解。因此,我们提出了一种新方法,即知识图谱增强监督微调(KG-SFT),它可以阐明知识的相关性和逻辑性,以增强 LLM 的知识操作(例如知识回忆、推理和转移)能力。
KG-SFT 是一个新的框架,能够有效地生成逻辑性强、流畅且可信的解释。具体来说,这三个特点与 KG-SFT 的三个组成部分相一致:
- Extractor 集成外部开源知识图谱(例如 UMLS),用于识别问答对中的实体。Extractor 还会检索它们之间的多跳推理子图,以揭示问答对底层知识的关联性和逻辑性。
- Generator 使用图结构重要性评分算法 HIST 对推理子图中的实体和关系进行评分。生成器选择得分较高的部分作为 LLM 的重要内容,以便 LLM 能够为问答对生成流畅的解释草稿。
- Detector 将解释草稿按句子级别拆分,并检测其与推理子图之间潜在的知识冲突。检测器还会重新提示以重新生成冲突的解释。
在 15 个不同领域和 6 种不同语言上进行的大量实验证明了 KG-SFT 的有效性,在低数据场景下,准确率最高提升了 18.1%,平均提升了 8.7%。事实上,鉴于许多实际的低数据领域都非常重视准确率,平均 8.7% 的提升可能代表着巨大的经济潜力。我们还进行了知识操作实验,以评估该模型在召回率、推理能力和迁移能力方面的提升。KG-SFT 也可以作为一个有效的即插即用模块,与数量增强方法相结合。
2.RELATED WORK
2.1 TEXT DATA AUGMENTATION
数据增强是自然语言处理领域的经典研究方向。传统的数据增强技术主要侧重于字符和单词级别的增强。例如,EDA 利用随机插入、随机交换、随机删除和同义词替换等方法来丰富数据多样性。近年来,基于语言模型的技术已经实现了句子甚至文档级别的数据增强,其中基于前沿的 LLM 的方法展现出强大的竞争优势。一个值得关注的例子是 AugGPT,它利用 LLM(例如 ChatGPT)对 SFT 数据中的问题进行复述,丰富问答的表达形式。此外,GPT3Mix 也通过少样本提示(few-shot prompts)来促使 LLM 生成与 SFT 数据类似的问题,从而增强 SFT 数据。
2.2 KNOWLEDGE GRAPH ENHANCED LLMS
知识图谱 (KG) 凭借其在结构化知识表示方面的优势,被认为是一项有望弥补大语言模型 (LLM) 在推理和可解释性方面局限性的有力技术。近期研究主要致力于将知识图谱中的结构化知识转化为文本提示,以增强 LLM 的问答能力。例如,Think-on-Graph (ToG) 利用知识图谱上的迭代集束搜索来提升推理能力;KGR 则利用来自知识图谱的已验证事实陈述自主地改进 LLM 的响应;而 KAPING 则通过将知识图谱检索到的事实添加到 LLM 的输入中来增强零样本问答能力。检索增强方法主要在推理阶段为 LLM 提供事实知识。相比之下,我们的 KG-SFT 则专注于通过生成高质量的训练数据来阐明知识之间的关联性和逻辑性,从而显著增强 LLM 的知识操作能力。
3.PRELIMINARIES
3.1 BM25 ALGORITHM
对于给定文档 d d d 和包含关键字 q 1 , q 2 , . . . , q n q_1, q_2, ..., q_n q1,q2,...,qn 的问题 q q q, d d d 相对于 q q q 的 BM25 得分计算如下: B M 25 ( d , q ) = ∑ i = 1 n I D F ( q i ) ⋅ f ( q i , d ) ⋅ ( k 1 + 1 ) f ( q i , d ) + k 1 ⋅ ( 1 − b + b ⋅ l e n ( d ) a v g d l ) BM25(d, q) = \sum^n_{i=1} IDF(q_i) · \frac{f(q_i,d)·(k_1+1)}{f(q_i,d)+k_1·(1−b+b·\frac{len(d)}{avgdl})} BM25(d,q)=∑i=1nIDF(qi)⋅f(qi,d)+k1⋅(1−b+b⋅avgdllen(d))f(qi,d)⋅(k1+1),其中 f ( q i , d ) f(q_i, d) f(qi,d) 是 d d d 中 q i q_i qi 的词频, l e n ( d ) len(d) len(d) 是文档 d d d 的长度(以词为单位), a v g d l avgdl avgdl 是提取文档所在文本集合中的平均文档长度, k 1 k_1 k1 和 b b b 是自由参数,通常选择,不失一般性,如 k1 = 1.2 到 2.0 和 b = 0.75, I D F ( q i ) IDF(q_i) IDF(qi) 是 q i q_i qi 在文档集合中的逆文档频率,定义为: I D F ( q i ) = l o g N − n ( q i ) + 0.5 n ( q i ) + 0.5 IDF(q_i) = log \frac{N−n(q_i)+0.5}{n(q_i)+0.5} IDF(qi)=logn(qi)+0.5N−n(qi)+0.5,其中 N N N 是集合中的文档总数, n ( q i ) n(q_i) n(qi) 是包含 q i q_i qi 的文档数。
3.2 HITS ALGORITHM
Hyperlink-Induced Topic Search (HITS),也称为“Hubs and Authorities”算法,是一种用于对网页进行评级的算法。在知识图谱中,实体可以被视为页面,其中 hub 是指向许多其他实体(authorities)的实体,而 authorities 是被许多 hub 指向的实体。该迭代算法根据每个实体之间的关系更新 hub 和 authority 得分,其关键方程为: h ( e i ) = ∑ e j ∈ O ( e i ) a ( e j ) h(e_i) = \sum_{e_j∈O(e_i)}a(e_j) h(ei)=∑ej∈O(ei)a(ej) 和 a ( e i ) = ∑ e j ∈ I ( e i ) h ( e j ) a(e_i) = \sum_{e_j∈I(e_i)}h(e_j) a(ei)=∑ej∈I(ei)h(ej),其中 h ( e i ) h(e_i) h(ei) 和 a ( e i ) a(e_i) a(ei) 分别是实体 e i e_i ei 的 hub 和 authority 得分, O ( e i ) O(e_i) O(ei) 是 e i e_i ei 指向的实体集合(出链), I ( e i ) I(e_i) I(ei) 是指向 e i e_i ei 的实体集合(入链)。每次迭代后,得分都会在所有实体上进行归一化。我们将最终 authority 得分和 hub 得分的平均值称为 HITS 得分。
4.METHOD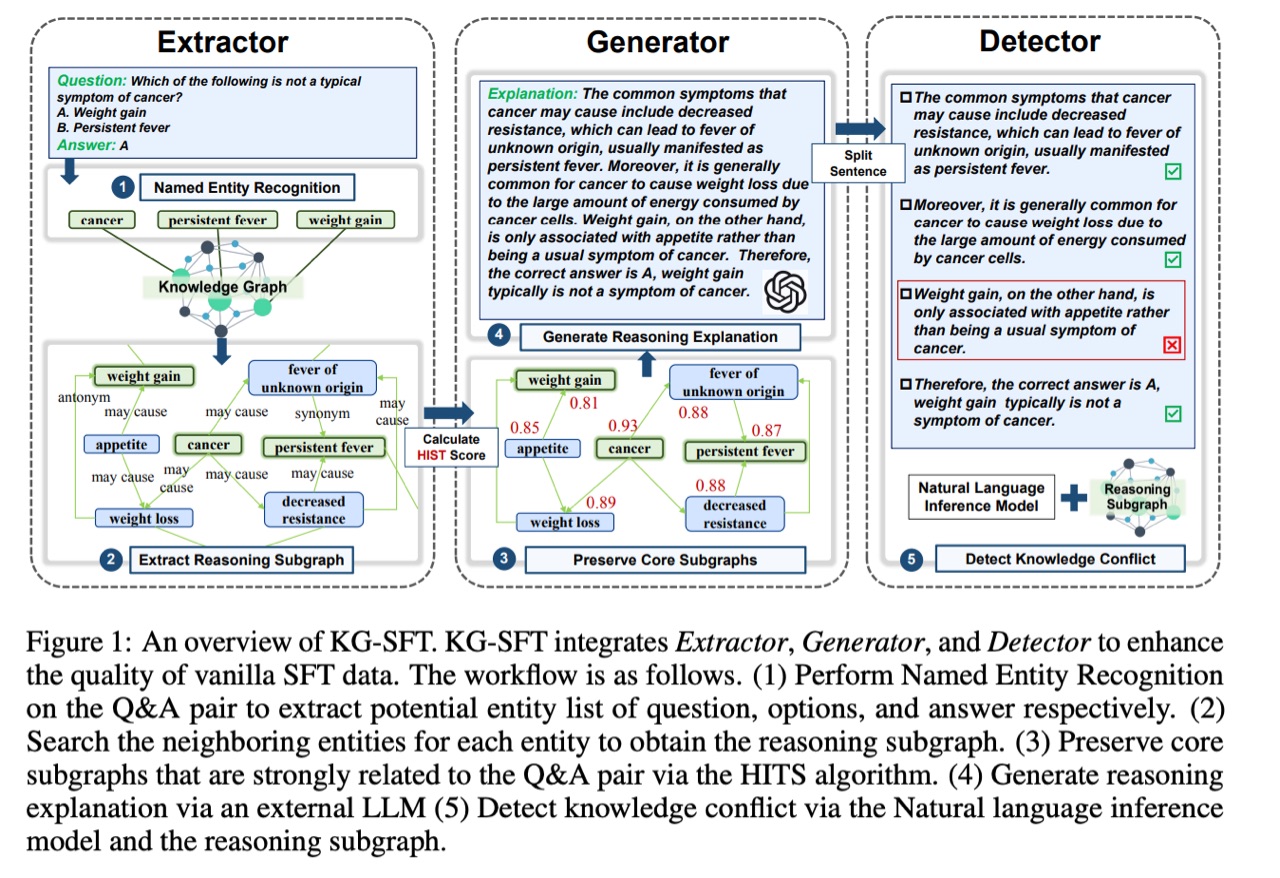
我们提出了 KG-SFT 框架,旨在通过揭示 SFT 数据背后的关联性和知识逻辑来提升其质量。具体而言,KG-SFT 由三个组件组成:提取器 (Extractor)、生成器 (Generator) 和检测器 (Detector)。KG-SFT 的概览如图 1 所示。
4.1 EXTRACTOR
Extractor 首先根据问答对,在知识图谱中导出相关的推理子图,以揭示知识的底层关联和逻辑。具体而言,对于给定的问答对,Extractor 的工作流程如下:
- 提取器首先对问题、选项和答案进行命名实体识别 (NER),分别导出问题、选项和答案的实体列表。关于 NER 模型,我们利用了开源知识图谱提供的现有 NER 工具,特别是利用了 UMLS 的 Metamap 等工具。
- 为了挖掘问答对中知识之间的关联性,在获取实体列表后,提取器会在外部知识图谱中丰富这些实体的邻居。我们进一步应用现成的 BM25 算法,根据三元组(实体、关系、邻居)与问答文本的相关性对其进行排序,并将排名靠前(默认 20 个)的相关三元组保留为候选。
- 为了挖掘问答对背后知识之间的综合逻辑,Extractor最终提取出三类推理路径:从问题实体到问题实体,从选项实体到选项实体,从问题实体到答案实体。
通过对从邻居子图和推理路径获得的三元组进行去重和合并,我们可以得到一个三元组列表来表示推理子图。对于给定的问答对“以下哪一项不是癌症的典型症状?”,其选项为“A. 体重增加”,“B. 持续发烧”,正确答案为“B. 持续发烧”。首先,提取器进行命名实体识别 (NER),导出实体列表问题 = [癌症]、实体列表选项 = [体重增加,持续发烧] 和实体列表答案 = [持续发烧]。然后,提取器丰富这些实体的邻居。例如,对于“癌症”,提取器丰富了高度相关的三元组,例如 (癌症,可能导致,体重减轻) 和 (癌症,可能导致,原因不明的发烧)。最后,提取器检索推理路径,例如 (癌症,可能导致,抵抗力下降) 之后是 (抵抗力下降,可能导致,持续发烧)。最后将三元组组合起来,形成推理子图的最终三元组列表。
4.2 GENERATOR
在提取推理子图后,生成器会应用 LLM 为给定的问答创建解释,并将问题背后的结构化知识和逻辑转换为自然语言文本格式。生成器会使用现成的超链接诱导主题搜索 (HITS) 算法来筛选推理子图中的重要内容。
具体来说,生成器首先通过 HITS 算法计算推理子图中实体的 HIST 得分,该算法依赖于基于图结构迭代更新初始得分。需要注意的是,为了查找与问答相关的内容,当实体出现在问答对中时,我们会为其分配更高的初始得分;而当实体未出现在问答对中时,其他实体将获得较低的得分。然后,生成器选择按 HIST 得分排名靠前(默认为 10)的邻近子图和推理路径作为 LLM(例如 ChatGPT)的输入,以创建解释草稿。所使用的提示指示 LLM 根据提供的问题、答案和三元组生成清晰的解释。有关详细信息,请参阅附录 A.4。
将 HITS 算法应用于上述推理子图,我们观察到“癌症”作为一个实体表现出较高的权威性,因为它与“可能导致”在多条中心路径上紧密关联,尤其在关系链(癌症,可能导致,原因不明的发烧)中凸显出来。同时,“持续发烧”作为答案实体,在路径(抵抗力下降,可能导致,持续发烧)中获得了显著的中心性。
生成器在收到这些核心三元组后,会生成反映问题与答案之间逻辑关系的解释草稿:“癌症的常见症状包括抵抗力下降,从而导致不明原因的发热,通常表现为持续发热。此外,由于癌细胞消耗大量能量,癌症通常会导致体重下降。而体重增加仅与食欲有关,而非癌症的常见症状。因此,正确答案为A,体重增加通常不是癌症的症状。” 由此,生成器以更流畅、更清晰的方式传达了底层医学知识。
4.3 DETECTOR
在为每个问答对生成解释草稿后,Detector 会使用推理图中的三元组进一步检查这些解释,以确保其正确性。Detector 旨在增强生成解释的正确性,并最大限度地减少 LLM 在生成过程中可能出现的误导。具体而言,为了生成解释草稿,检测流程如下:
- 将解释草稿分割成句子,然后将其与最初获得的实体列表进行匹配,形成匹配的比较三元组。
- 将匹配的比较三元组和分段后的句子解释输入到自然语言推理 (NLI) 模型中,以评估知识冲突。考虑到 NLI 模型的输入长度和能力限制,我们将比较三元组(每组五个)与句子组合,直接输入到现成的、最先进的自然语言推理 (NLI) 模型 DeBERTa 中,以评估知识冲突问题。
- 如果检测到句子存在知识冲突,则使用后续删除标签标记该句子。如果发现过多(默认 30%)句子存在知识冲突,则重新提示机制将引导 LLM 重新生成解释。重新提示机制指示模型参考已标记的包含知识冲突的句子,并重新生成新的正确解释。详情请参阅附录 A.4。
例如,对于“另一方面,体重增加仅与食欲有关,而不是癌症的常见症状。”结合三元组(食欲,可能导致,体重增加)输入到DeBERTa中,获得的知识冲突概率大于预定义的阈值,因此将被标记为知识冲突。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









