




摘要
FP8 训练已成为一种提升训练效率的有前景的方法。现有框架通过将 FP8 计算应用于线性层来加速训练,同时保持优化器状态和激活的精度更高,但这无法完全优化内存使用。本文介绍了 COAT(Compressing Optimizer States and Activations for FP8 Training),这是一种新的 FP8 训练框架,旨在显著减少训练大模型时的内存占用。COAT 通过两项关键创新解决了当前的局限性:(1) 动态范围扩展,使优化器状态分布与 FP8 表示范围更加一致,从而减少量化误差;(2) 混合粒度激活量化,结合使用每个张量和每个组的量化策略来优化激活内存。实验表明,与 BF16 相比,COAT 有效地将端到端训练内存占用减少了 1.54 倍,同时在大语言模型预训练和微调以及视觉语言模型训练等各种任务中实现了几乎无损的性能。与 BF16 相比,COAT 的端到端训练加速比提升了 1.43 倍,性能与 TransformerEngine 的加速比相当甚至更高。COAT 能够在更少的 GPU 上高效地对大模型进行全参数训练,并有助于在分布式训练环境中将batch size 翻倍,为扩展大规模模型训练提供了切实可行的解决方案。代码可从 https://github.com/NVlabs/COAT 获取。
1.介绍
基础模型 (FM),例如大语言模型 (LLM) 和视觉语言模型 (VLM),在推理、理解和摘要等各种任务上取得了重大突破。然而,训练此类模型通常包含数十亿个参数,需要大量的计算资源和内存。这带来了巨大的挑战,使得这些基础模型的训练非常具有挑战性。
低精度训练已成为一种颇具前景的提升FM训练效率的方法。通过将深度神经网络中使用的张量量化为较低精度,低精度训练可以有效加快训练速度并减少内存占用。目前,BF16训练是最流行的低精度方法,并被广泛应用于DeepSpeed 和Megatron-LM 等大规模训练框架中。
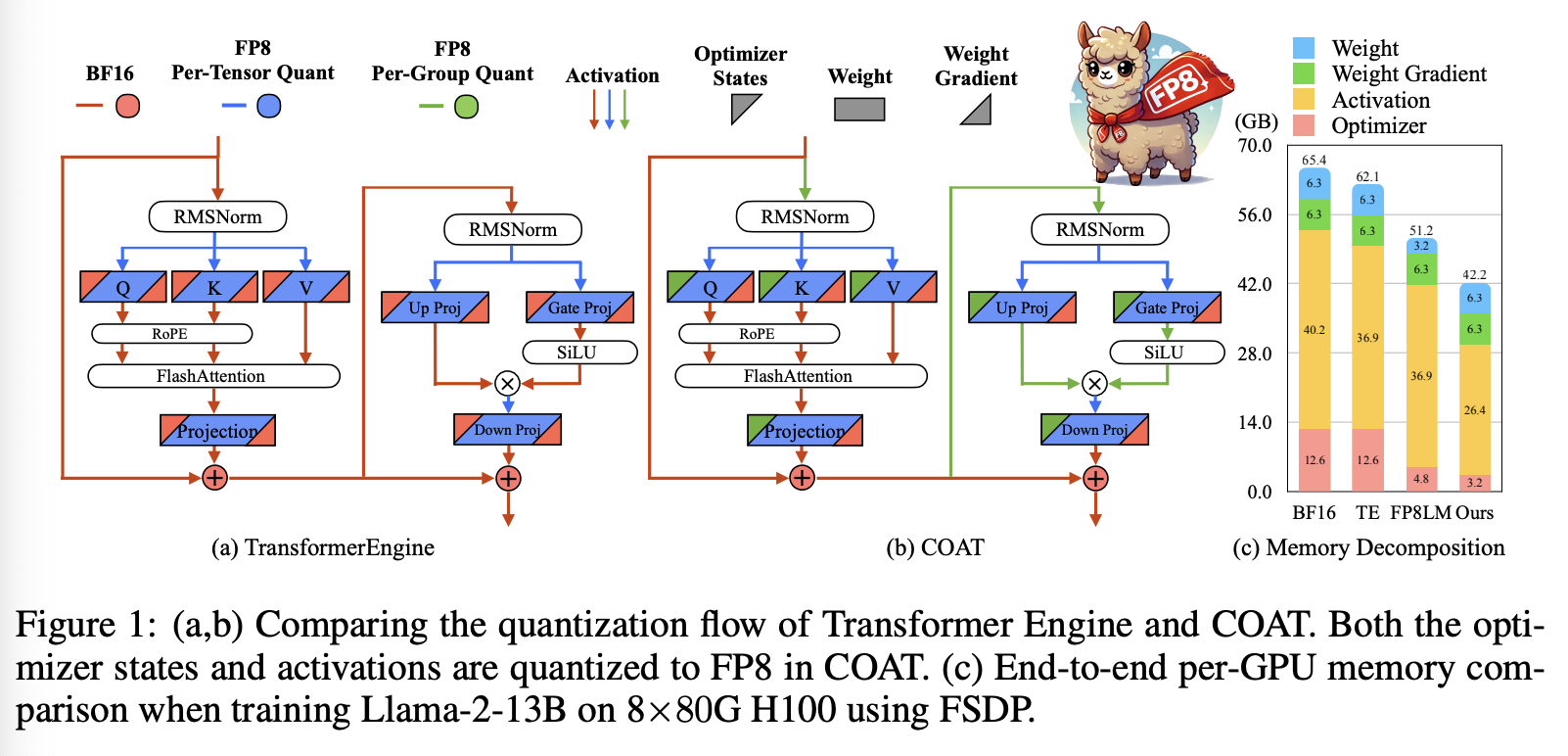
随着 Nvidia H100 GPU 的问世,FP8 训练正在成为下一代低精度技术。与 BF16 相比,FP8 训练有望 (1) 实现速度翻倍,(2) 内存占用减半。为了实现实际加速,Transformer Engine 以 FP8 精度执行矩阵乘法,从而加快训练速度。通过将优化器状态、梯度、权重和激活降低到较低精度,可以进一步优化 Transformer Engine 的内存占用。如图 1 所示,FP8-LM 通过将梯度、权重主副本和一阶动量进一步量化到 FP8 中,从而进一步提升了内存效率。这减少了内存和通信开销,并在一定程度上提高了内存效率。然而,它们并未解决激活的内存消耗问题,仍然保留了优化器二阶动量的高精度特性。当使用 ZeRO 或 FSDP 将优化器、梯度和权重分片到多个 GPU 上时,激活的内存问题变得更加关键。此外,二阶动量比一阶动量对量化更敏感,激活的较大峰值也使其难以量化到 FP8。这种潜在的精度下降使得它们错失了进一步优化内存的关键机会。
在本研究中,我们提出了 COAT:压缩优化器状态和激活,以实现内存高效的 FP8 训练,以解决上述问题。COAT 通过将优化器状态和激活量化为 FP8 格式,显著降低了整体内存占用。对于优化器状态,我们观察到 FP8 格式的表示范围在量化时未得到充分利用,如图 2(a) 所示。为了解决这个问题,我们引入了一种新的动态范围扩展方法,该方法可以调整优化器状态的分布,使其更好地适应 FP8 范围,从而最大限度地减少量化误差。对于激活,我们提出了混合粒度激活量化,以实现高效准确的量化。我们对非线性层应用细粒度量化,对线性层应用逐张量量化。对于矩阵乘法,逐张量量化效率更高,更适合 TensorCores,而细粒度量化则有助于保持准确性。这两种方法在解决高内存消耗问题的同时,将性能损失降至最低。我们在图 1(b) 中提供了 COAT 的概述以供演示。
我们展示了 COAT 在 LLM 预训练、LLM 微调和 VLM 训练等一系列任务上的精准性能。COAT 在所有这些任务上均实现了几乎无损的性能。在效率方面,与 BF16 相比,COAT 实现了 1.54 倍的端到端内存节省,并在 Llama 7B、13B 和 30B 模型上实现了 1.43 倍的端到端训练速度提升。COAT 还在所有实际分布式训练设置中将批次大小翻倍,这对于更高的加速比和对更长上下文长度的支持至关重要,从而提高大规模模型的训练效率。
2.RELATED WORK
Low-precision Training。低精度训练已成为现代深度学习中的一项重要技术,能够降低计算成本和内存需求。FP16(半精度)训练是当今最流行的低精度方法。它引入了损失缩放来解决 FP16 表示范围较窄的问题。BF16 训练改进了这种方法,因为 BF16 具有更大的表示范围,并且在大规模训练中更加稳定。在这些方法中,前向和后向传递以 FP16 或 BF16 精度计算,而主权重、梯度和优化器则以 FP32 精度存储。
FP8 训练旨在进一步提升这些效率。随着 Nvidia Hopper GPU 架构的推出,FP8 正逐渐成为下一代低精度训练的实用数据类型。Nvidia 的 Transformer Engine (TE) 是首个专为 FP8 混合精度训练设计的框架,它采用 FP8 Tensorcore 进行线性层计算。FP8-LM 将 FP8 量化扩展到梯度和优化器状态,进一步提升了训练吞吐量。然而,它们未能降低使用 FP8 进行反向传播时存储的激活的内存占用,并且在 FP16 中留下了二阶动量,从而限制了 FP8 内存优势的充分发挥。
Memory Efficient Optimizers。虽然 32 bit 优化器状态已被广泛采用,但已有多项研究致力于通过量化来减少优化器状态的内存占用。8 bit Adam 引入了一种名为动态指数 (DE) 的新型数据格式用于量化,但这种新数据格式的采用限制了其灵活性。4 bit 优化器通过解决零点问题,将优化器量化的极限进一步提升至 4 位,但仅限于微调任务。FP8-LM 将一阶动量量化至 FP8,同时将二阶动量保留在 FP16,这限制了整体内存的节省。(Fishman et al., 2024) 发现二阶动量对量化更为敏感,并建议使用 E5M2 格式对其进行量化。
除了量化之外,还有其他方法旨在减少优化器状态的内存占用,例如低秩分解和仅存储一阶动量的优化器简化。这些方法与我们的方法正交。
Activation Quantization。Cai et al. (2020) 近期的研究主要集中在通过激活量化来减少神经网络训练过程中的内存占用。ActNN 引入了一个使用随机量化的 2 位激活压缩训练框架,将激活的内存占用减少了 12 倍。GACT 扩展了这一概念,使其支持各种机器学习任务和架构,为 CNN、Transformer 和 GNN 带来了高达 8.1 倍的激活内存减少。然而,这些方法主要侧重于卷积网络,并不适用于 LLM。AQ-SGD 提出在流水线并行训练中压缩激活的变化值而非直接值,以减少流水线并行设置下的通信开销。 Few-Bit Backward 量化使用最优分段常数近似对非线性激活函数进行量化,以在保持收敛性的同时减少内存占用。Jetfire 提出了 INT8 数据流来量化线性层和非线性层的激活函数,以减少内存占用,并且适用于语言模型预训练。
Bit-Width Under-Utilization。Balance Quantization 以百分位数递归地划分参数,以减少量化误差。DDSQ 根据不同的梯度分布动态更改量化参数。N2UQ 通过学习输入阈值和非均匀映射来提高量化精度。这些方法意识到量化中的动态范围问题,并提出了更具自适应性、分布感知的技术,可以保留全精度中包含的细微信息。它们有一个共同的基本目标,即扩展低精度神经网络表示的有效动态范围。这些方法采用可学习的非均匀量化查找表,而我们的工作依赖于自然的 FP8 数据格式。
3.PRELIMINARIES
FP8 Quantization。量化将高精度张量压缩为低精度张量,以降低精度和减小表示范围,从而实现加速并节省内存占用。FP8 格式包含两种编码 - E4M3 和 E5M2。E4M3 具有更高的精度,而 E5M2 具有更大的表示范围。我们将 E4M3 的最小值和最大值定义为 ∆minE4M3=2−9∆^{E4M3}_{min} = 2^{−9}∆minE4M3=2−9 和 ∆maxE4M3=448∆^{E4M3}_{max} = 448∆maxE4M3=448,而 E5M2 的最小值和最大值分别为 ∆minE5M2=2−16∆^{E5M2}_{min} = 2^{−16}∆minE5M2=2−16 和 ∆maxE5M2=57344∆^{E5M2}_{max} = 57344∆maxE5M2=57344。为了将 FP32 张量 X 量化为 E4M3 精度,我们使用量化器 Q(⋅)Q(·)Q(⋅) 将张量映射到 FP8 的表示范围。此过程可以表述为
XFP8,SX=Q(XFP32),where XFP8=⌈XFP32SX⌋,SX=max(∣XFP32∣)∆maxE4M3X_{FP8},S_{X}=Q(X_{FP32}), where~X_{FP8}=⌈\frac{X_{FP32}}{S_X}⌋,S_X=\frac{max(|X_{FP32}|)}{∆^{E4M3}_{max}}XFP8,SX=Q(XFP32),where XFP8=⌈SXXFP32⌋,SX=∆maxE4M3max(∣XFP32∣)
其中 SXS_XSX 是缩放因子,⌈⋅⌋⌈·⌋⌈⋅⌋ 表示舍入到最近值。量化为 E5M2 遵循类似的过程,我们仅将 ∆maxE4M3∆^{E4M3}_{max}∆maxE4M3 替换为 ∆maxE5M2∆^{E5M2}_{max}∆maxE5M2。为了将量化张量映射回 FP32 精度,反量化运算 DQ(⋅)DQ(·)DQ(⋅) 可以表示为 XFP32=DQ(XFP8,SX)=SXXFP8X_{FP32} = DQ(X_{FP8}, S_X) = S_XX_{FP8}XFP32=DQ(XFP8,SX)=SXXFP8。
Optimizer Update Rule。优化器在深度学习中被广泛用于参数更新。最常见的基于梯度的优化器是 Adam/AdamW,它利用一阶动量 mmm 和二阶动量 vvv 来实现更好的收敛。AdamW 在时刻 ttt 的更新规则可以表述为:
mt=β1mt−1+(1−β1)gt−1vt=β2vt−1+(1−β2)gt−12m^=mt1−β1tv^t=vt1−β2twt+1=wt−η(m^tv^t+ϵ+λwt)(1)\begin{array}{cc} m_t=\beta_1m_{t-1}+(1-\beta_1)g_{t-1} & v_t=\beta_2v_{t-1}+(1-\beta_2)g^2_{t-1}\\ \hat m=\frac{m_t}{1-\beta^t_1} & \hat v_t=\frac{v_t}{1-\beta^t_2}\\ w_{t+1}=w_t-η(\frac{\hat m_t}{\sqrt{\hat v_t}+ϵ}+\lambda w_t) \end{array}\tag{1}mt=β1mt−1+(1−β1)gt−1m^=1−β1tmtwt+1=wt−η(v^t+ϵm^t+λwt)vt=β2vt−1+(1−β2)gt−12v^t=1−β2tvt(1)
其中 mtm_tmt 为一阶动量,vtv_tvt 为二阶动量,gtg_tgt 为梯度,β1β_1β1 和 β2β_2β2 为 AdamW 的 beta 值,ηηη 为学习率,λλλ 为权重衰减,ϵϵϵ 用于防止 NaN 或 Inf。
为了执行优化器状态量化,我们沿用先前的研究方法,对一阶和二阶动量采用按组量化。每个连续 GGG 个元素组成一个组(G 定义为组大小),每个组使用各自的统计数据进行独立量化。优化器状态以 FP8 精度存储,而其缩放因子以 BF16 精度存储。在 FSDP 或 ZeRO-3 中,与优化器状态相关的统计数据(例如缩放因子)在 GPU 之间不同步,因为每个 GPU 都维护自己的优化器状态分片。更多详细信息,请参阅附录 A。
4.DYNAMIC RANGE EXPANSION FOR ACCURATE OPTIMIZER QUANTIZATION
在后续章节中,我们将解释 COAT 如何利用 FP8 量化来实现内存高效的 FP8 训练,同时又不影响准确性。第 4 节重点介绍优化器状态量化,第 5 节则讨论激活量化。
4.1 UNDERSTANDING THE ISSUE OF CURRENT OPTIMIZER STATES QUANTIZATION METHOD
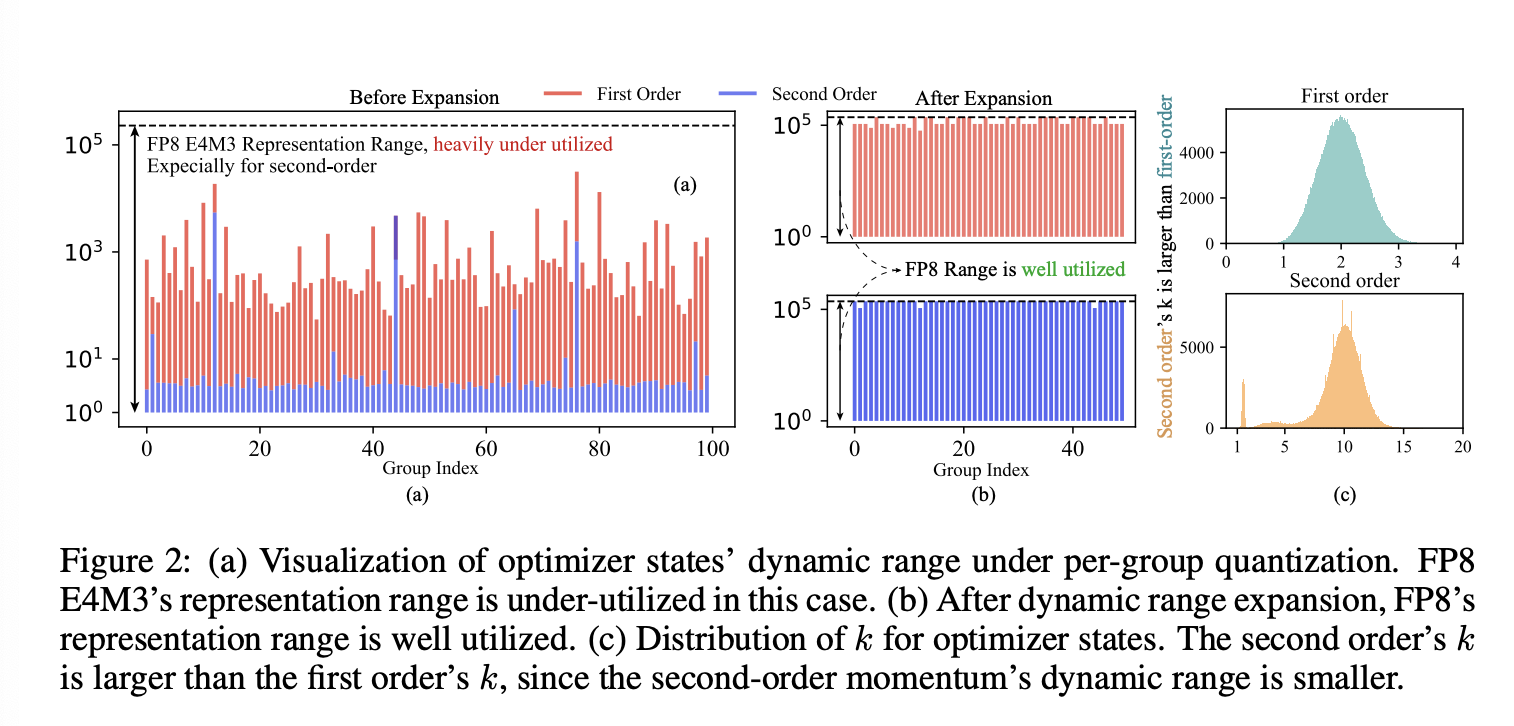
在逐组量化下,我们发现当前量化方法的一个显著缺陷是,它们不能充分利用FP8的表示范围,从而导致较大的量化误差。以E4M3数据格式为例,E4M3的最大可表示值与最小可表示值之比为 ∆maxE4M3/∆minE4M3=448÷1512=229376≈2×105∆^{E4M3}_{max} /∆^{E4M3}_{min} = 448÷\frac{1}{512} = 229376 ≈ 2×10^5∆maxE4M3/∆minE4M3=448÷5121=229376≈2×105。
因此,对于量化组 XXX,如果我们要充分利用 FP8 的 256 个可表示值,我们希望量化组 XXX 的动态范围能够覆盖 ∆minE4M3∆^{E4M3}_{min}∆minE4M3 和 ∆maxE4M3∆^{E4M3}_{max}∆maxE4M3 之间的整个跨度。
为了更正式地表达,我们将动态范围定义为量化组 XXX 中最大绝对值与最小绝对值之间的比率:
Definition 1 (dynamic range)。给定一个由 G 个实数组成的集合 X={x1,x2,...,xG}X = \{x_1, x_2, . . . , x_G\}X={x1,x2,...,xG},动态范围 R 定义为:
RX=max(∣x1∣,∣x2∣,..,∣xG∣)min(∣x1∣,∣x2∣,...,∣xG∣),\mathcal R_X=\frac{max(|x_1|,|x_2|,..,|x_G|)}{min(|x_1|,|x_2|,...,|x_G|)},RX=min(∣x1∣,∣x2∣,...,∣xG∣)max(∣x1∣,∣x2∣,..,∣xG∣),
其中 ∣⋅∣|·|∣⋅∣ 表示绝对值。
也就是说,E4M3 的动态范围是 RE4M3=448×512=229376≈2×105\mathcal R_{E4M3} = 448 × 512 = 229376 ≈ 2 × 10^5RE4M3=448×512=229376≈2×105。然而在实践中,优化器状态内的许多量化组无法有效地映射如此宽范围内的值。我们观察到优化器状态非常稀疏,只有不到 1% 的值具有大幅度,而大多数值相对较小且紧密聚集。大多数组表现出较低的动态范围,因为大值太少。如图 2(a) 所示,一阶动量的动态范围通常小于 1e41e41e4,二阶动量的动态范围通常小于 1e11e11e1——两者都远低于 FP8 的可用范围。因此,FP8 的很大一部分表示容量被浪费,导致大的量化误差。

















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









