






摘要
在非常困难的学习任务上,深度神经网络(DNNs)模型能达到非常好的效果。虽然DNNs在大量有标记的训练数据中有很好的效果,但它们不能用于将一个序列映射到另一个序列。在这篇论文中,我们提出了一种通用的端到端序列学习方法,它对序列结构做出了最小化的假设。我们的方法使用了一个多层的长短期记忆网络(LSTM)将输入序列映射成一个固定维度的向量,然后再用另外一个深层LSTM将这个向量解码成目标序列。我们的主要结果是,在WMT’14数据集的英语到法语翻译任务中,LSTM产生的翻译结果在整个测试集上获得了34.8的BLEU分数,其中LSTM的BLEU分数在词汇量不足时受到惩罚。此外,LSTM在长句子上并没有表现较差性能。为了进行比较,在同样的数据集上,一个基于短语的SMT系统达到了33.3的BLEU分数。当我们使用LSTM重新调整上述SMT系统产生的1000个假设时,其BLEU分数增加到36.5,接近此任务的先前最佳结果。LSTM还学习到了对单词顺序较为敏感,而且对积极和消极语言相对不变的合理的短语和句子表示。最终,我们发现通过颠倒原句子中的单词顺序能够显著提升LSTM的性能,因为这样做会在源语句和目标句子之间引入许多短期依赖关系,这使得优化问题更容易。
1.介绍
深度神经网络(DNNs)是一种非常有效的机器学习模型,其在诸如语音识别(speech recognition)和视觉对象识别(visual object recognition)这类非常困难的任务中能够表现出很好的性能。DNNs功能强大,因为它们能在有限的步长内执行任意并行计算。DNNs功能的一个令人惊讶的例子是它们只使用2个二次大小的隐藏层对N个N位数进行排序的能力。因此,尽管神经网络与传统的统计模型相似,他们能学习更复杂的计算。此外,只要有标记的训练数据具有足够多的信息来指定网络参数,就可以使用有监督的反向传播算法训练大型DNNs。因此,如果存在一个参数集能够使大型DNNs达到很好的效果,有监督的反向传播算法就能够找到这个参数并解决相应问题。
尽管DNN具有灵活性和强大的功能,但它只能应用于输入和目标可以使用固定维数向量进行合理编码的问题。这是一个非常显著的限制,因为许多使用序列才能最好解决的问题中,其序列长度是预先不知道的。例如,语音识别和机器翻译都是序列化问题。同样,问题回答也可以被视为将表示问题的单词序列映射到表示答案的单词序列。因此很清楚,学习将序列映射到序列的领域无关( domain-independent)的方法将是很有用的。
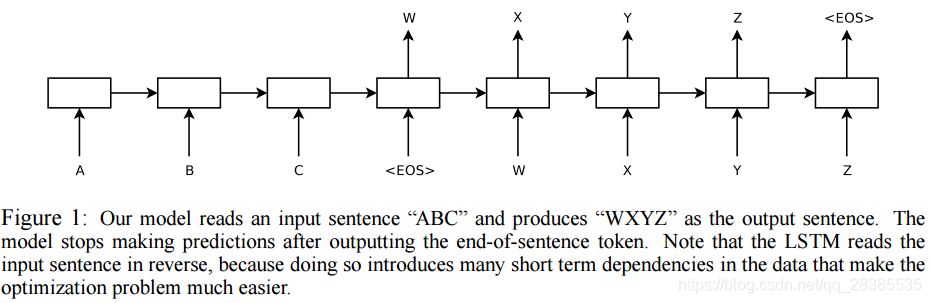
序列为DNNs的使用提出了一个挑战,因为DNNs要求输入和输出的维度都是已知的和固定的。在这篇论文中,我们将展示长短期记忆网络(LSTM)结构在序列到序列问题中的应用。其思想是,通过使用一个LSTM来读取输入序列,为了获得最大固定维度的向量表示(即最终的隐藏态),每一时刻读取一次,然后使用另外一个LSTM从该向量中提取出输出序列(如图1)。对于第二个LSTM来说,除了它是以输入序列作为条件以外,它是一个循环神经网络语言模型。LSTM在具有长时依赖的数据上具有很好的学习能力,这使得在考虑输入及其相应输出之间的时间关系的应用中,LSTM是一种自然而然的选择。
存在许多使用神经网络来解决通用的序列到序列的学习问题的方法。我们的方法与Kalchbrenner和Blunsom提出的类似,他们第一个提出了将整个输入句子映射成向量,也与Cho等人类似,尽管后者仅仅是重新定义基于短语的系统产生的假设。Graves引入了一种新颖的可微分注意机制,允许神经网络专注于他们输入的不同部分,并且这个想法的良好变体成功地应用于由Bahdanau等人提出的机器翻译中。链接序列分类(Connectionist Sequence Classification)是另外一种使用神经网络将序列映射到序列的新的技术,但它假设输入和输出之间存在单调对齐。
这篇文章的工作成果如下。通过在具有5层LSTM的解码器上使用一个从左到右的集束搜索(beam search)来获取翻译结果(这个模型具有384M的参数,隐藏态维度为8000维),在WMT‘14的英语到法语的翻译任务上,我们获得了34.81的BLEU分数。这是目前为止使用大型神经网络进行直接翻译最好的结果。为了进行比较,一个统计机器翻译(SMT)在这个数据集上的baseline的BLEU分数是33.30。在具有80K词汇的LSTM上能够达到34.81的分数,但是当一个单词不存在于这个词汇库当中时,分数会降低。这些结果展示了一个相对未优化的小词汇神经网络架构,有很大的改进空间,且优于基于短语的SMT系统。
最后,我们使用LSTM来重新评估同一任务上公开可用的1000个最佳SMT baseline列表,获得了36.5的BLEU分数,这提高了3.2个评分点,这接近此任务的先前最佳公布结果(37.0)。
令人惊讶的是,尽管最近有其他使用相同网络架构的研究人员的相关经验,LSTM并没有受到长时依赖的影响。我们之所以能够在长句子上做得很好,因为我们颠倒了源句中的单词顺序,而不是训练和测试集中的目标句子。通过这样做,我们引入了许多短期依赖关系,使优化问题变得更加简单(参见第2节和第3.3节)。因此,SGD可以学习长句子无误的LSTMs。翻转源句中单词的简单技巧是这项工作的关键技术贡献之一。
LSTM一个非常有用的属性是它能够将一个可变长度的输入句子映射成一个固定维度的向量表示。鉴于翻译倾向于对源句的释义,翻译目标鼓励LSTM找到捕捉其含义的句子表示,因为具有相似含义的句子彼此接近,而不同的句子意义将是远的。定性评估支持这种说法,表明我们的模型知道单词顺序,并且对积极和消极的语音是相当不变的。
2.模型
循环神经网络(RNN)是针对序列的前向神经网络的通用模型。在给定一个输入序列
(
x
1
,
.
.
.
,
x
T
)
(x_1,...,x_T)
(x1,...,xT)时,一个标准的RNN通过迭代如下的公式来计算一个输出序列
(
y
1
,
.
.
.
y
T
)
(y_1,...y_T)
(y1,...yT):
h
t
=
s
i
g
m
(
W
h
x
x
t
+
W
h
h
h
t
−
1
)
h_t=sigm(W^{hx}x_t+W^{hh}h_{t-1})
ht=sigm(Whxxt+Whhht−1)
y
t
=
W
y
h
h
t
y_t=W^{yh}h_t
yt=Wyhht
只要提前知道输入输出之间的对齐,RNN就可以轻松地将序列映射到序列。然而,目前尚不清楚如何将RNN应用于其输入和输出序列具有不同长度且具有复杂和非单调关系的问题。
对于一个通用的序列学习来说,最简单的策略是使用RNN将输入序列映射成一个固定大小的向量,然后再使用另外一个RNN将向量映射成目标序列。尽管其在原则上能够有效,因为提供给了RNN所有相关信息,但是由于序列的长时依赖问题,RNNs是很难训练的(如图1)。然而,长短期记忆网络(LSTM)能够解决这个问题,因此一个LSTM也许能够用于这个网络结构中。
LSTM的目标是用于估计条件概率
p
(
y
1
,
.
.
.
,
y
T
′
∣
x
1
,
.
.
.
,
x
T
)
p(y_1,...,y_{T'}|x_1,...,x_T)
p(y1,...,yT′∣x1,...,xT),其中
(
x
1
,
.
.
.
,
x
T
)
(x_1,...,x_T)
(x1,...,xT)是输入序列,
(
y
1
,
.
.
.
,
y
T
′
)
(y_1,...,y_{T'})
(y1,...,yT′)是相对应的输出序列,其长度
T
′
T'
T′不一定等于
T
T
T。LSTM首先根据输入序列
(
x
1
,
.
.
.
,
x
T
)
(x_1,...,x_T)
(x1,...,xT)获得LSTM最后一个隐藏态的具有固定维度的向量
v
v
v,然后再通过以向量
v
v
v作为一个LSTM-LM的初始状态来计算
(
y
1
,
.
.
.
,
y
T
′
)
(y_1,...,y_{T'})
(y1,...,yT′)的概率:
p
(
y
1
,
.
.
.
,
y
T
′
∣
x
1
,
.
.
.
,
x
T
)
=
∏
t
=
1
T
′
p
(
y
t
∣
v
,
y
1
,
.
.
.
,
y
t
−
1
)
(
1
)
p(y_1,...,y_{T'}|x_1,...,x_T)=\prod_{t=1}^{T'}p(y_t|v,y_1,...,y_{t-1})\qquad(1)
p(y1,...,yT′∣x1,...,xT)=t=1∏T′p(yt∣v,y1,...,yt−1)(1)
在这个等式中,每一个概率分布
p
(
y
t
∣
v
,
y
1
,
.
.
.
,
y
t
−
1
)
p(y_t|v,y_1,...,y_{t-1})
p(yt∣v,y1,...,yt−1)由所有词汇的softmax表示。需要注意的是我们要求每一个句子的末尾都使用一个特殊的句子结束符
“
<
E
O
S
>
”
“<EOS>”
“<EOS>”,这能够使模型去定义一个所有可能长度的句子的分布。所有的技巧都在图1列出,图中展示了LSTM计算了
“
A
"
,
“
B
"
,
“
C
"
,
“
<
E
O
S
>
"
“A",“B",“C",“<EOS>"
“A",“B",“C",“<EOS>"的表示,然后使用这个表示去计算
“
W
"
,
“
X
"
,
“
Y
"
,
“
Z
"
,
“
<
E
O
S
>
"
“W",“X",“Y",“Z",“<EOS>"
“W",“X",“Y",“Z",“<EOS>"的概率。
在三个不同的方面,我们实际的模型有所区别于其他的模型:
(1)我们使用了两个不同的LSTMs:一个用于输入序列,另一个用于输出序列,因为这样做在忽略计算成本的同时增加模型参数的数量,并且可以自然地同时在多个语言对上训练LSTM。
(2)其次,我们发现深层LSTM明显优于浅层LSTM,因此我们选择了一个四层LSTM。
(3)我们发现颠倒输入句子的单词顺序是非常有价值的。例如,并不将句子
a
,
b
,
c
a,b,c
a,b,c映射成
α
,
β
,
γ
\alpha,\beta,\gamma
α,β,γ,而是将
c
,
b
,
a
c,b,a
c,b,a映射成
α
,
β
,
γ
\alpha,\beta,\gamma
α,β,γ。这样,
a
a
a非常靠近
α
α
α,
b
b
b非常接近
β
β
β,依此类推,这使得SGD很容易在输入和输出之间“建立通信”。 我们发现这种简单的数据转换可以大大提高LSTM的性能。














 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









