






上面的三种方法总的来说是基于自增思想的,而接下来就介绍比较著名的雪花算法-snowflake。
我们可以换个角度来对分布式ID进行思考,只要能让负责生成分布式ID的每台机器在每毫秒内生成不一样的ID就行了。
snowflake是twitter开源的分布式ID生成算法,是一种算法,所以它和上面的三种生成分布式ID机制不太一样,它不依赖数据库。
核心思想是:分布式ID固定是一个long型的数字,一个long型占8个字节,也就是64个bit,原始snowflake算法中对于bit的分配如下图:
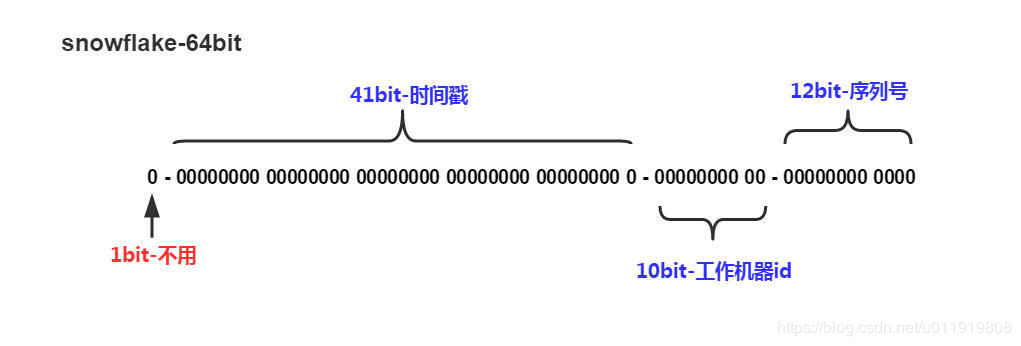
雪花算法
- 第一个bit位是标识部分,在java中由于long的最高位是符号位,正数是0,负数是1,一般生成的ID为正数,所以固定为0。
- 时间戳部分占41bit,这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间),这样可以使产生的ID从更小值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
- 工作机器id占10bit,这里比较灵活,比如,可以使用前5位作为数据中心机房标识,后5位作为单机房机器标识,可以部署1024个节点。
- 序列号部分占12bit,支持同一毫秒内同一个节点可以生成4096个ID
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
snowflake算法实现起来并不难,提供一个github上用java实现的:github.com/beyondfengy…
在大厂里,其实并没有直接使用snowflake,而是进行了改造,因为snowflake算法中最难实践的就是工作机器id,原始的snowflake算法需要人工去为每台机器去指定一个机器id,并配置在某个地方从而让snowflake从此处获取机器id。
但是在大厂里,机器是很多的,人力成本太大且容易出错,所以大厂对snowflake进行了改造。














 3654
3654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









