









项目介绍
项目中所用到的算法模型和数据集等信息如下:
算法模型:
yolov5、yolov5 + SE注意力机制
数据集:
网上下载的数据集,格式都已转好,可直接使用。
以上是本套代码算法的简单说明,添加注意力机制可作为bishe、作业的创新点 。如果要是需要其他的检测模型,请私信。

项目简介
本文将详细介绍如何以官方yolov5为,实现对钢铁缺陷的检测识别,且利用PyQt5设计了简约的系统UI界面。在界面中,您可以选择自己的视频文件、图片文件进行检测。此外,您还可以更换自己训练的主干模型,进行自己数据的检测。
该系统界面优美,检测精度高,功能强大。它具备多目标实时检测,同时可以自由选择感兴趣的检测目标。
本博文提供了完整的Python程序代码和使用教程,适合新入门的朋友参考。您可以在文末的下载链接中获取完整的代码资源文件。以下是本博文的目录:
功能展示:
部分核心功能如下:
- 功能1: 支持单张图片识别
- 功能2: 支持遍历文件夹识别
- 功能3: 支持识别视频文件
- 功能4: 支持摄像头识别
- 功能5: 支持结果文件导出(xls格式)
- 功能6: 支持切换检测到的目标查看
更多的其他功能可以通过下方视频演示查看。
基于深度学习的钢铁表面缺陷检测系统(yolov5)
🌟 一、环境安装
本项目提供所有需要的环境安装包(python、pycharm、cuda、torch等),提供的各个库之间的版本都是匹配好的可以直接按照视频讲解或者文档进行安装。
这个指导文档是我经过三年多的精心总结(是我辅导的上千人安装环境遇到的问题总结),它汇集了详细的安装步骤以及在环境安装过程中常见的问题和解决方案。这份文档不仅全面,而且会持续更新,可以持续关注此文档。
不管你是GPU版,还是CPU版,文档中都提供了详细的安装步骤,包含各种安装细节,真心不能再详细了😂😂😂😂😂😂。。。。
在线文档截图如下,https://aax3oiawuo.feishu.cn/wiki/CDoTwQcvgiv2PmkVlAUc1fO6n8g?from=from_copylink,可以访问知识库查看。

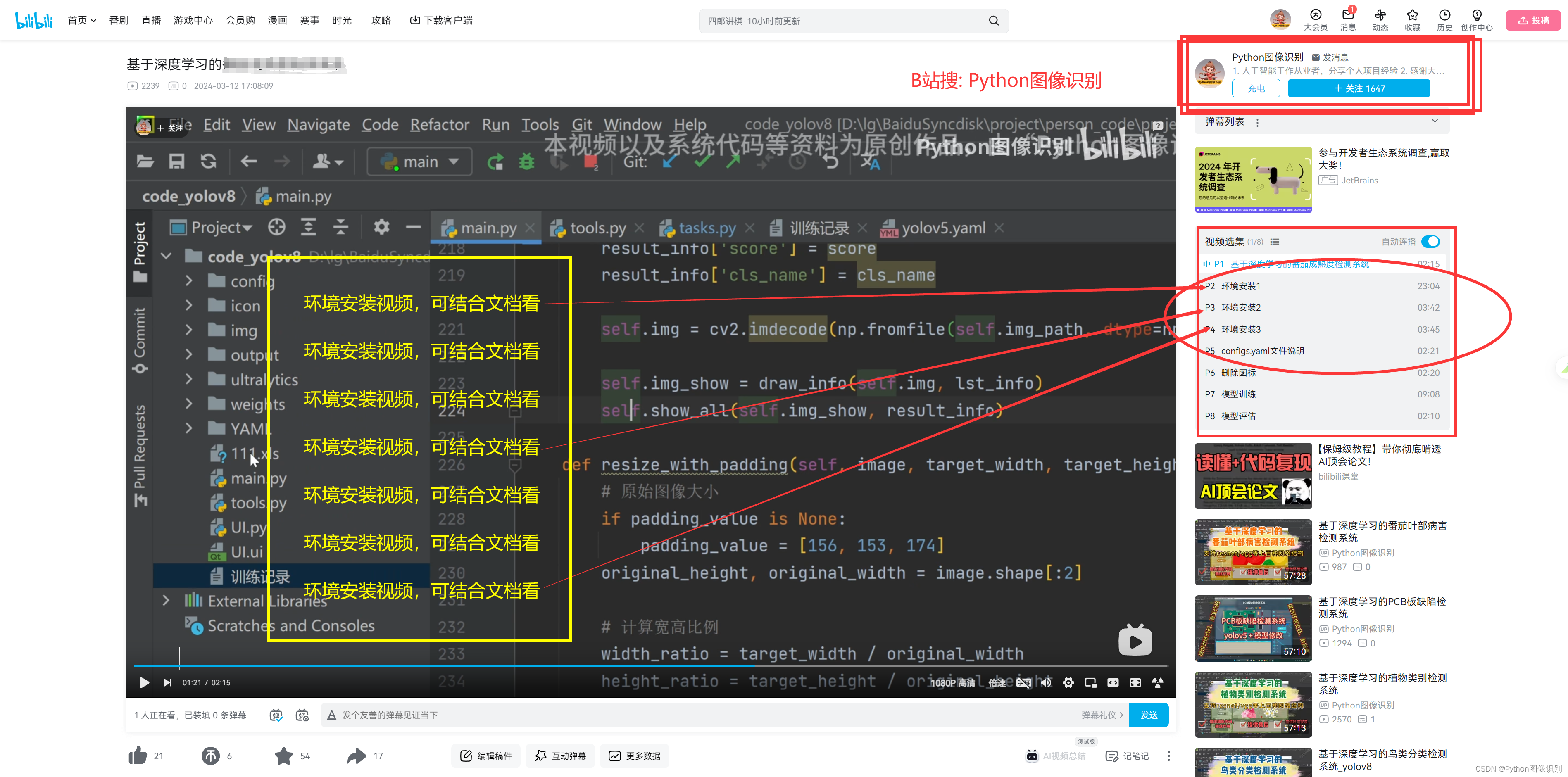
而且B站提供有和文档对应的视频,可以将视频和文档结合起来观看,更容易理解。环境安装对应的视频可以在我B站上自己对应的项目里找到,示例截图如下:
🌟 二、数据集介绍
东北大学(NEU)表面缺陷数据集,收集了热轧带钢6种典型的表面缺陷,即轧内垢(RS)、斑块(Pa)、裂纹(Cr)、点蚀面(PS)、夹杂物(In)和划痕(Sc)。该数据库包括1800张灰度图像:6种不同类型的典型表面缺陷各300个样本。
下图为6种典型表面缺陷的样本图像,每张图像的原始分辨率为200×200像素。从图中,我们可以清楚地观察到类内缺陷在外观上存在较大差异,例如划痕(最后一列)可能是水平划痕、垂直划痕和倾斜划痕等。与此同时,类间缺陷也具有相似的特征,如滚积垢、裂纹和坑状表面。此外,由于光照和材料变化的影响,类内缺陷图像的灰度会发生变化。总之,NEU表面缺陷数据库包含两个难题,即类内缺陷存在较大外观差异,类间缺陷具有相似方面,缺陷图像受到光照和材料变化的影响。

🌟 三、yolov5相关介绍
YOLOV5有YOLOv5n,YOLOv5s,YOLOv5m,YOLOV5l、YOLO5x五个版本。这个模型的结构基本一样,不同的是deth_multiole模型深度和width_multiole模型宽度这两个参数。就和我们买衣服的尺码大小排序一样,YOLOV5n网络是YOLOV5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。不过最常用的一般都是yolov5s模型。

yolov5s 网络架构如下:

(1)输入端: Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone: Focus结构、CSP结构
(3)Neck: FPN+PAN结构
(4)Prediction: GIOU_Loss
基本组件:
- Focus: 基本上就是YOLO v2的passthrough.
- CBL: 由Conv+Bn+Leaky_relu激活函数三者组成
- CSP1 X: 借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成
- CSP2 X: 不再用Res unint模块,而是改为CBL。
- SPP: 采用1x1,5x5,9x9,13x13的最大池化的方式,进行多尺度融合
🌟 四、模型训练步骤
提供封装好的训练脚本,如下图,更加详细的的操作步骤可以参考我的飞书在线文档:https://aax3oiawuo.feishu.cn/wiki/RqCQw0yBMie3WMkpOwOcilUCnsg , 强烈建议直接看文档去训练模型,文档是实时更新的,有任何的新问题,我都会实时的更新上去。另外B站也会提供视频。
-
使用pycharm打开代码,找到
train.py打开,示例截图如下:

-
修改
model_yaml的值,根据自己的实际情况修改,想要训练yolov5s模型 就 修改为model_yaml = yaml_yolov5s, 训练 添加SE注意力机制的模型就修改为model_yaml = yaml_yolov5_SE -
修改
data_path数据集路径,我这里默认指定的是traindata.yaml文件,如果训练我提供的数据,可以不用改 -
修改
model.train()中的参数,按照自己的需求和电脑硬件的情况更改# 文档中对参数有详细的说明 model.train(data=data_path, # 数据集 imgsz=640, # 训练图片大小 epochs=200, # 训练的轮次 batch=2, # 训练batch workers=0, # 加载数据线程数 device='0', # 使用显卡 optimizer='SGD', # 优化器 project='runs/train', # 模型保存路径 name=name, # 模型保存命名 ) -
修改
traindata.yaml文件, 打开traindata.yaml文件,如下所示:
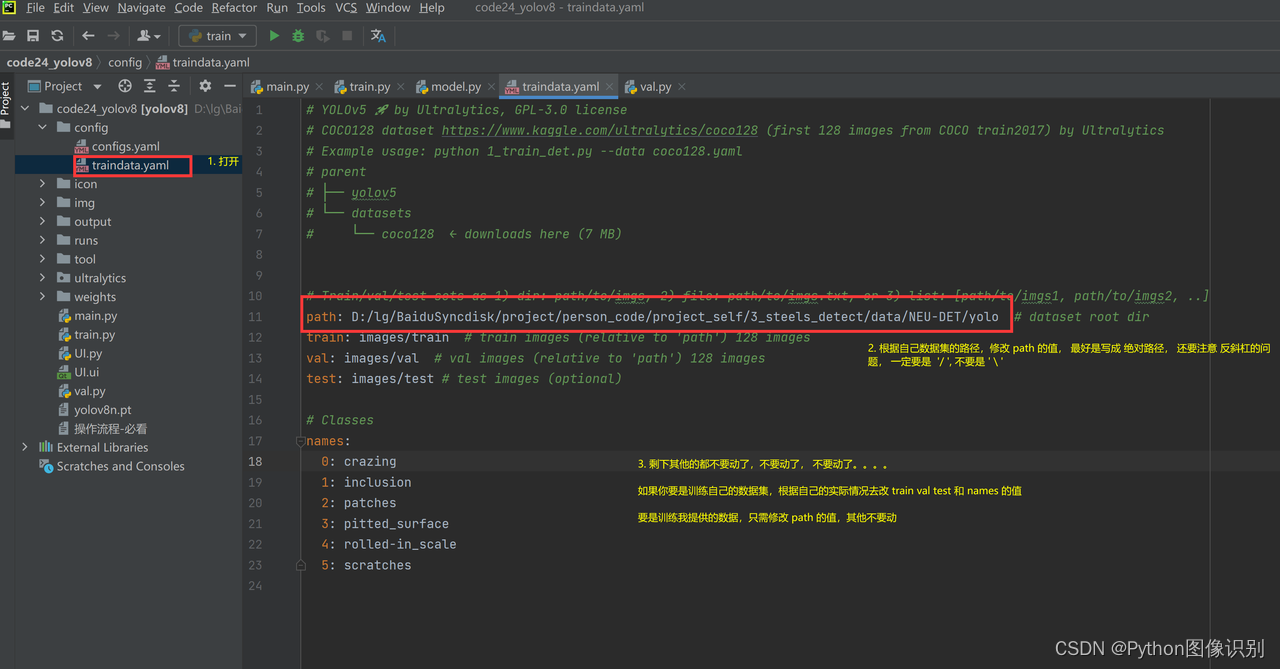
在这里,只需修改 path 的值,其他的都不用改动(仔细看上面的黄色字体),我提供的数据集默认都是到yolo文件夹,设置到 yolo 这一级即可,修改完后,返回train.py中,执行train.py。 -
打开
train.py,右键执行。

-
出现如下类似的界面代表开始训练了

-
训练完后的模型保存在runs/train文件夹下

🌟 五、模型评估步骤
-
打开
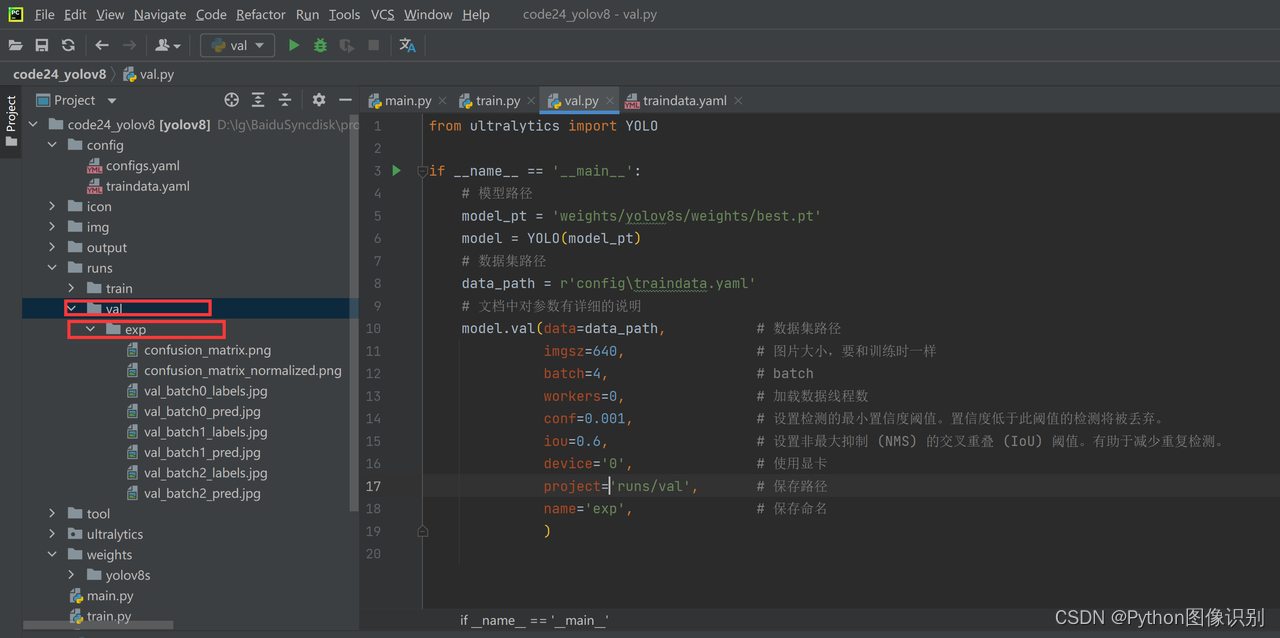
val.py文件,如下图所示:

-
修改
model_pt的值,是自己想要评估的模型路径 -
修改
data_path,根据自己的实际情况修改,具体如何修改,查看上方模型训练中的修改步骤 -
修改
model.val()中的参数,按照自己的需求和电脑硬件的情况更改model.val(data=data_path, # 数据集路径 imgsz=300, # 图片大小,要和训练时一样 batch=4, # batch workers=0, # 加载数据线程数 conf=0.001, # 设置检测的最小置信度阈值。置信度低于此阈值的检测将被丢弃。 iou=0.6, # 设置非最大抑制 (NMS) 的交叉重叠 (IoU) 阈值。有助于减少重复检测。 device='0', # 使用显卡 project='runs/val', # 保存路径 name='exp', # 保存命名 ) -
修改完后,即可执行程序,出现如下截图,代表成功(下图是示例,具体输出结果以自己的实际项目为准。)
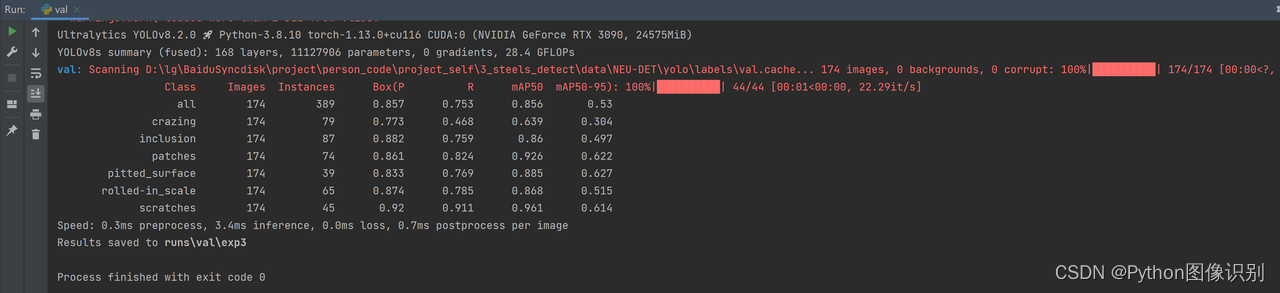
-
评估后的文件全部保存在在
runs/val/exp...文件夹下
🌟 六、 训练结果
我们每次训练后,会在 run/train 文件夹下出现一系列的文件,如下图所示:

如果大家对于上面生成的这些内容(confusion_matrix.png、results.png等)不清楚是什么意思,可以在我的知识库里查看这些指标的具体含义,示例截图如下:

🌟 获取方法
如果您希望获取博文中提到的所有实现相关的完整资源文件(包括测试图片、视频、Python脚本、UI文件、训练数据集、训练代码、界面代码等),这些文件已被全部打包。以下是完整资源包的截图:

您可以通过下方B站演示视频的视频简介部分进行获取,获取位置看下方图片文字:
B站演示视频: 【基于深度学习的钢铁表面缺陷检测系统(yolov5)】

















 8025
8025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











