




1、什么是序列化
Java允许我们在内存中创建可复用的Java对象,但只有当JVM运行时这些对象才可能存在,也就是这些对象的生命周期不会比JVM的生命周期更长。但在实际应用中,可能要求在JVM停止运行之后能够保存持久化保存对象的状态,并在将来重新读取被保存的对象,Java序列化就实现这样的功能。
序列化时jvm会把对象的状态保存为一组字节,反序列化可以将这些字节还原成对象。需要注意对象序列化保存的是对象的"状态",即它的成员变量,不会关注类中的静态变量。Java接口Serializable和Externalizable为处理对象序列化提供了一个标准机制。
2、Serializable
在Java中只要一个类实现了java.io.Serializable接口,那么它就可以被序列化和反序列化。举例如下:
public class Person implements Serializable {
private String name = null;
private Integer age = null;
//每个枚举类型都会默认继承类java.lang.Enum,而该类实现了Serializable接口,所以枚举类型对象都是默认可以被序列化的。
private Gender gender = null;
public Person() {
System.out.println("none-arg constructor");
}
public Person(String name, Integer age, Gender gender) {
System.out.println("arg constructor");
this.name = name;
this.age = age;
this.gender = gender;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Gender getGender() {
return gender;
}
public void setGender(Gender gender) {
this.gender = gender;
}
@Override
public String toString() {
return "[" + name + ", " + age + ", " + gender + "]";
}
}
public class SimpleSerial {
public static void main(String[] args) throws Exception {
File file = new File("person.out");
ObjectOutputStream oout = new ObjectOutputStream(new FileOutputStream(file));
Person person = new Person("John", 101, Gender.MALE);
oout.writeObject(person);
oout.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(file));
Object newPerson = oin.readObject(); // 没有强制转换到Person类型
oin.close();
System.out.println(newPerson);
}
}
测试程序的输出结果如下:
arg constructor
[John, 31, MALE]
当Person对象被保存到person.out文件中之后,我们可以读取该文件以还原对象,当重新读取被保存的Person对象时,并没有调用Person的任何构造器。反序列化时必须确保程序的CLASSPATH中包含有Person.class,否则会抛出ClassNotFoundException。
2.1、可以被序列化的数据类型
private void writeObject0(Object obj, boolean unshared)
throws IOException
{
boolean oldMode = bout.setBlockDataMode(false);
depth++;
try {
// 源码简化后
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
} finally {
depth--;
bout.setBlockDataMode(oldMode);
}
}
如果被序列化的对象类型是String、数组、Enum、Serializable可以进行序列化,否则将抛出NotSerializableException。
2.2、Serializable的序列化机制
2.2.1、深度序列化
深度序列化如何理解?如果某个类仅仅实现了Serializable接口而没有其他别的特殊处理的话,那么就会使用默认序列化机制。默认机制在序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其它对象也进行序列化,以此类推,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。
2.2.2、transient-序列化时忽略某个字段
当某个字段被声明为transient后,默认序列化机制就会忽略该字段。比如将Person类中的age字段声明为transient后的输出如下:
arg constructor
[John, null, MALE]
可见age字段并未参与序列化的过程。
2.2.3、writeObject()与readObject()-自定义序列化机制
可以在ObjectOutputStream的writeObject()和ObjectInputStream的readObject()中自定义序列化/反序列化机制。
public class Person implements Serializable {
transient private Integer age = null;
private void writeObject(ObjectOutputStream out) throws IOException {
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
age = in.readInt();
}
}
输出结果如下:
arg constructor
[NULL, 30, NULL]
要被序列化的字段在writeObject()中写入ObjectOutputStream中,同样反序列化时应该以同样的顺序读取字段,而且这种方式不受transient关键字的制约。那么自定义序列化机制是如何实现的呢?writeObject和readObject是如何被ObjectOutputStream和ObjectInputStream调用的呢?
答案是反射机制。ObjectOutputStream和ObjectInputStream使用了反射来寻找是否声明了这两个方法,因为它们使用getPrivateMethod,所以这些方法不得不被声明为priate以至于供ObjectOutputStream和ObjectInputStream来使用。
private void writeSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
//如果声明了WriteObject()方法使用自定义的序列化方法
if (slotDesc.hasWriteObjectMethod()) {
PutFieldImpl oldPut = curPut;
curPut = null;
SerialCallbackContext oldContext = curContext;
if (extendedDebugInfo) {
debugInfoStack.push(
"custom writeObject data (class \"" +
slotDesc.getName() + "\")");
}
try {
curContext = new SerialCallbackContext(obj, slotDesc);
bout.setBlockDataMode(true);
slotDesc.invokeWriteObject(obj, this);
bout.setBlockDataMode(false);
bout.writeByte(TC_ENDBLOCKDATA);
} finally {
curContext.setUsed();
curContext = oldContext;
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
curPut = oldPut;
} else {//否者使用默认的序列化机制
defaultWriteFields(obj, slotDesc);
}
}
}
private void readSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
if (slots[i].hasData) {
if (obj == null || handles.lookupException(passHandle) != null) {
defaultReadFields(null, slotDesc); // skip field values
} else if (slotDesc.hasReadObjectMethod()) {//有自定义的ReadObject()方法
ThreadDeath t = null;
boolean reset = false;
SerialCallbackContext oldContext = curContext;
if (oldContext != null)
oldContext.check();
try {
curContext = new SerialCallbackContext(obj, slotDesc);
bin.setBlockDataMode(true);
slotDesc.invokeReadObject(obj, this);
} catch (ClassNotFoundException ex) {
/*
* In most cases, the handle table has already
* propagated a CNFException to passHandle at this
* point; this mark call is included to address cases
* where the custom readObject method has cons'ed and
* thrown a new CNFException of its own.
*/
handles.markException(passHandle, ex);
} finally {
do {
try {
curContext.setUsed();
if (oldContext!= null)
oldContext.check();
curContext = oldContext;
reset = true;
} catch (ThreadDeath x) {
t = x; // defer until reset is true
}
} while (!reset);
if (t != null)
throw t;
}
/*
* defaultDataEnd may have been set indirectly by custom
* readObject() method when calling defaultReadObject() or
* readFields(); clear it to restore normal read behavior.
*/
defaultDataEnd = false;
} else {//使用默认的反序列机制
defaultReadFields(obj, slotDesc);
}
if (slotDesc.hasWriteObjectData()) {
skipCustomData();
} else {
bin.setBlockDataMode(false);
}
} else {
if (obj != null &&
slotDesc.hasReadObjectNoDataMethod() &&
handles.lookupException(passHandle) == null)
{
slotDesc.invokeReadObjectNoData(obj);
}
}
}
}
一定要注意Write的顺序和read的顺序需要对应。譬如writeObject有多个字段都用writeInt写入流中,那么readint需要按照顺序将其赋值。
private void writeObject(ObjectOutputStream out) throws IOException {
out.writeInt(age);
out.writeObject(name);
}
private void readObject(ObjectInputStream ins) throws IOException,ClassNotFoundException{
this.name =(String) ins.readObject();
this.age = ins.readInt();
}
报错如下:
java.io.OptionalDataException
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1585)
2.3.4、readResolve()-反序列化对象返回的入口
我们看下单例的实现:
public class Person implements Serializable {
private static class InstanceHolder {
private static final Person instatnce = new Person("John", 31, Gender.MALE);
}
public static Person getInstance() {
return InstanceHolder.instatnce;
}
private String name = null;
private Integer age = null;
private Gender gender = null;
private Person() {
System.out.println("none-arg constructor");
}
private Person(String name, Integer age, Gender gender) {
System.out.println("arg constructor");
this.name = name;
this.age = age;
this.gender = gender;
}
}
测试程序如下,我们观察下反序列化得到的对象和序列化的对象是不是同一个?
public class SimpleSerial {
public static void main(String[] args) throws Exception {
File file = new File("person.out");
ObjectOutputStream oout = new ObjectOutputStream(new FileOutputStream(file));
oout.writeObject(Person.getInstance()); // 保存单例对象
oout.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(file));
Object newPerson = oin.readObject();
oin.close();
System.out.println(newPerson);
System.out.println(Person.getInstance() == newPerson); // 将获取的对象与Person类中的单例对象进行相等性比较
}
}
输出如下:
arg constructor
[John, 31, MALE]
false
可见反序列化得到了另外一个对象,这就违反了单例的设计原则,通过readResolve()可以解决。
public class Person implements Serializable {
private static class InstanceHolder {
private static final Person instatnce = new Person("John", 31, Gender.MALE);
}
public static Person getInstance() {
return InstanceHolder.instatnce;
}
private String name = null;
private Integer age = null;
private Gender gender = null;
private Person() {
System.out.println("none-arg constructor");
}
private Person(String name, Integer age, Gender gender) {
System.out.println("arg constructor");
this.name = name;
this.age = age;
this.gender = gender;
}
private Object readResolve() throws ObjectStreamException {
return InstanceHolder.instatnce;
}
}
测试后输出:
arg constructor
[John, 31, MALE]
true
当从I/O流中读取对象时,readResolve()方法都会被调用到。实际上就是用readResolve()中返回的对象直接替换在反序列化过程中创建的对象,而被创建的对象则会被垃圾回收掉。
源码如下:
private Object readOrdinaryObject(boolean unshared)
throws IOException
{
Object obj;
try {
obj = desc.isInstantiable() ? desc.newInstance() : null;
} catch (Exception ex) {
throw (IOException) new InvalidClassException(
desc.forClass().getName(),
"unable to create instance").initCause(ex);
}
passHandle = handles.assign(unshared ? unsharedMarker : obj);
ClassNotFoundException resolveEx = desc.getResolveException();
if (resolveEx != null) {
handles.markException(passHandle, resolveEx);
}
if (desc.isExternalizable()) {
readExternalData((Externalizable) obj, desc);
} else {
readSerialData(obj, desc);
}
handles.finish(passHandle);
if (obj != null &&
handles.lookupException(passHandle) == null &&
desc.hasReadResolveMethod())
{
//反射找到ReadResolve方法,返回反序列化的对象
Object rep = desc.invokeReadResolve(obj);
if (unshared && rep.getClass().isArray()) {
rep = cloneArray(rep);
}
if (rep != obj) {
// Filter the replacement object
if (rep != null) {
if (rep.getClass().isArray()) {
filterCheck(rep.getClass(), Array.getLength(rep));
} else {
filterCheck(rep.getClass(), -1);
}
}
handles.setObject(passHandle, obj = rep);
}
}
return obj;
}
2.3.5、serialVersionUID作用
序列化的版本号,凡是实现Serializable接口的类都应有一个表示序列化版本标识符的静态变量。
private static final long serialVersionUID
serialVersionUID有两种生成方式,一、自己指定,二、IDE根据类名,接口名,方法和属性自动生成,我们一定要指定serialVersionUID,两种方式都可以。如果没有指定serialVersionUID的话,IDE默默生成的serialVersionUID在反序列化时如果源代码有改动的话,比如增减变量、方法,反序列化会失败,抛出class 不兼容异常:
Exception in thread "main" java.io.InvalidClassException: Persion;
2 local class incompatible:
3 stream classdesc serialVersionUID = -88175599799432325,
4 local class serialVersionUID = -5182532647273106745
没有指定serialVersionUID的类,java编译器会自动给这个class进行一个摘要算法,类似于指纹算法,只要这个文件多一个空格,得到的UID就会截然不同的,可以保证在这么多类中,这个编号是唯一的。所以添加了一个字段后,如果没有指定 serialVersionUID,编译器又为我们生成了一个UID,当然和前面保存在文件中的那个不会一样了,于是就出现了2个序列化版本号不一致的错误。因此,只要我们自己指定了serialVersionUID,就可以在序列化后,去添加一个字段,或者方法,而不会影响到后期的还原,还原后的对象照样可以使用,而且还多了方法或者属性可以用。
为了提高serialVersionUID的独立性和确定性,强烈建议在一个序列化类中显示的定义serialVersionUID,为它赋予明确的值。
3、Externalizable
public interface Externalizable extends java.io.Serializable {
void writeExternal(ObjectOutput out) throws IOException;
void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
}
序列化在writeExternal中完成,反序列化在readExternal中完成。
public class Person implements Externalizable {
private String name = null;
transient private Integer age = null;
private Gender gender = null;
public Person() {
System.out.println("none-arg constructor");
}
public Person(String name, Integer age, Gender gender) {
System.out.println("arg constructor");
this.name = name;
this.age = age;
this.gender = gender;
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
}
}
输出如下:
arg constructor
none-arg constructor
[null, null, null]
由于writeExternal()与readExternal()方法未作任何处理,那么该序列化行为将不会保存/读取任何一个字段,这也就是为什么输出结果中所有字段的值均为空。
使用Externalizable进行序列化,当读取对象时,会调用被序列化类的无参构造器去创建一个新的对象,然后再将被保存对象的字段的值分别填充到新对象中。因此,实现Externalizable接口的类必须要提供一个无参的构造器,且访问权限为public。
public class Person implements Externalizable {
private String name = null;
transient private Integer age = null;
private Gender gender = null;
public Person() {
System.out.println("none-arg constructor");
}
public Person(String name, Integer age, Gender gender) {
System.out.println("arg constructor");
this.name = name;
this.age = age;
this.gender = gender;
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(name);
out.writeInt(age);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = (String) in.readObject();
age = in.readInt();
}
}
输出结果如下:
arg constructor
none-arg constructor
[John, 31, null]
要注意的是,反序列化时字段读取顺序要和序列化时的写入顺序一致。
4、Parcelable
Serializable序列化用到了反射,反射会产生大量的临时对象,进而引起频繁的GC,序列化的过程较慢。Parcelable是Android为我们提供的序列化接口,Parcelable相对于Serializable的使用相对复杂一些,但Parcelable的效率相对Serializable也高很多,Google经过效率对比,Parcelable可比Serializable快10倍以上。
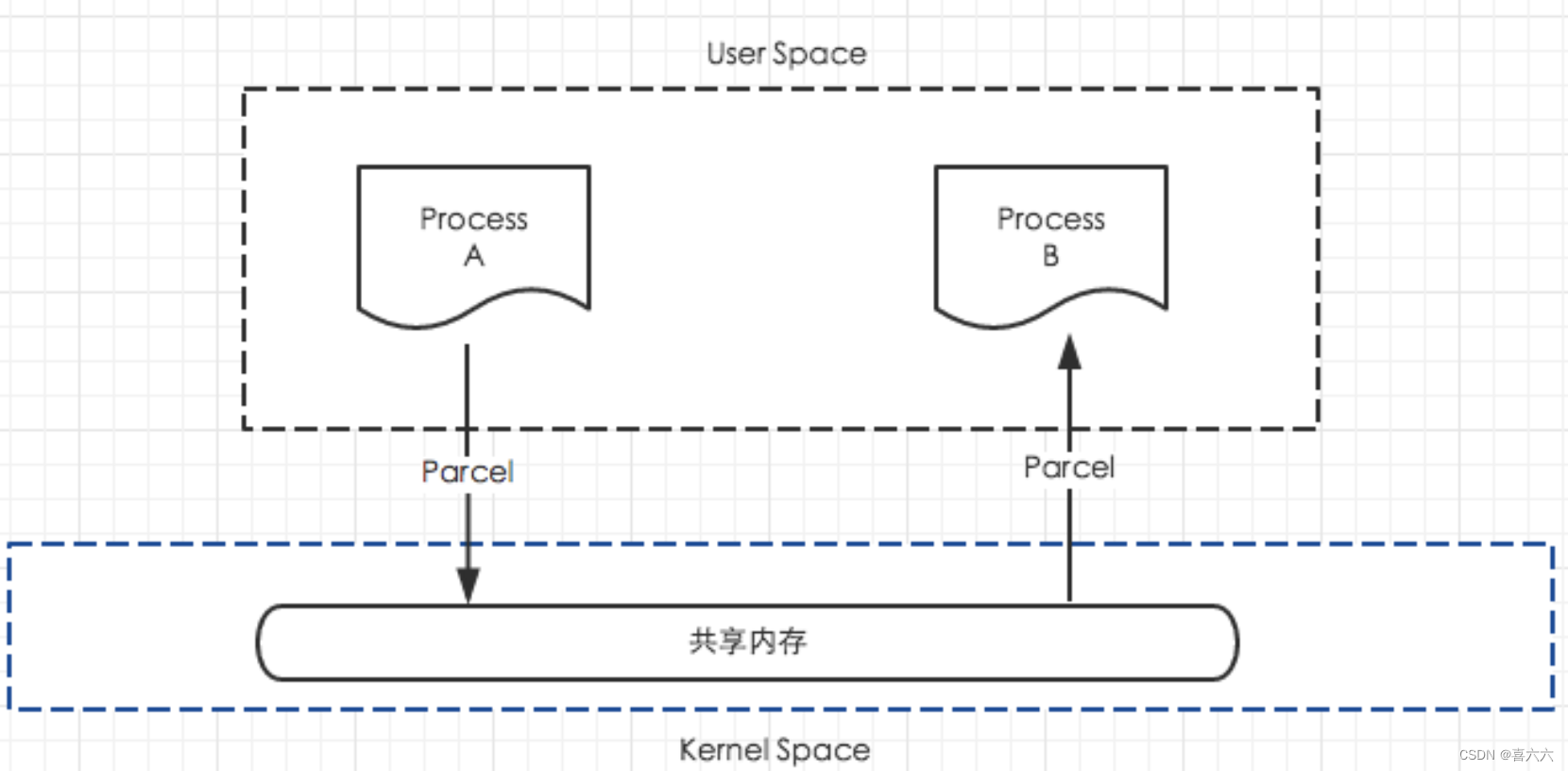
Parcelable接口是通过Parcel实现序列化的,Parcel提供了一套机制,可以将序列化之后的数据写入到一个共享内存中,其他进程通过Parcel可以从这块共享内存中读出字节流,并反序列化成对象,下图是这个过程的模型。
下面介绍下Parcelable和Serializable的作用、效率、区别及选择。
1、作用
Serializable的作用是为了保存对象的属性到本地文件、数据库、网络流、rmi以方便数据传输,当然这种传输可以是程序内的也可以是两个程序间的。而Android的Parcelable的设计初衷是因为Serializable效率过慢,为了在程序内不同组件间以及不同Android程序间(AIDL)高效的传输数据而设计,这些数据仅在内存中存在,Parcelable是通过IBinder通信的消息的载体。
2、效率及选择
Parcelable的性能比Serializable好,在内存开销方面较小,所以在内存间数据传输时推荐使用Parcelable,如activity间传输数据,而Serializable可将数据持久化方便保存,所以在需要保存或网络传输数据时选择Serializable,因为android不同版本Parcelable可能不同,所以不推荐使用Parcelable进行数据持久化。
3、编程实现
对于Serializable,类只需要实现Serializable接口,并提供一个序列化版本id(serialVersionUID)即可。Parcelable则需要实现writeToParcel、describeContents函数以及静态的CREATOR变量,实际上就是将如何打包和解包的工作自己来定义,而序列化的这些操作完全由底层实现。
5、Java序列化协议
举例如下:
class parent implements Serializable {
int parentVersion = 10;
}
class contain implements Serializable{
int containVersion = 11;
}
public class SerialTest extends parent implements Serializable {
int version = 66;
contain con = new contain();
public int getVersion() {
return version;
}
public static void main(String args[]) throws IOException {
FileOutputStream fos = new FileOutputStream("temp.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
SerialTest st = new SerialTest();
oos.writeObject(st);
oos.flush();
oos.close();
}
}
SerialTest类实现了Parent超类,内部还持有一个Container对象,以16进制形式打开temp.out,内容如下所示:
AC ED 00 05 73 72 00 0A 53 65 72 69 61 6C 54 65
73 74 05 52 81 5A AC 66 02 F6 02 00 02 49 00 07
76 65 72 73 69 6F 6E 4C 00 03 63 6F 6E 74 00 09
4C 63 6F 6E 74 61 69 6E 3B 78 72 00 06 70 61 72
65 6E 74 0E DB D2 BD 85 EE 63 7A 02 00 01 49 00
0D 70 61 72 65 6E 74 56 65 72 73 69 6F 6E 78 70
00 00 00 0A 00 00 00 42 73 72 00 07 63 6F 6E 74
61 69 6E FC BB E6 0E FB CB 60 C7 02 00 01 49 00
0E 63 6F 6E 74 61 69 6E 56 65 72 73 69 6F 6E 78
70 00 00 00 0B
1、AC ED:
STREAM_MAGIC ,声明使用了序列化协议
2、00 05
STREAM_VERSION,序列化协议版本
3、0x73
TC_OBJECT, 声明这是一个新的对象
4、0x72
TC_CLASSDESC,声明这里开始一个新 Class
5、00 0A
Class 名字的长度
6、53 65 72 69 61 6c 54 65 73 74
SerialTest,Class 类名
7、05 52 81 5A AC 66 02 F6:
SerialVersionUID, 序列化 ID ,如果没有指定,则会由算法随机生成一个 8byte 的 ID.
8、0x02
标记号,该值声明该对象支持序列化。
9、00 02
该类所包含的域个数
序列化按照上述协议格式,将Java对象序列化为二进制形式,二进制中保存类、对象、成员变量信息。反序列化也按照序列化协议,通过反射机制生成Java对象,读取字段值后赋值给该对象返回。

















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









