







大数据:数据采集平台之Scribe
-
Apache Flume
详情请看文章:《大数据:数据采集平台之Apache Flume》 -
Fluentd
详情请看文章:《大数据:数据采集平台之Fluentd》 -
Logstash
详情请看文章:《大数据:数据采集平台之Logstash》 -
Apache Chukwa
详情请看文章:《大数据:数据采集平台之Apache Chukwa 》 -
Scribe
详情请看文章:《大数据:数据采集平台之Scribe 》 -
Splunk Forwarder
详情请看文章:《大数据:数据采集平台之Splunk Forwarder》
GitHub地址: https://github.com/facebookarchive/scribe
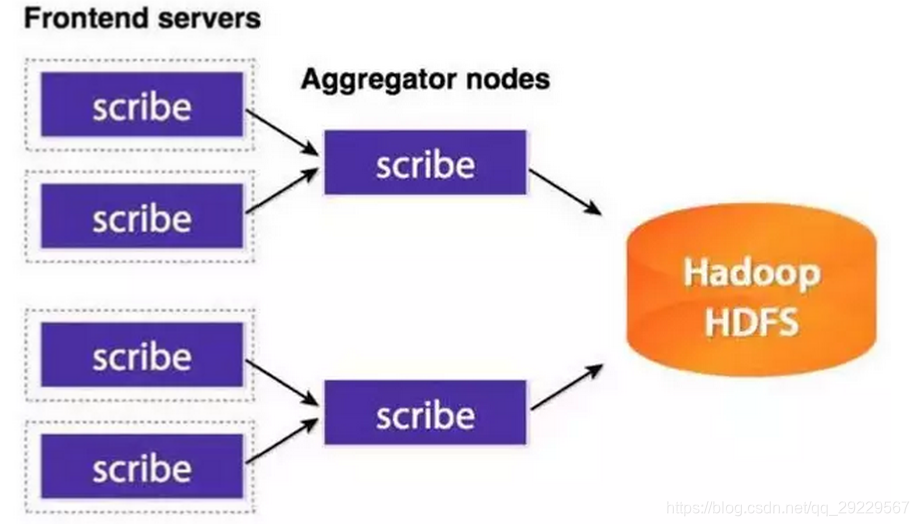
Scribe是Facebook开发的数据(日志)收集系统。已经多年不维护。部署架构如下:















 7554
7554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











