






cannot import name ‘…’ from pyecharts
问题纲要 :
1 版本问题
2.anaconda问题
3 pip镜像问题
详述:
在制作疫情热力图时,import报错:
cannot import name Map from pyecharts
cannot import name options from pyecharts
首先,我们确定我们引用方法是否正确,确定是那个版本的pyecharts为此种的引用方式,我的是这样:
from pyecharts import options as opts
from pyecharts.charts import Map
我从网上找到这种引用方法是pycharts 1.7版本的方法,所以确定下版本号,重新下载了pyecharts(卸载pyecharts为pip uninstall pyecharts)。
pip install pyecharts==1.7
但是还是提示cannot import …,我看下载完的提示中pip把文件下载到了anaconda的目录下,猜测有可能为anaconda问题。
2.删除anaconda的配置
删除的第一步:Files–>settings–>project interpreter的路径改变为python的。
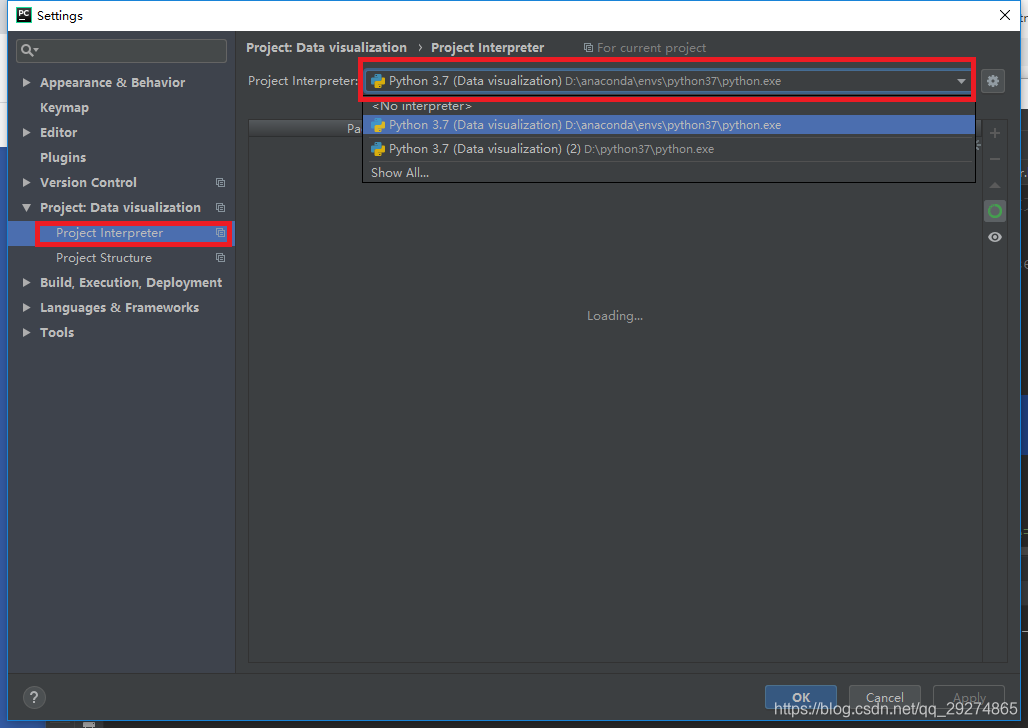 第二步:删除配置的环境变量。
第二步:删除配置的环境变量。
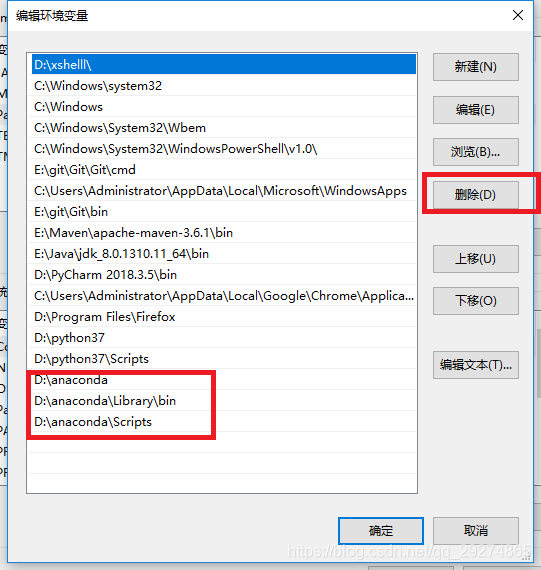
完成,在删除完成anaconda后,不知道其他同学们会出现这样的问题嘛,我用pip下载时告诉我pip不行了,如下:
Fatal error in launcher: Unable to create process using
此时用:
python -m pip install --upgrade pip
更新解决。
最后一步:在解决问题期间,上网搜集的资料提及pip下载镜像问题,在出现cannot import…之前,我为了解决pip的下载缓慢问题,曾经将自己pip的下载镜像更改为清华大学的镜像,随后为了排除一切有可能存在问题的环节,我把镜像改为了原先的pip镜像(我将pip.ini改为pip.txt,这样pip就找不到这个文件,镜像就恢复pip了)。
 最后,我重新 win+R,cmd,
最后,我重新 win+R,cmd,
pip install pyecharts==1.7
提示下载到了,python的文件夹,而不是anaconda的文件夹下。
如果提示you have already install pyecharts,安全起见可以先卸载,在安装。
卸载:
pip uninstall pyecharts
至此,解决了can not import xxx from pyecharts 的问题。
(一点浅薄的经验,有可能误打误撞解决了,欢迎指正,交流经验)。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









