







8.简单之美——布尔代数和搜索引擎
建立一个搜索引擎大致需要做的几件事情:
- 自动下载尽可能多的网页;
- 建立快速有效的索引;
- 根据相关性对网页进行公平准确的排序。
这就是搜索的“道”。
关键词=布尔运算(词1,词2,词3);接着判断词i是否在文献中,以得到一串二进制数;再根据几个词的布尔关系做布尔运算;最终便得到满足要求的文献。

由于索引之大,一开始是依靠分布式的方式存储到不同的服务器上 ,然后每接受一个查询,这个查询就被分发到许许多多的服务器中,这些服务器同时并行处理用户请求;后来再大,就变成根据网页的重要性、质量和访问频率建立常用和不常用等不同等级别的索引。
但是无论索引多么复杂,原理上依然非常简单,即等价于布尔运算。
9.图论和网络爬虫
第八章讲到了如何建立搜索引擎的索引,那么如何自动下载互联网所有的网页呢?这需要用到图论中的遍历算法。
图论就是节点+连接节点的弧,而遍历算法有两种:
- 广度优先搜索(Breadth-First Search,BFS)
- 深度优先搜索(Depth-First Search,DFS)
互联网其实就是一张大图而已——可以把每一个网页当作一个节点,把那些超链接当做连接网页的弧。用图的遍历算法,自动地访问每一个网页并把它们存起来。完成这个功能的程序叫做“网络爬虫”。
10.PageRank——Google的民主表决式网页排名技术
搜索引擎返回了成千上万条结果,那么应该如何排序呢?无异于两组信息:关于网页的质量信息,以及这个查询与每个网页的相关性信息。
10.1 PageRank算法的原理
核心在于:在互联网上,如果一个网页被很多其他网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高(就像是学术论文的引用量和重要因子,越高那它的排名也就越高)。
理论问题解决了,又遇到实际问题。因为这个量实在是太大了,于是佩奇和布林利用了稀疏矩阵计算的技巧,大大简化了计算量。而后Google又发明了并行计算工具MapReduce,使得PageRank的并行计算完全自动化了。
网页排名算法的高明之处在于它把整个互联网当作一个整体来对待。这无意中符合了系统论的观点。
10.2 PageRank的计算方法
假定向向量
(10.1)
为第一、第二、第三、...第N个网页的网页排名。矩阵A为网页之间链接的数目,其中a(mn)代表第m个网页指向第n个网页的链接数。
初试假设:所有网页排名都是1/N,即各个网页的概率是一样的,不确定性最大,熵最大:
接着就是进行迭代运算:
(10.2)
直至Bi和B(i-1)之间的差异非常小,接近于零时,停止迭代,算法结束。一般来讲10次就收敛了。
由于网页之间链接的数量相比互联网的规模非常稀疏,因此计算网页的网页排名也需要对零概率或者小概率事件进行平滑处理。则公式(10.2)就变成:
(10.3)
其中N是互联网网页的数量,α是一个(较小的)常数,I是单位矩阵
11.如何确定网页和查询的相关性
影响搜索引擎质量的诸多因素,除了用户的点击数据之外,可以被归纳成下面四大类:
- 完备的索引;
- 对网页质量的度量;
- 用户偏好;
- 确定一个网页和某个查询的相关性的方法。
11.1 搜索关键词权重的科学度量TF-IDF
根据网页的长度,对关键词的出现次数进行归一化,也就是用关键词的次数除以网页的总字数。把所得的商成为“关键词频率”(Term Frequency)。
由于关键词中各分词的分量应该是不一样的,所以必须设定不同的权重,且所设应满足下面两个条件:
- 一个词的预测主题的能力越强,权重越大,反之,权重越小;
- 停止词的权重为零
假定一个关键词w在Dw个网页中出现过,那么Dw越大,w的权重越小,反之亦然。如此称为“逆文本频率指数”(Inverse Document Frequency),它的公式是:
(11.1) 其中D是全部网页数。(这个公式其实就是前面的交叉熵公式所演变而来)
所以相关性计算的公式就为:
(11.2)
12.有限状态机和动态规划——地图与本地搜索的核心技术
就是我们日常使用最多的功能:确认地点、查看地图、查找路线。而新的技术使得我们省去了自行查地图、规划路线的时间和经理。其中只有三项关键技术:
- 利用卫星定位(传统的导航仪都可以做到)
- 地址的识别(有限状态机)
- 根据用户输入的起点和终点,在地图上规划最短路线或者最快路线(动态规划)
12.1 地址分析和有限状态机
总的来说就是,用有限状态机来识别输入的地址是否合理。有限状态机是一个特殊的有向图,它包括一些状态(节点)和连接这些状态的有向弧。
当用户输入的地址不太标准或者有错别字时,有限状态机会束手无策,因为它只能进行严格的匹配。为了解决这个问题,我们希望可以看到进行模糊匹配,并给出一个字符串为正确地址的可能性。为了实现这一目的,科学家们提出了基于概率的有限状态机。这种基于概率的有限状态机和离散的马尔科夫链基本上等效。
12.2 全球导航和动态规划
动态规划,其实就是将一个大问题分解成几个小问题,通过求解得几个局部最优解,最后得到大问题的最优解。
疑问:我觉得...这样会不会最终是收敛于一个局部最优解,而不是全局最优解,就像决策树的算法一般。不知道是怎么保证其收敛于全局最优解的?!会不会是因为决策树的最终目的地是不一样的,而有限状态机的最终目的地是“结束”,无论哪条路径都是一样的,所以基于动态规划的有限状态机可以保证全局最优解。
13.Google AK-47的设计者——艾米特·辛格博士
- 做事情的哲学,先帮助用户解决80%的问题,再慢慢解决剩下的20%的问题;
- 所选择的方案要容易解释每一个步骤和方法背后的道理,这样不仅便于出了问题时查错(Debug),而且容易找到今后改进的目标;
- 在倡导靠机器学习和大数据时,也必须要求能对机器学习出来的参数和公式给予合理的物理解释。
18.闪光的不一定是金子--谈谈搜索引擎反作弊问题和搜索结果的权威性
18.1 搜索引擎的反作弊
任何搜索引擎给出的结果都不完美,多少都会有点噪音,最主要的就是“作弊”的噪音。
- 早期常见的作弊方法是重复关键词;
- 有了pagerank网页排名之后,作弊者就专门买卖链接,在网站里暗藏了一堆没用的链接,使得网页看上去很像很多索引。
像这些作弊的“术”层出不穷,不可能针对性的一一解决,所以要上升到“道”这个层面来解决问题,就是要透过具体的作弊例子,找到作弊的动机和本质,进而从本质上解决问题。
其实,通信模型对于搜索反作弊依然适用。在通信中解决噪音干扰问题的基本思路有两条:
- 从信息源出发,加强通信(编码)自身的抗干扰能力;
- 从传输来看,过滤掉噪音,还原信息。
对应的解决方法就是:
- 从本质上看,作弊就是对排序的信息加入噪音,因此要增强排序算法的抗噪声能力;
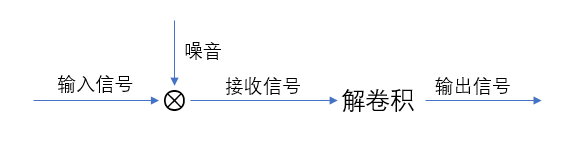
- 过滤掉噪音,就像是sony的降噪耳机一样,只要输入一个与外界噪音频率相同、振幅相反的信号来相抵消即可。如下图所示的“解卷积”过程。
18.2 搜索结果的权威性
搜索自己想要的东西之后,这些东西真实可靠吗?会不会是那些骗人的莆田系医生呢?所以搜索结果的权威性很重要!计算权威度的步骤如下:
- 对每一个网页正文重点每一句话提炼出“主题”和“提及”:就像是--“根据国际卫生组织的研究发现,吸烟对人有危害”这句话,就可以提炼出“吸烟的危害”作为主题,“国际卫生组织”作为提及;
- 然后在各种新闻、学术论文或其他网页中,利用互信息,找到它们之间的相关性;
- 利用聚类算法,对一些相近意思的词进行聚类得到一些搜索的主题;
- 还要把一个网站当中的网页进行聚合,因为网站当中不是所有的网页都是权威的。
通过这四步,就可以得到一个针对不同主题,哪些信息源(网站)具有权威度的关联矩阵。有了这个,便可在搜索结果中提升那些来自于权威信息源的结果,使得用户对搜索结果更加放心。
19.谈谈数学模型的重要性
牛顿曾经说过:我们见过所有真实的东西,在宇宙中也是真实的。
所以我们数学模型的推导,其实就是基于已知数据的观察所得来的,通过数据寻找规律。像以前的地心说、日心说......通过前人的经验学习,我们可以得知:
- 一个正确的数学模型应当在形式上是简单的(托勒密的模型显得太复杂)。
- 一个正确的模型一开始可能还不如一个精雕细琢过的错误模型来的准确,但是,如果我们认定大方向是对的,就应该坚持下去;(日心说一开始并没有地心说准确)。
- 大量准确的数据对研发很重要。
- 正确的模型也可能受噪音干扰,而显得不准确;这是不应该用一种凑合的修正方法加以弥补,而是要找到噪音的根源,这也许能通往重大的发现。
在网络搜索的研发中,我们在前面提到的单文本词频/逆文本频率指数(TF-IDF)和网页排名(PageRank)可以看做是网络搜索中的“椭圆模型”,它们都很简单易懂。
20.不要把鸡蛋放在一个篮子里--谈谈最大熵模型
当你要猜一个概率分布时,如果你对这个分布一无所知,那就猜熵最大的均匀分布,如果你对这个分布知道一些情况,那么,就猜满足这些情况的熵最大的分布。
我们从最大熵的思想出发得出的最大熵模型,最后的最大化求解就是在求P(y|x)的对数似然最大化。逻辑回归也是在求条件概率分布关于样本数据的对数似然最大化。二者唯一的不同就是条件概率分布的表示形式不同。
https://www.jianshu.com/p/e7c13002440d















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









