







目录
课程内容:
基础知识
requests
数据提取
动态网页数据提取
scrapy
scrapy redis
总结
- 不要硬刚,多试试移动版的API,会更简单
- 爬虫的流程经常是: 准备url–>发送请求–>解析数据–>存储数据–> 获取新的url–>重复…
- 准备URL有2种策略:
- 准备start_url (种子url)
- url地址规律不明显
- url总数不确定
- 直接准备url_list( 准备所有的url)
- url地址规律明显
- 页面总数确定
- 准备start_url (种子url)
- 注意反爬虫
- 修改User-Agent
- 使用多个代理IP
- 添加请求之间的间隔时间
- 使用cookie
1.可以准备一堆能用的cookie,切换使用(特别当请求内容需要登陆的时候,准备多个账号的cookie,防止爬虫识别) - 确定数据的位置
- 在直接返回的 HTML种
- 在其他的响应内
- 网络抓包来找
- 搜索数据相关关键字
- 查找对应按钮的响应 handler
0. 安装python模块的方法
pip install 模块名- 下载源码压缩包,解压,进入目录,
python setup.py install - 对于
xxx.whl文件, 直接pip install xxx.whl
1. 爬虫的基础知识
爬虫更多用途:
- 12306抢票
- 网络投票
- 短信轰炸
不一定要硬刚正面,比如抢票可以不去12306,去和它合作的其他网站; 搜索微信公众号也可以不去微信,而去合作网站比如搜狗里面获取。
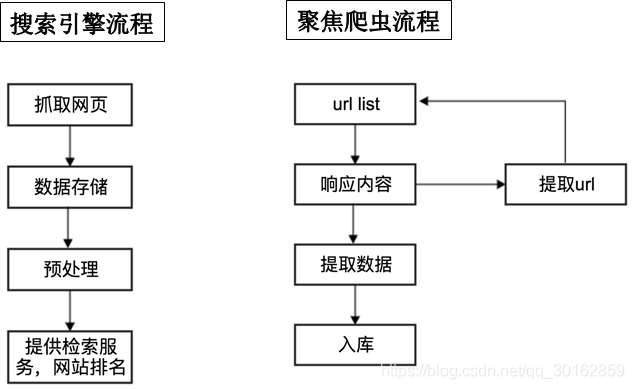
1.1 爬虫的分类
-
通用爬虫 :通常指搜索引擎的爬虫
-
聚焦爬虫 :针对特定网站的爬虫
1.2 爬虫工作流程
确认URL–> 获取数据 --> 保存
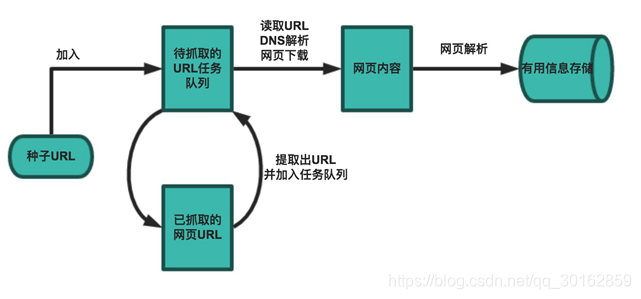
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。
a. 通用搜索引擎的局限性
-
通用搜索引擎所返回的网页里90%的内容无用。
-
图片、音频、视频多媒体的内容通用搜索引擎无能为力
-
不同用户搜索的目的不全相同,但是返回内容相同
b. robots协议
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。——君子协议
https://www.taobao.com/robots.txt
https://www.jd.com/robots.txt
https://www.qq.com/robots.txt
http://www.360.cn/robots.txt

1.3 HTTP和HTTPS

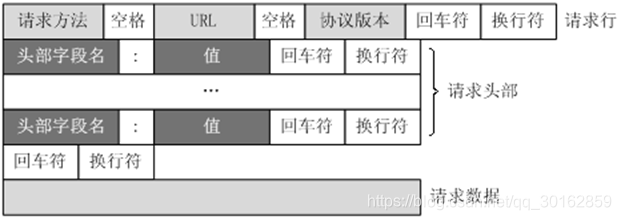
a. HTTP请求格式
b. HTTP常用请求header

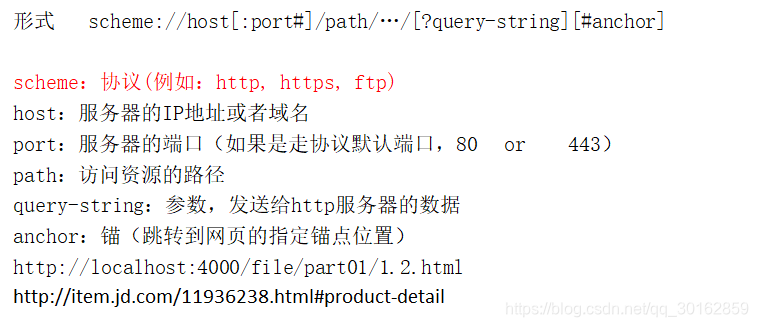
1.4 URL的格式
1.5 字符串
- 字符集包括:ASCII字符集、GB2312字符集、GB18030字符集、Unicode字符集等
- ASCII编码是1个字节,而Unicode编码通常是2个字节。
- UTF-8是Unicode的实现方式之一,UTF-8是它是一种变长的编码方式,可以是1,2,3个字节,中文一般占3个字节
字符串有2种类型:
- byte
- str
2. requests库

2.1 基本使用
| response常用属性 | 说明 |
|---|---|
| response.text | 根据响应的内容,去判断解码方式,解码成文本 |
| respones.content | 直接获取相应体的二进制内容 |
| response.status_code | 获取响应的状态码 |
| response.request.headers | 获取这次 请求的头部 |
| response.headers | 获取响应的头部 |
| response.url | 获取响应内容的来源url |
| response.request.url | 请求的url |
注意:返回200状态码并不代表想要请求的url成功了,比如请求某些页面,最后要你跳转到登陆,也是成功
a. 发送请求
import requests
# get请求
r = requests.get('https://api.github.com/events')
payload = {
'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)
# post请求
r = requests.post('http://httpbin.org/post', data = {
'key':'value'})
# 其他请求
>>> r = requests.put('http://httpbin.org/put', data = {
'key':'value'})
>>> r = requests.delete('http://httpbin.org/delete')
>>> r = requests.head('http://httpbin.org/get')
>>> r = requests.options('http://httpbin.org/get')
b. 响应内容
r.text
r.encoding = "utf-8"
r.content
r.status_code
r.json() # 这个也是二进制
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size):
fd.write(chunk)
判断状态码是否成功
assert r.status_code == 200
response.text 和 reponse.content的区别
-
response.text
类型:str
解码类型: 根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
如何修改编码方式:response.encoding=”gbk” -
response.content
类型:bytes
解码类型: 没有指定
如何修改编码方式:response.content.deocde(“utf8”)
推荐使用
content
2.2 修改发送的Header——headers参数
只要传递一个字典给headers参数就可以了
url = 'https://api.github.com/some/endpoint'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
r = requests.get(url, headers=headers)
2.3 GET发送带参数的请求
get方式的参数,传递一个字典给 params参数就可以了
kw = {
'wd':'长城'}
requests.get(url,params=kw)
url编码解码 ——requests.utils.unquote
requests.utils.unquoterequests.utils.quote
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
qs = {
"wd":"传智播客"}
r = requests.get("http://www.baidu.com", headers = headers,params= qs)
print(r.url)
myurl = requests.utils.unquote(r.url)
print(myurl)
2.4 发送POST请求
使用情景:
- 提交表单
- 上传大文本
如何使用:
- 调用
requests.post方法 - 传递
data参数
response = requests.post("http://www.baidu.com/", data = data,headers=headers)
★案例——百度翻译
百度翻译的网页版,在翻译的时候,会上传一个sign字段和token字段。 token是直接在当前的HTML页面中有的,而sign是根据翻译的内容来动态生成的。虽然可以去找到生成的js代码来生成,但是可以想别的办法 —— 不要硬刚正面,试一试移动端的api
网页版翻译可以使用2个api:
- https://fanyi.baidu.com/langdetect 用于判断翻译的内容是什么语言
- https://fanyi.baidu.com/v2transapi 翻译的api
移动端翻译也可以使用2个api:
- https://fanyi.baidu.com/langdetect 判断翻译的内容是什么语言
- https://fanyi.baidu.com/basetrans 翻译api
代码:
import requests
import json
import sys
queryWords = sys.argv[1] # "人生苦短,我用Python"
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1"
}
# 判断原始内容是什么语言
lan_url = "https://fanyi.baidu.com/langdetect"
lan_queryString = {
"query": queryWords}
lan_response = requests.post(lan_url, headers=headers, data=lan_queryString)
original_lan = json.loads(lan_response.content.decode())["lan"]
# 执行翻译
fanyi_url = "https://fanyi.baidu.com/basetrans"
fanyi_queryString = {
"query": queryWords,
"from": original_lan,
"to": "en" if original_lan == "zh" else "zh"}
fanyi_response = requests.post(fanyi_url, headers=headers, data=fanyi_queryString)
result = json.loads(fanyi_response.content.decode())["trans"][0]["dst"]
print(result)
总结:
- 使用
sys.argv来获取输入, 这样就可以python 文件名 翻译内容来调用 - 可以使用
alias fanyi="python ....文件名"来设置别名,这样就可以fanyi 翻译内容简化调用 - 爬取不一定要硬刚正面
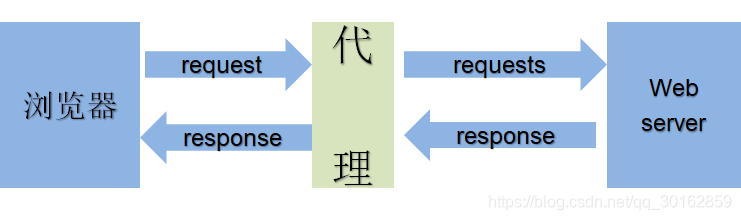
2.5 使用代理
为什么使用代理:
- 让服务器以为不是同一个客户端在请求,多次使用同一个IP请求,频率过高的时候容易被封
- 防止我们的真实地址被泄露,防止被追究
代码:
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
import requests
proxies = {
# "http": "http://122.116.232.79:57749",
# "http": "http://113.14.195.178",
# "https": "http://122.116.232.79:57749",
"https":"https://221.218.102.146:37015"
}
headers = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1"
}
r = requests.get("http://www.baidu.com", headers=headers, proxies=proxies)
print(r.status_code)
a. 使用代理的注意事项
应该找一堆IP地址,组成IP池,每次随机选择一个IP
- 应该让次数使用较少的IP有更大的可能性被挑选到
{"ip": ip, "times" : 0 }记录每个IP地址的使用次数[{}, {}, {}, {}, {}]对这些IP进行列表排序即可
- 应该检查IP的可用性
- 添加
requests请求的超时参数,来判断ip的质量 - 使用在线代理IP检测网站
- 添加
b. ★正向代理和反向代理
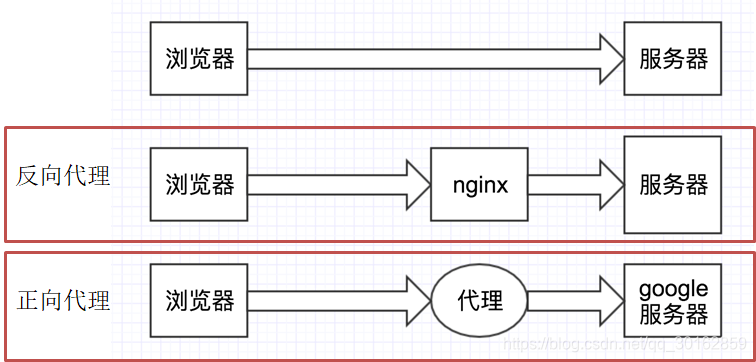
- 正向代理: 客户端知道服务器的信息,但是找了一个代理帮助客户端来发送请求,拿到请求后交还给客户端。
- 反向代理:客户端不知道服务器的信息,只知道nginx的信息,所以把请求发送给nginx,让nginx自己去服务器找,至于究竟找的哪台服务器,客户端完全不知道。
正向代理和反向代理主要的区别就是: 客户端是不是知晓服务器信息
2.6 cookie和session
- cookie对于爬虫的好处:
可以请求登陆后的页面 - cookie对于爬虫的坏处:
一套cookie和session往往和一个用户对应, 请求太快,请求次数太多,容易被服务器识别为爬虫

使用方式:
import requests
session = requests.session()
session.get(url,headers, params...)
思路:
- 创建session
- 使用session去发送登陆请求,登陆之后的cookie会自动保存在session对象中
- 使用同一个session对象再去访问需要登陆的页面
a. session和cookie的特点
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗。
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
b. 登陆的三种方式
- 使用session去发送请求登陆
- 直接从浏览器登陆,然后获取浏览器的
Cookie头部,将头部添加到请求的headers中 - 可以发送请求的时候传递
cookies参数,在内部传递字典形式的cookie
c. ★★如何获取POST的地址
- 同步提交的表单,可以在
form标签中找action—— 提交的数据为表单中的表单控件name属性和value属性 - 抓包查看请求URL,根据POST参数来确认是哪个URL
- 查找对应按钮的
click事件,查看js代码
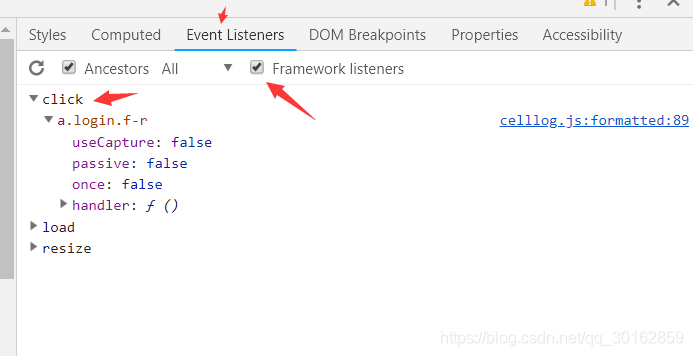
d. ★POST参数哪里来的:
- 表单中
hidden - 先请求了一个别的URL,这个URL返回的 —— 浏览器抓包
- JS创建的
如何查看: chrome浏览器的调试工具中—— source —— 搜索
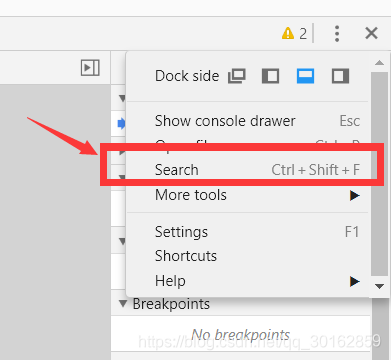
- 参数不会变: 直接使用,比如说密码不是动态加密
- 参数会变:
- 参数来自当前响应
- 通过js,再结合其他的数据动态生成
2.7 cookie对象和字符串之间的转换
response对象的cookies属性返回的是RequestsCookieJar对象,可以使用下面的方法将这个对象内容转换成字典:
requests.utils.dict_from_cookiejar(r1.cookies)
同样的也有从字典转换到cookie的方法:
requests.utils.cookiejar_from_dict
2.8 请求SSL证书验证
如果请求的url地址的证书不安全的话,请求会报错,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1559
1559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









