







1.# 系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
随着大数据的兴起,搜索越来越重要,ElasticSearch也越来越多人使用提示:以下是本篇文章正文内容,下面案例可供参考
一、Maven依赖引入
maven:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.13.1</version>
</dependency>
二、创建ElasticSearch配置客户端
代码如下(示例):
public static RestHighLevelClient getRestHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.0.201", 9200, "http")));
return client;
}
三、创建索引
代码如下(示例):
private static void createIndex() throws Exception {
CreateIndexRequest createIndexRequest = new CreateIndexRequest(LGY_LEARN_ES);
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.startObject("properties");
{
builder.startObject("movie_id");
{
builder.field("type", "long");
}
builder.endObject();
builder.startObject("movie_name");
{
builder.field("type", "text")
.field("analyzer", "ik_smart")
.field("search_analyzer", "ik_max_word");
}
builder.endObject();
builder.startObject("movie_detail");
{
builder.field("type", "text").field("analyzer", "ik_smart")
.field("search_analyzer", "ik_max_word");
}
builder.endObject();
}
builder.endObject();
}
builder.endObject();
createIndexRequest.mapping(builder);
CreateIndexResponse response = getRestHighLevelClient().indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println(response);
}
四、ik分词器详解
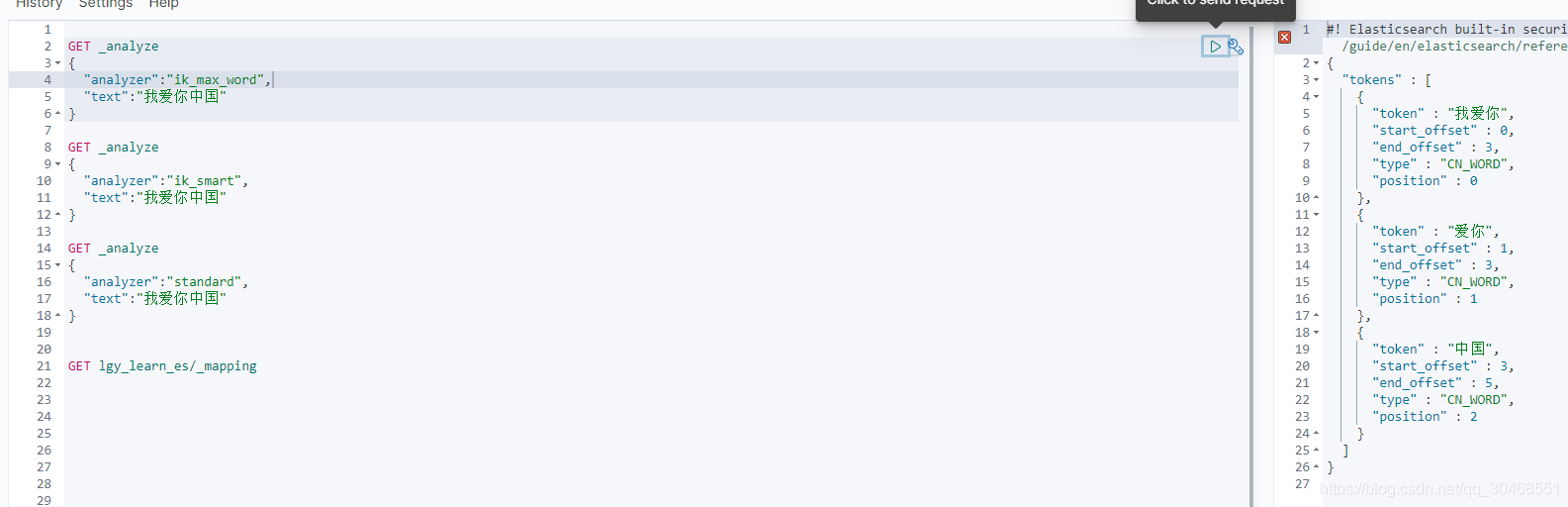
ik_max_word是做了最细粒度的拆分,比如:我爱你中国,会拆分成 “我爱你、爱你、中国”
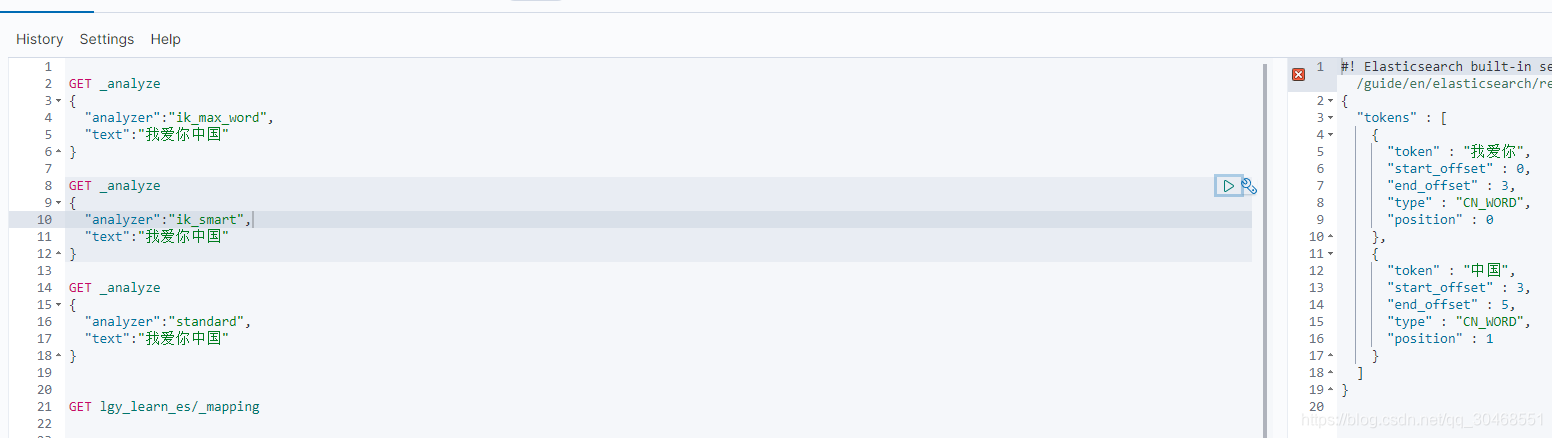
ik_word是做了最粗粒度的拆分,比如:我爱你中国,会拆分成 “我爱你、中国”
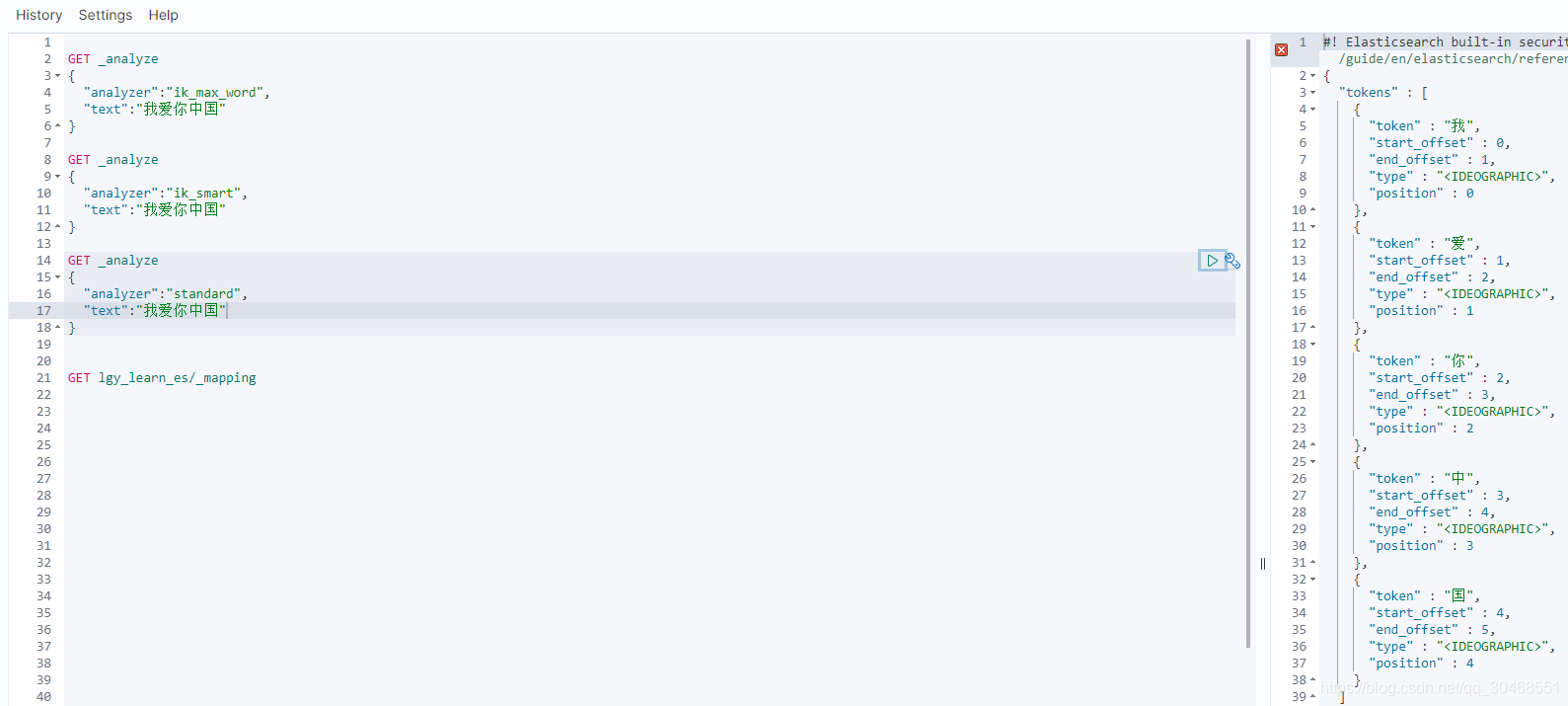
standard是ES自带的分词器,默认只对英文分词,所以对中文分不了词,比如 我爱你中国,会拆分成 “我、爱、你、中、国”
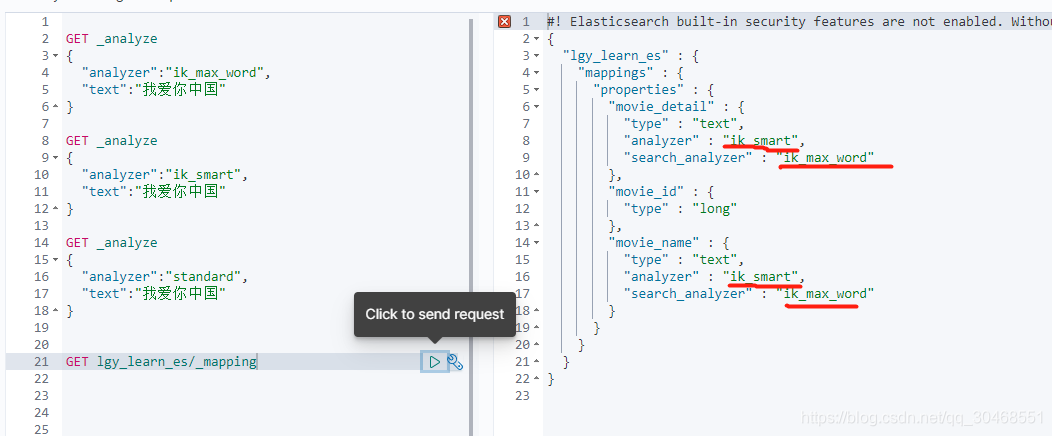
五、查看效果















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











