







时间复杂度:反映当数据量变化时,操作次数的多少;时间复杂度在评估时,要只保留最高项,并且不要最高项的系数。
时间复杂度的大小比较: N!> x^N >...>3^N >2^N > N^x>...>N^3 >N^2>NlogN>N>logN>1
空间复杂度:是指算法在计算机内执行时,所需额外开辟的空间。
稳定性:
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
十大经典排序算法可以分为两大类:
非线性时间排序:通过比较来决定元素间的相对次序。时间复杂度最快为O(logN)
线性时间排序:通过创建有序的空间,将元素按照一定的规则放入有序空间,再依次取出。以空间来换取时间,可以突破O(logN)
- 非线性时间排序
- 比较排序
- 冒泡排序
- 快速排序
- 插入排序
- 插入排序
- 希尔排序
- 选择排序
- 选择排序
- 堆排序
- 归并排序
- 二路归并排序
- 多路归并排序
- 比较排序
- 线性时间排序:计数排序、堆排序、基数排序
算法实现:
A代表平均时间复杂度 、B代表最坏时间复杂度 、E代表最好时间复杂度
1、冒泡排序
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
实现逻辑:
比较相邻的元素。如果第一个比第二个大,就交换它们两个;
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
针对所有的元素重复以上的步骤,除了最后一个;
重复步骤1~3,直到排序完成。
动画演示:
1.1、简单冒泡排序(交换排序;A:N^2 ,B:N^2 ,E:N^2 ;空间1;稳定)
void BubbleSort(int arr[],int len)
{
for (int i = 1; i < len; i++)//循环len-1次
for (int j = 0; j < len-i; j++)
if (arr[j] > arr[j+1])
{
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}第一个for循环是遍历所有元素,第二个for循环是每次遍历元素时都对无序区的相邻两个元素进行一次比较,若反序则交换。
1.2、外层循环优化冒泡排序(时间A:N^2 , B:N^2 , E:N; 空间1; 稳定)
如果第一次比较完没有交换即说明已经有序,不应该进行下一次遍历,相比较于简单冒泡排序,最好的情况是正序,只进行(n-1)次比较,不需要移动,时间复杂度为O(n)。
void BubbleSortOut(int arr[], int len)
{
for (int i = 1; i < len; i++)//循环len-1次
{
bool flag = true;
for (int j = 0; j < len - i; j++)
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = false;
}
if (flag)
break;
}
}1.3、内层循环优化冒泡排序
如果第一次比较完没有交换即说明已经有序,不应该进行下一次遍历;还有已经遍历出部分有序的序列后,那部分也不用进行遍历,即发生交换的地方之后的地方不用遍历
void BubbleSort3(int arr[], int len)
{
int pos = 0;
int k = len - 1;
for (int i = 1; i < len; i++)//循环len-1次
{
bool flag = true;
for (int j = 0; j < k; j++)
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = false;
pos = j;
}
k = pos;
if (flag)
break;
}
}2、快速排序(这种方法好像不对??)
通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。时间A:NlogN,B:NlogN,E:NlogN;空间logN;不稳定
实现逻辑:
1从数列中挑出一个元素,称为 “基准”(pivot);
2分区过程,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
3递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。对左右区间重复第二步,直到各区间只有一个数
举例说明,主要有三个参数,i为区间的开始地址,j为区间的结束地址,X为当前的开始的值
第一步,i=0,j=9,X=23
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 23 | 30 | 43 | 90 | 56 | 48 | 29 | 1 | 70 | 80 |
第二步,先从j开始,由后向前找,找到比X小的第一个数a[7]=1, 进行替换,此时i=0,j=7,X=23
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | 30 | 43 | 90 | 56 | 48 | 29 | 23 | 70 | 80 |
第三步,从i开始,由前往后找,找到比X大的第一个数a[1]=30,
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | 23 | 43 | 90 | 56 | 48 | 29 | 30 | 70 | 80 |
第四步,再从j=7开始,由后向前找,找到比X小的第一个数a[0]=1,此时i=1,j=0,X=21,发现j<=i,所以第一回结束。
可以发现23前面的数字都比23小,后面的数字都比23大,接下来对两个子区间[0,0]和[2,9]重复上面的操作即可
void QuickSort(int arr[], int first, int end) {
if (first < end) {
int i = first; int j = end;
//从右边区开始,保证i<j并且arr[i]小于或者等于arr[j]的时候就向左遍历
while (i < j) {
while (i<j && arr[i] <= arr[j])
j--;
if (i < j) {
int temp = arr[j];
arr[j] = arr[i];
arr[i] = temp;
}
//对另一边执行同样的操作
while (i < j && arr[i] <= arr[j])
i++;
if (i < j) {
int temp = arr[j];
arr[j] = arr[i];
arr[i] = temp;
}
}
int pivot = i;//将i设为新的轴值
//再对轴值左右进行递归
QuickSort(arr, first, pivot - 1);
QuickSort(arr, pivot + 1, end);
}
}3、插入排序
插入排序的基本方法是:每步将一个待排序的元素,按其排序码大小插入到前面已经排好序的一组元素的适当位置上去,直到元素全部插入为止。 选择不同的方法在已经排好序的有序数据表中寻找插入位置,依据查找方法的不同,有多种插入排序方法。下面是常用的三种。
1>直接插入排序
2>折半插入排序
3>希尔排序
直接插入排序基本思想:当插入第i(i>1)个元素时,前面的data[0],data[1]……data[i-1]已经排好序。这时用data[i]的排序码与data[i-1],data[i-2],……的排序码顺序进行比较,找到插入位置即将data[i]插入,原来位置上的元素向后顺序移动。
折半插入排序基本思想:设元素序列data[0],data[1],……data[n-1]。其中data[0],data[1],……data[i-1]是已经排好序的元素。在插入data[i]时,利用折半搜索法寻找data[i]的插入位置。
3.1、直接插入排序
整个序列分为有序区和无序区,取第一个元素作为初始有序区,然后第二个开始,依次插入到有序区的合适位置,直到排好序。(时间A:N^2 , B:N^2 , E:N;空间1;稳定)
实现逻辑:
1从第一个元素开始,该元素可以认为已经被排序;
2取出下一个元素,在已经排序的元素序列中从后向前扫描;如果已排序中的某元素大于我们选取的这个元素,将选取的这个元素移到元素的下一位置;
重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
将新元素插入到该位置后;
重复步骤2~5。
动画演示:
void InsertSort(int arr[], int len) {
for (int i = 1; i < len; i++)
for (int j = i; j > 0; j--)
if (arr[j] < arr[j - 1]) {
int temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
}
}第一个for循环对从第二个开始的所有的数字遍历,嵌套的for循环是每次遍历数字时都取无序区的一个元素与有序区的元素比较,如果比有序区的要小则交换,直到合适的位置。
3.2、希尔排序
希尔排序(shell sort)这个排序方法又称为缩小增量排序,该方法的基本思想是:设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入排序。然后缩小间隔increment,重复上述子序列划分和排序工作。直到最后取increment=1,将所有元素放在同一个子序列中排序为止。
由于开始时,increment的取值较大,每个子序列中的元素较少,排序速度较快,到排序后期increment取值逐渐变小,子序列中元素个数逐渐增多,但由于前面工作的基础,大多数元素已经基本有序,所以排序速度仍然很快。
希尔排序举例:
1、第一趟取increment:n/3向下取整+1=3。将整个数据列划分为间隔为3的3个子序列,然后对每一个子序列执行直接插入排序,相当于对整个序列执行了部分排序调整。
2、第二趟将间隔increment= (increment/3向下取整)+1=2,将整个元素序列划分为2个间隔为2的子序列,分别进行排序。
3、第3趟把间隔缩小为increment= (increment/3向下取整)+1=1,当增量为1的时候,实际上就是把整个数列作为一个子序列进行插入排序.直到increment=1时,就是对整个数列做最后一次调整,因为前面的序列调整已经使得整个序列部分有序,所以最后一次调整也变得十分轻松,这也是希尔排序性能优越的体现。
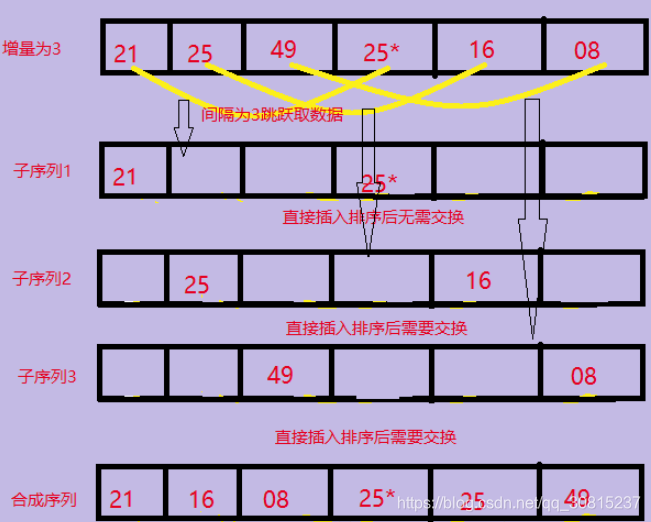
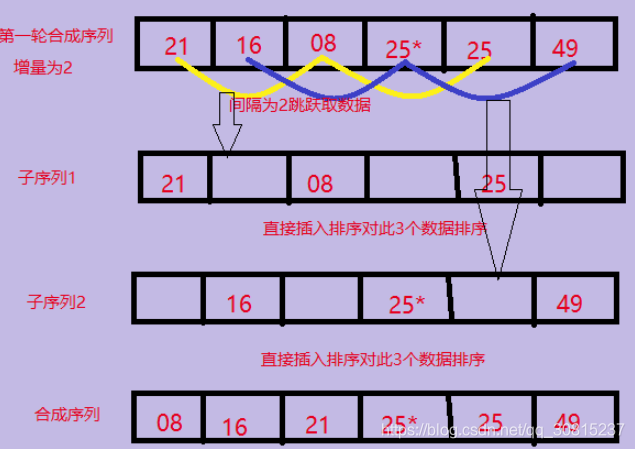
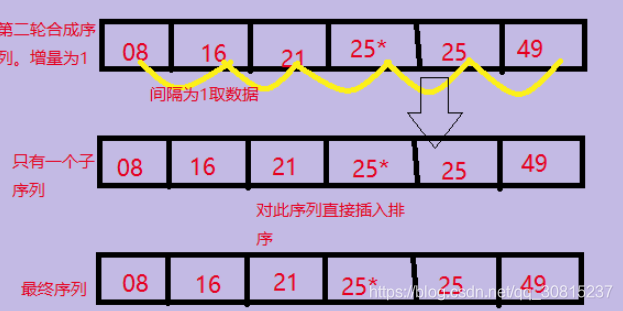
void ShellSort(int arr[], int len) {
int gap = len;
while (gap > 1) {
gap = gap / 3 + 1;
for (int i = gap; i < len; i += gap)
for (int j = i; j > 0;j-=gap)
if (arr[j] < arr[j - gap]) {
int temp = arr[j];
arr[j] = arr[j - gap];
arr[j - gap] = temp;
}
for (int m = 0; m < len; m++)
cout << arr[m]<<" ";
cout << endl;
}
}4、选择排序
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
void SelectSort(int arr[], int len) {
for (int i = 0; i < len; i++) {
int mindex = i;
for (int j = i + 1; j < len; j++) {
if (arr[j] < arr[mindex])
mindex = j;
}
int temp = arr[mindex];
arr[mindex] = arr[i];
arr[i] = temp;
for (int m = 0; m < len; m++)
cout << arr[m] << " ";
cout << endl;
}
}5、堆排序
堆排序利用的是二叉树的思想,所谓堆就是一个完全二叉树,完全二叉树就是,除了叶子节点,其它所有节点都有两个子节点,完全二叉树就可以用一个一块连续的内存空间(数组)来存储,而不需要指针操作了。
堆排序分两个流程,首先是构建大顶堆,然后是从大顶堆中获取按逆序提取元素。大顶堆即一个完全二叉树,的每一个节点都大于它的所有子节点。大顶堆可以按照从上到下从左到右的顺序,用数组来存储,第i个节点的父节点序号为(i-1)/2,左子节点序号为2i+1,右子节点序号为2(i+1)。
构建大顶堆的过程即从后向前遍历所有非叶子节点,若它小于左右子节点,则与左右子节点中最大的交换,然后递归地对原最大节点做同样的操作.
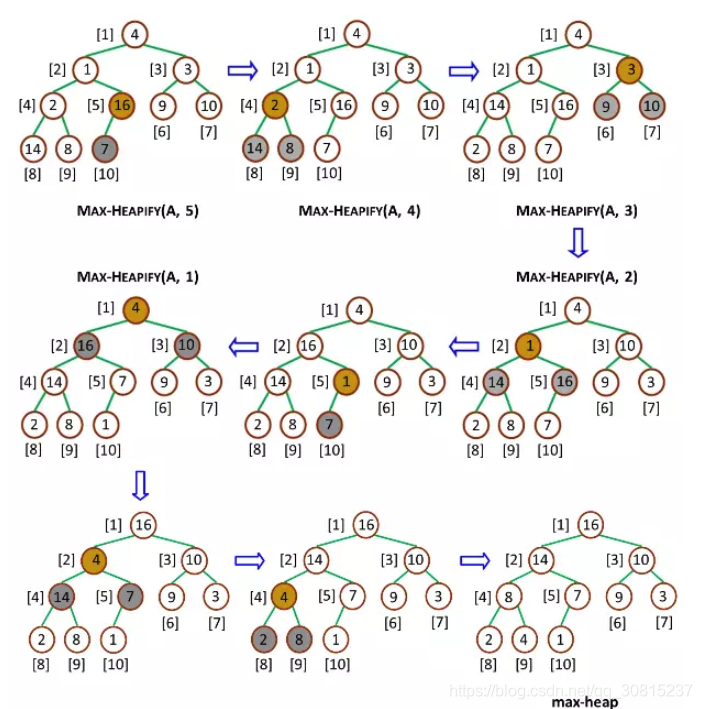
构建完大顶堆后,我们需要按逆序提取元素,从而获得一个递增的序列。首先将根节点和最后一个节点交换,这样最大的元素就放到最后了,然后我们更新大顶堆,再次将新的大顶堆根节点和倒数第二个节点交换,如此循环直到只剩一个节点,此时整个序列有序















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









