







变长输出模型——Seq2Seq
在上一篇【机器学习】从RNN到Attention上篇 循环神经网络RNN,门控循环神经网络LSTM中,我们的建模基础是通过一串历史的时间序列 x 1 , x 2 , . . . . . , x t x_1,x_2,.....,x_t x1,x2,.....,xt,预测下一时刻的时间序列 x t + 1 x_{t+1} xt+1,即输出为1一个数据。如下图所示:
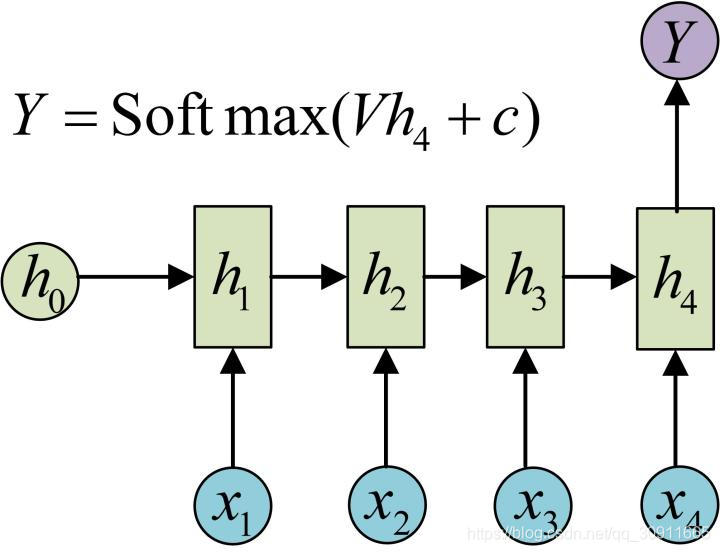
这类模型通常可以用来解决时间序列预测,比如股票预测,或者可以用于时间序列的分类问题,比如情感分析。
事实上RNN最经典的结构是输入一串连续的时间序列数据 x 1 , x 2 , . . . . . , x t x_1,x_2,.....,x_t x1,x2,.....,xt,输入出对应时刻的label y 1 , y 2 , . . . . . , y t y_1,y_2,.....,y_t y1,y2,.....,yt,即N VS N 模型结构,如下图所示。在该模型结构中,输入序列和输出序列必须是等长的。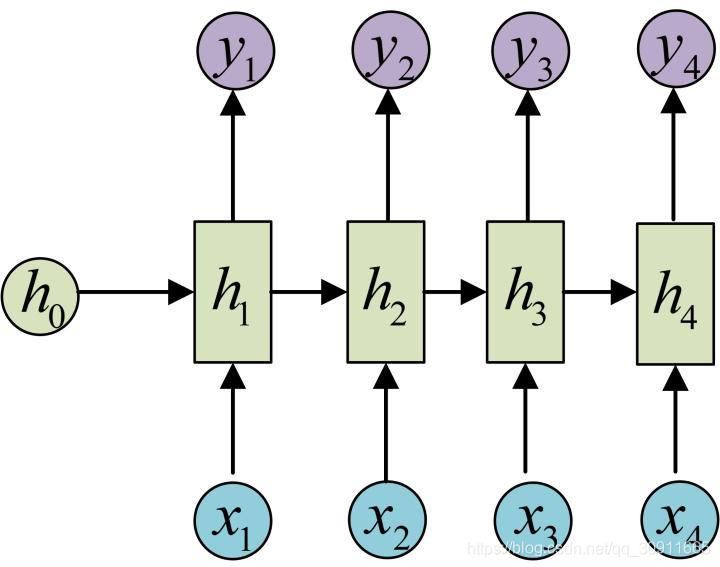
这个模型的一个经典应用是Char RNN。
但是对于一类更广泛的需求:输入序列长度为N,输出序列长度为M。常见的比如机器翻译、语音识别等,都属于上述输入输出不等长的类型,对于这种N VS M类型,上述模型都无能为力。而Seq2Seq模型则是为了解决这类问题而设计的。
Seq2Seq模型又叫Encoder-Decoder模型,事实上我认为Encoder-Decoder更能够表达这个模型的设计思想,即将输入的N的序列编码(Encoder)成一个场景变量(context) C,然后使用一个解码器网络(Decoder)进行解码,其中C作为初始状态h0输入到Decoder中。如下图所示
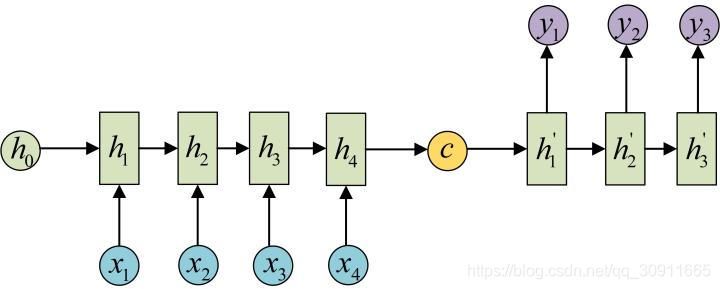
这里存在三个问题:
- 1.C是怎么计算得到的?
C的计算方法有很多种,比如将encoder中的最后一个隐藏层变量 h t h_t ht直接拿出来作为C,即 C = h t C=h_t C=ht,或者将 h t h_t ht做一个矩阵变换 C = W h c t h t C=W_{hct}h_t C=Whctht,也可以将所有的encoder中所有的隐藏层做一个变换 C = W h c [ h 1 , h 2 , . . . . , h t ] C=W_{hc}[h_1,h_2,....,h_t] C=Whc[h1,h2,....,ht],总之C是由网络左侧的encoder网络的隐藏层 h 1 , h 2 , . . . . . , h t h_1,h_2,.....,h_t h1,h2,.....,h
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3467
3467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









