





在您键入一些 C/C++ 源代码和它在 CPU 上执行代码的时间之间,这些代码的内存交互可能会根据某些规则重新排序。内存排序的更改由编译器(在编译时)和处理器(在运行时)进行,目的都是让您的代码运行得更快。
编译器开发人员和 CPU 供应商普遍遵循的内存重排序基本规则可以表述如下:
Thou shalt not modify the behavior of a single-threaded program.
不应修改单线程程序的行为。
由于这条规则,编写单线程代码的程序员基本上不会注意到内存重新排序【memory reordering】。在多线程编程中,它也常常被忽视,因为互斥锁【mutexes 】、信号量【semaphores】和事件【 events,what this?】都旨在防止其调用站点【call sites】周围的内存重新排序。只有使用无锁技术【lock-free techniques】(当线程之间共享内存而没有任何互斥时),才会最终暴露问题,内存重新排序的影响才能被清楚地观察到。
请注意,可以为多核平台编写无锁代码,而无需内存重新排序的麻烦。正如我在无锁编程简介中提到的,可以利用顺序一致的类型【sequentially consistent types】,例如 Java 中的 volatile 变量或 C++11 中的 atomics —— 可能会牺牲一点性能为代价。我不会在这里详细介绍这些。在这篇文章中,我将重点介绍编译器对常规、非顺序一致类型【regular, non-sequentially-consistent types】的内存排序的影响。
Compiler Instruction Reordering
众所周知,编译器的作用是将人类可读的源代码转换为 CPU 可读的机器代码。在此转换过程中,编译器可以自由地采取许多自由措施。
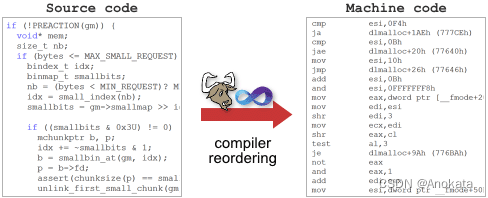
其中一个举措,就是指令重排序。同样,只有在单线程程序行为没有改变的情况下才会发生。这种指令重排序通常仅在启用编译器优化时才会发生。考虑以下函数:
int A, B;
void foo()
{
A = B + 1;
B = 0;
}如果我们使用未进行编译器优化的 GCC 4.6.1 编译此函数,它将生成以下机器代码,我们可以使用 -S 选项将其视为汇编清单【assembly listing】。对全局变量 B 的内存存储【memory store】发生在对 A 的存储【store】之后,就像在原始源代码中一样。
$ gcc -S -masm=intel foo.c
$ cat foo.s
...
mov eax, DWORD PTR _B (redo this at home...)
add eax, 1
mov DWORD PTR _A, eax
mov DWORD PTR _B, 0
...将其与使用 -O2 启用优化后生成的汇编清单进行比较:
$ gcc -O2 -S -masm=intel foo.c
$ cat foo.s
...
mov eax, DWORD PTR B
mov DWORD PTR B, 0
add eax, 1
mov DWORD PTR A, eax
...这次,编译器选择行使自己的自由,将对 A 和 B 的存储顺序进行了重排序。为什么不这样做呢?内存排序的基本规则并没有被打破。单线程程序永远不会知道其中的区别。
另一方面,这种编译器重新排序在编写无锁代码时可能会导致问题。这是一个经常被拿来引用的例子,其中使用共享标志【shared flag】来指示已发布了其他一些共享数据:
int Value;
int IsPublished = 0;
void sendValue(int x)
{
Value = x;
IsPublished = 1;
}想象一下,如果编译将 Value 和 IsPublished 的存储重排序,会发生什么。即使在单处理器系统上,我们也会遇到这样一个问题:一个线程很可能在两个存储之间被操作系统抢占,导致其他线程认为 Value 已更新,而实际上并没有。
当然,编译器可能不会重新排序这些操作,并且生成的机器代码可以在任何具有强内存模型的多核 CPU(例如 x86/64)上作为无锁操作【lock-free operation】正常工作 - 或者在单处理器环境中,任何类型的 CPU 上都可以。如果是这样,我们应该认为自己很幸运。不用说,更好的做法是识别共享变量的内存重排序的可能性,并确保执行正确的排序。
Explicit Compiler Barriers
防止编译器重新排序的最简单方法是使用一个称为编译器屏障的特殊指令。我已经在之前的文章中演示过编译器障碍。以下是 GCC 中的完整的编译器屏障。在 Microsoft Visual C++ 中,_ReadWriteBarrier 也起到了同样的作用。
int A, B;
void foo()
{
A = B + 1;
asm volatile("" ::: "memory");
B = 0;
}通过这一改变,我们可以保持优化处于启用状态,并且内存存储指令将保持所需的顺序。
$ gcc -O2 -S -masm=intel foo.c
$ cat foo.s
...
mov eax, DWORD PTR _B
add eax, 1
mov DWORD PTR _A, eax
mov DWORD PTR _B, 0
...类似地,如果我们希望保证sendMessage示例正常工作,并且只关心单处理器系统,那么至少我们必须在这里引入编译器屏障。不仅发送操作需要一个编译器屏障,以防止存储【store】重排序,而且接收端在加载【load】之间也需要一个编译器屏障。
#define COMPILER_BARRIER() asm volatile("" ::: "memory")
int Value;
int IsPublished = 0;
void sendValue(int x)
{
Value = x;
COMPILER_BARRIER(); // prevent reordering of stores
IsPublished = 1;
}
int tryRecvValue()
{
if (IsPublished)
{
COMPILER_BARRIER(); // prevent reordering of loads
return Value;
}
return -1; // or some other value to mean not yet received
}
正如我所提到的,编译器屏障足以防止单处理器系统上的内存重排序。但现在是 2012 年了,如今,多核计算已成为常态。如果我们想确保我们的交互在多处理器环境中以及在任何 CPU 架构上按期望的顺发生,那么编译器屏障是不够的。我们需要发出 CPU fence 指令,或者执行任何在运行时充当内存屏障的操作。我将在下一篇文章《 Memory Barriers Are Like Source Control Operations》中详细介绍这些内容。
Linux 内核通过预处理器宏(如 smb_rmb)公开了几个 CPU fence 指令,在为单处理器系统编译时,这些宏被简化为简单的编译器屏障。
Implied Compiler Barriers
还有其他方法可以防止编译器重排序。事实上,我刚才提到的 CPU fence 指令也充当了编译器屏障。以下是 PowerPC 的一个 CPU fence 指令示例,在 GCC 中定义为宏:
#define RELEASE_FENCE() asm volatile("lwsync" ::: "memory")在我们的代码中,只要放置 RELEASE_FENCE,它就会阻止某些类型的处理器重排序以及编译器重排序。例如,它可以用于确保我们的 sendValue 函数在多处理器环境中的安全。
void sendValue(int x)
{
Value = x;
RELEASE_FENCE();
IsPublished = 1;
}在新的 C++11(以前称为 C++0x)原子库标准中,每个非宽松原子操作【non-relaxed atomic operation】也充当编译器屏障。
int Value;
std::atomic<int> IsPublished(0);
void sendValue(int x)
{
Value = x;
// <-- reordering is prevented here!
IsPublished.store(1, std::memory_order_release);
}正如您所期望的那样,每个包含编译器屏障的函数本身都必须充当编译器屏障,即使函数是内联的。(然而,微软的文档表明,在早期版本的 Visual C++ 编译器中可能并非如此。啧啧啧!)
void doSomeStuff(Foo* foo)
{
foo->bar = 5;
sendValue(123); // prevents reordering of neighboring assignments
foo->bar2 = foo->bar;
}事实上,大多数函数调用都充当编译器屏障,无论它们是否包含自己的编译器屏障。这不包括内联函数、使用 pure 属性声明的函数以及使用链接时代码生成的情况。除了这些情况之外,对外部函数的调用甚至比编译器屏障更强,因为编译器不知道该函数的副作用是什么。它必须忘记它对该函数可能可见的内存所做的任何假设。
仔细想想,这完全说得通。在上面的代码片段中,假设我们的 sendValue 实现存在于外部库中。编译器如何知道 sendValue 不依赖于 foo->bar 的值?它如何知道 sendValue 不会在内存中修改 foo->bar?它不会知道。因此,为了遵守内存排序的基本规则,它不能对 sendValue 的外部调用周围的任何内存操作进行重排序。同样,它必须在调用完成后从内存中为 foo->bar 加载【load】一个新值,而不是假设它仍然等于 5,即使启用了优化。
$ gcc -O2 -S -masm=intel dosomestuff.c
$ cat dosomestuff.s
...
mov ebx, DWORD PTR [esp+32]
mov DWORD PTR [ebx], 5 // Store 5 to foo->bar
mov DWORD PTR [esp], 123
call sendValue // Call sendValue
mov eax, DWORD PTR [ebx] // Load fresh value from foo->bar
mov DWORD PTR [ebx+4], eax
...正如您所看到的,在许多情况下,编译器指令重排序是被禁止的,甚至当编译器必须从内存中重新加载某些值时也是如此。我相信这些隐藏的规则构成了人们长期以来一直说在正确编写的多线程代码中通常不需要 C 中的 volatile 数据类型的很大一部分原因。
Out-Of-Thin-Air Stores
认为指令重新排序使无锁编程变得棘手?在 C++11 标准化之前,技术上没有任何规则阻止编译器使用更糟糕的技巧。特别是,编译器可以在前面没有存储【store】的情况下,自由地向共享内存引入存储【stores】。这是一个非常简单的示例,灵感来自 Hans Boehm 在多篇文章中提供的示例。
int A, B;
void foo()
{
if (A)
B++;
}虽然在实践中这种情况不太可能发生,但没有什么可以阻止编译器在检查 A 之前将 B 提升到寄存器,从而产生与以下内容等同的机器代码:
void foo()
{
register int r = B; // Promote B to a register before checking A.
if (A)
r++;
B = r; // Surprise! A new memory store where there previously was none.
}再次强调,内存排序的基本规则仍然要遵循。单线程应用程序对此一无所知。但在多线程环境中,我们现在有了一个函数,它可以消除其他线程中对 B 所做的任何并发更改 —— 即使 A 为 0。原始代码没有这样做。这种晦涩难懂的技术上的不可能性,正是人们一直说 C++ 不支持线程的原因之一,尽管几十年来我们一直在用 C/C++ 愉快地编写多线程和无锁代码。
我不知道有谁在实践中成为这种“凭空而来”的存储【store】的受害者。也许只是因为对于我们倾向于编写的无锁代码类型,没有很多适合于这种模式的优化机会。我想如果我发现这种类型的编译器转换正在发生,我会寻找一种方法来让编译器屈服。如果你也遇到过这种情况,请在评论中告诉我。
无论如何,新的 C++11 标准明确禁止编译器在可能引发数据竞争的情况下进行此类行为。最新的 C++11 工作草案的 §1.10.22 及其前后部分中可以找到措辞:
Compiler transformations that introduce assignments to a potentially shared memory location that would not be modified by the abstract machine are generally precluded by this standard.
Why Compiler Reordering?
正如我在开头提到的,编译器修改内存交互顺序的原因与处理器相同——性能优化。此类优化是现代 CPU 复杂性的直接结果。
我可能有点冒险,但我有点怀疑编译器在 80 年代早期是否进行了大量指令重新排序,当时 CPU 最多只有几十万个晶体管。我认为这样做没什么意义。但从那时起,摩尔定律为 CPU 设计人员提供了大约 10000 倍的晶体管数量,这些晶体管被用于诸如流水线、内存预取、ILP 以及最近的多核等技巧。由于其中一些特性,我们已经看到了程序中指令顺序可以对性能产生重大影响的架构。
1993 年发布的首款英特尔奔腾处理器,带有所谓的 U 管和 V 管,是我真正记得人们谈论流水线和指令排序重要性的第一款处理器。不过,最近,当我在 Visual Studio 中逐步执行 x86 反汇编时,我惊讶地发现指令重新排序竟然如此之少。另一方面,在我逐步执行 Playstation 3 上的 SPU 反汇编的过程中,我发现编译器真的很棒。这些只是轶事经验;它可能无法反映其他人的经验,当然也不会影响我们在无锁代码中强制执行内存排序【memory ordering】的方式。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









