









mapreduce深入学习
- 特定
吞吐能力强 强大数据处理能力
hadoop Streaming 支持java python 等语言透明 执行过程
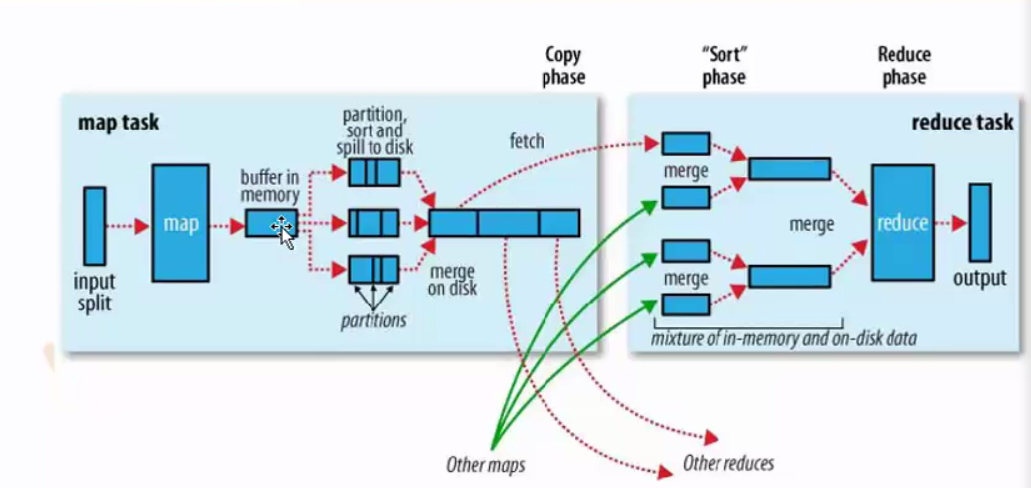
执行流程图
a.数据->map->内存->磁盘小文件(按k排序)->大文件( )
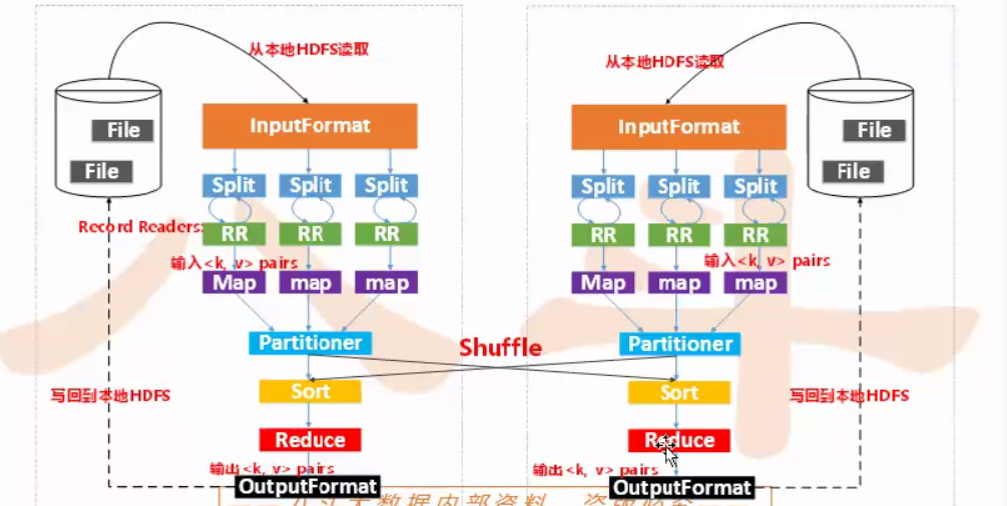
File: hdfs的文件切成默认64m的block存储在datanode上
##开始map读入:
1.inputFormat 数据分割 :数据块进行切割
split 包含完整句子 被切割的的句子跨越存儲在前一個split
记录读取 :recordReader
記錄 ” hello world/n”作爲參數v,map(v)沒讀取一條記錄,調用一次map,知道split結尾
储存在Map上:
map(v)接收到数据,map(“helloworld”),会在内存中增加数据, 对句子做分词输出如下:(分词逻辑需要开发代码处理)
{“hello”:1}
{“world”:1}
mapreduce的经典shuffle:
partion :就决定数据是由哪个Reducer处理,从而分区
比如采用hash发,n个Reducer,那么数据{“hello”:1}的”hello”对n进行取模,根据patition来发送到不同的reduce节点上去
sort:按照k排序 Spill每次spill都形成小的文件,根据阈值溢写
meger combiner:数据合并相同k的累加数据Copy memery Disk…
这里可以做大量性能优化
Reduce:
mapreduce的物理配置:
文件句柄个数:ulimit
cpu:多核
内存:8g以上
合适的slot(默认2个slot,自己配置cpu-1):
-单机map reduce个数
-内存限制
-cpu核数-1
-多机集群分离
磁盘情况:
-合适的单机磁盘
-mapred.local.dir和dfs.data.dir
配置加载问题:
简单配置 通过-file分发
-较大配置
传入hdfs
map中打开文件读取
建立内存结构
map个数为split个数
压缩文件不可切分
非压缩文件和sequ文件可以切分
dfs block。size决定block大小
例程 mapreducer统计文章中英文单词出现的个数
centos6.5
新建一个工作目录:
mkdir mds
touch map.py 新建空文件
vim map.py
开始编辑
拷贝目标文件到本目录
import sys
for line in sys.stdin:
ss=line.strip().split(’ ‘)格式化 空格分割
for word in ss:
print ‘\t’.join([word.strip,’1’])每个单词value值为1
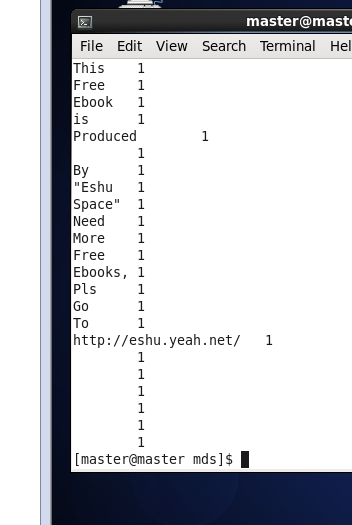
vim red.py
完整代码:
import sys
Cur_word=None
sum=0
for line in sys.stdio:
word,cnt = line.strip().split(' ')
if cur_word == None:
cur_word = word
id cur_word != word:
print '\t'.join([cur_word,str(sum)])
cur_word = word
sum = 0
sum += int(cnt)
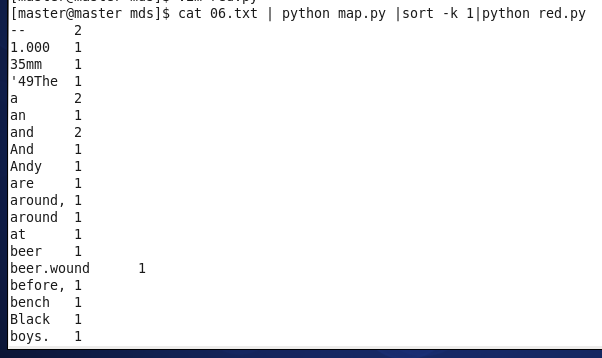
下面运行:
cat 06.txt | python map.py | sort -k l | python red.py
ok
排序完成














 2676
2676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









