







 Qwen是一个旨在实现通用人工智能的项目,包括基础语言模型、聊天模型、编程模型和数学模型等。它使用Transformer架构,通过预训练和后训练(SFT、RLHF)进行对齐。Qwen不仅关注多语言处理,还扩展到了视觉和音频领域。然而,有时可能无法从HuggingFace获取模型和代码。
Qwen是一个旨在实现通用人工智能的项目,包括基础语言模型、聊天模型、编程模型和数学模型等。它使用Transformer架构,通过预训练和后训练(SFT、RLHF)进行对齐。Qwen不仅关注多语言处理,还扩展到了视觉和音频领域。然而,有时可能无法从HuggingFace获取模型和代码。
LLM——Qwen
Qwen不仅仅是一个语言模型,而是一个致力于实现通用人工智能(AGI)的项目。
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
“Qwen” 指的是基础语言模型,而 “Qwen-Chat” 则指的是通过后训练技术如SFT(有监督微调)和RLHF(强化学习人类反馈)训练的聊天模型。我们还有提供了专门针对特定领域和任务的模型,例如用于编程的 “Code-Qwen” 和用于数学的 “Math-Qwen”。大型语言模型(LLM)可以通过模态对齐扩展到多模态,因此我们有视觉-语言模型 “Qwen-VL” 以及音频-语言模型 “Qwen-Audio” 。
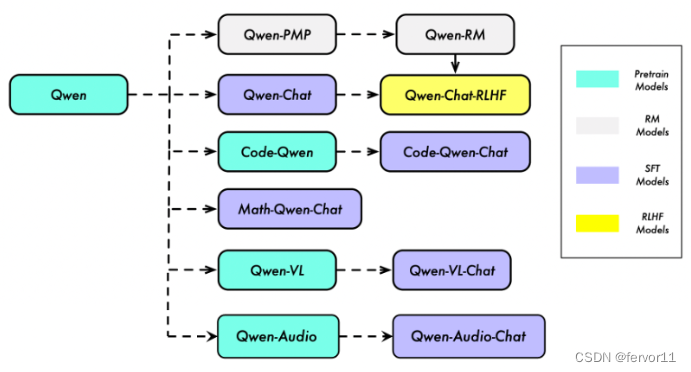
一、基础模型
Qwen是一个基于Transformer的语言模型,通过预测下一个词的任务进行预训练。构建助手模型的一般流程包括预训练和后训练,后者主要由SFT(有监督微调)和RLHF(强化学习人类反馈)组成。预训练数据是多语言的,Qwen本质上是一个多语言模型,由于采用了一种在编码不同语言信息方面具有高效率的分词器。与其他分词器相比,Qwen的分词器在一系列语言中展示了高压缩率。预训练的另一个重点是扩展上下文长度。我们直接应用了具有更长上下文长度和更大基数值的RoPE(旋转位置编码)的持续预训练。
二、对齐
将后训练涉及的两种技术(SFT,RLHF)统称为“对齐”。可以通过相对较少量的微调数据获得一个聊天模型。Qwen专注于提高SFT数据的多样性和复杂性(如instag和tulu 2),并通过人工检查和自动评估严格控制质量。 基于一个良好的SFT模型,我们可以进一步探索RLHF的效果。特别是基于PPO(近端策略优化)的方法,但训练RLHF是困难的。除了PPO训练的不稳定性之外,另一个关键是奖励模型的质量。因此,在构建可靠的奖励模型上进行了大量努力,通过在大规模偏好数据上进行奖励模型预训练,以及在精心标记的高质量偏好数据上进行微调。与SFT模型相比,经过RLHF的模型更具创造性,更好地遵循指令,因此其生成的回复更受人类评注者的青睐。
三、应用
代码如下(权重下载):
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# 可选的模型包括: "Qwen/Qwen-7B-Chat", "Qwen/Qwen-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 打开bf16精度,A100、H100、RTX3060、RTX3070等显卡建议启用以节省显存
# model  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









