







原文:http://cs229.stanford.edu/notes/cs229-notes2.pdf
在GDA中,特征向量x是连续的实数向量。现在让我们来谈谈一种不同的学习算法,其中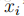
对于我们的引入示例,考虑使用机器学习构建一个电子邮件垃圾邮件过滤器。在这里,我们希望根据是否是垃圾邮件,或非垃圾电子邮件进行分类。在学习了这一点之后,我们就可以让我们的邮件阅读器自动过滤掉垃圾邮件,或者将它们放在一个单独的邮件文件夹中。电子邮件分类是一个更广泛的问题集,称为文本分类的一个例子。
假设我们有一个训练集(一组被标记为垃圾邮件或非垃圾邮件的电子邮件的集合)。我们将通过指定用于表示电子邮件的特性
我们将通过一个特征向量表示电子邮件,其长度等于词典中的单词数。具体来说,如果电子邮件包含字典的第一个单词,那么我们将设置

用于表示包含“a”和“Buy”字样的电子邮件,但不包含“aardvark”、“aardWolf”或“zygmurgy”。这些编码到特征向量中的单词集合被称为词汇表,所以x的维数等于词汇表的大小。
在选择了特征向量之后,我们现在想要建立一个判别模型。所以,我们必须对p(x|y)建模。但如果我们有一个50000字的词汇表,那么x∈{0,1}^50000(x是0和1的50000维向量),如果我们在2个50000个可能的结果上用多项式分布明确地表示X,那么我们将得到一个(2^50000-1)维参数向量。这显然是太多的参数。
为了对p(x|y)建模,因此,我们将作出非常有力的假设。我们将假设在给定y的情况下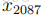
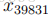
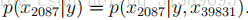
我们现在有

第一个等式是从概率的一般性质出发的,第二个等式采用NB假设。我们注意到,尽管朴素Bayes假设是一个非常强的假设,但所得到的算法在许多问题上都能很好地工作。
我们的模型是由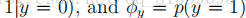
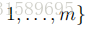
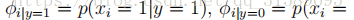
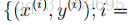
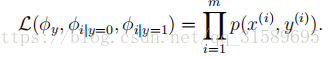
对于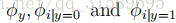
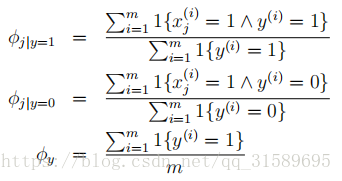
在上面的方程式中,“∧”符号的意思是“and”。这些参数具有非常自然的解释。例如,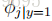
在对所有这些参数进行拟合之后,为了对一个新的具有特征x的例子进行预测,我们简单地计算了一下。
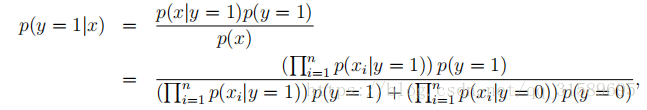
选择具有较高后验概率的类别。
最后,我们注意到,虽然我们主要针对特征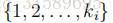
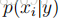
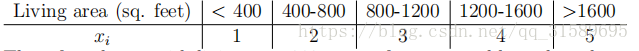
因此,对于居住面积为890平方英尺的房子,我们会将相应的特征值设为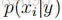














 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









