







秋招复习笔记系列目录(不断更新中):
- 1.数据结构全系列
- 2.计算机网络知识整理(一)
- 3.计算机网络知识整理(二)
- 4. Java虚拟机知识整理
- 5.计算机操作系统
- 6.深入理解HashMap
- 7.深入理解ConcurrentHashMap
- 8.MySQL
继续来分享自己的整理的MySQL的知识。本篇博客主要是自己在看 《高性能MySQL》 的过程中做的笔记,其中夹杂着一些对一些知识的深入的解释,这些解释大多是从别人的博客中搬运过来综合整理后得到的,这部分内容的来源会在文中标注出来,建议大家支持原作者,我这里搬运过来主要是为了以后看着方便不用在网页间跳来跳去。
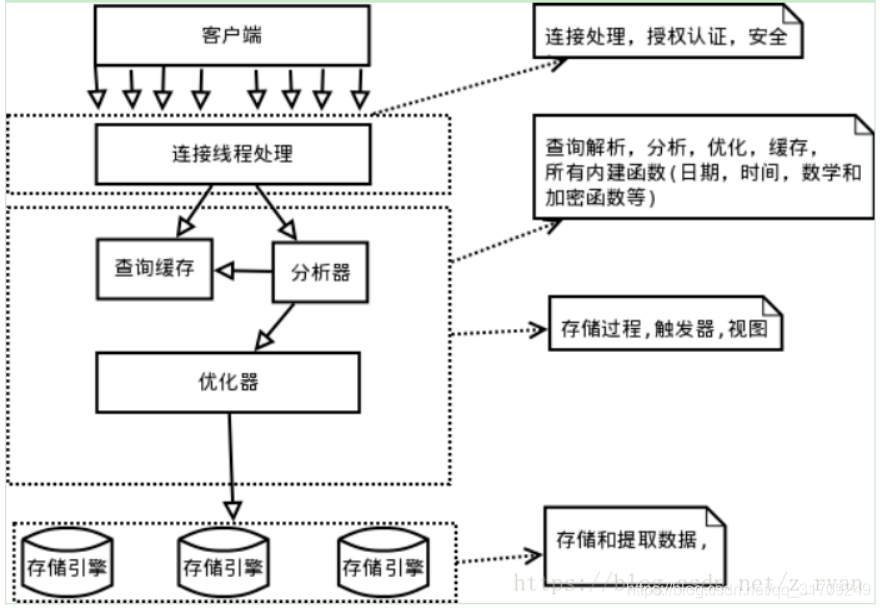
一、MySQL的逻辑架构
1.1 逻辑架构
MySQL的逻辑架构分为三层:
- ① 第一层主要负责连接管理和安全性:每个客户端连接在服务器中都拥有一个线程;当客户端连接到MySQL服务器时,服务器会对其进行用户名密码、证书、权限等的一系列认证
- ② 第二层包含所有跨存储引擎的功能,以及缓存查询、分析器、优化器:查询时,MySQL会解析查询,创建解析树,然后对其进行各种优化。同时,对
SELECT语句,解析查询前服务器会先检查缓存(要查询语句完全一致,所以命中率不高)。 - ③ 第三层为存储引擎层
1.2 并发控制
1.读写锁
读锁是共享的,互不阻塞,多个用户在同一时刻可以同时读取某个资源而互不干扰。写锁是排他的,写锁会阻塞其他的写锁和读锁。
2.锁粒度
为了考虑并发性能,需要综合锁的开销和数据的安全性。MySQL有多种锁粒度的选择:
- 表锁: 锁住整张表,开销最小,并发性最差,适合只读
- 行锁: 可以最大程度支持并发处理,但锁的开销和很高
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xZ6o6S8Q-1594904003466)(高性能MySQL.assets/20180524150747385.png)]](https://img-blog.csdnimg.cn/20200716205751894.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMxNzA5MjQ5,size_16,color_FFFFFF,t_70)
3.显式和隐式锁定
在存储引擎中,会根据隔离级别,自动地进行隐式锁定,但是也可以设置显式锁定(第一行是共享锁,第二行是排它锁):

上面的两个语句是在事务内起作用的,所涉及的概念是行锁。它们能够保证当前session事务所锁定的行不会被其他session所修改(这里的修改指更新或者删除)。两个语句不同的是,一个是加了共享锁而另外一个是加了排它锁.
4. 间隙锁
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w5ZpoTX0-1594904003469)(高性能MySQL.assets/20180524180339289.png)]](https://img-blog.csdnimg.cn/20200716205845709.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMxNzA5MjQ5,size_16,color_FFFFFF,t_70)
示例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lPgfdDho-1594904003472)(高性能MySQL.assets/20180524180309663.png)]](https://img-blog.csdnimg.cn/20200716205901875.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMxNzA5MjQ5,size_16,color_FFFFFF,t_70)
为了防止间隙锁,锁的力度应该尽可能小,选择时要尽可能精细选择。
1.3 多版本并发控制(摘抄于这篇博客)
1. redo log 和 undo log
(1) redo log
对数据的修改操作会先直接修改内存中的 Page,但这些页不会立刻同步磁盘,这时内存中的数据已经和磁盘上的不一致了,我们称这种 Page 为脏页。为了保证数据的安全性,在修改内存中的 Page 之后 InnoDB 会写 redo log,然后,InnoDB 会在事务提交前将 redo log 保存到磁盘中。这里所说的 redo log 是物理日志而非逻辑日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
(2) undo log
与 redo log 不同,undo log 一般是逻辑日志,根据每行记录进行记录。例如当 DELETE 一条记录时,undo log 中会记录一条对应的 INSERT 记录,反之亦然当 UPDTAE 一条记录时,它记录一条对应反向 UPDATE 记录。通过 undo log 一方面可以实现事务回滚,另一方面可以根据 undo log 回溯到某个特定的版本的数据,实现 MVCC 的功能。
redo log 由两部分组成,一部分是内存中的 redo log buffer,这部分是易失的,重启就没了;二是磁盘上的 redo log file,是持久化的。
InnoDB 通过 force log at commit 技术来实现事务的持久化特性。为了保证每次 redo log 都能写入磁盘上的日志文件中,每次将内存中的 redo log buffer 内容同步磁盘时都会调用一次 fsync。
2. 实现机制
InnoDB在每行数据都增加三个隐藏字段,一个唯一行号,一个记录创建的版本号,一个记录回滚的版本号:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZzLuRFvh-1594904003475)(高性能MySQL.assets/20190708105553500.png)]](https://img-blog.csdnimg.cn/20200716211000374.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMxNzA5MjQ5,size_16,color_FFFFFF,t_70)
其中:
- DB_TRX_ID:用来标识用来标识最近一次对本行记录做修改(insert|update)的事务的标识符,即最后一次修改(insert|update)本行记录的事务id。至于delete操作,在innodb看来也不过是一次update操作,更新行中的一个特殊位将行表示为deleted,并非真正删除。
- DB_ROLL_PTR:表示指向该行回滚段
(rollback segment)的指针,大小为7个字节,InnoDB便是通过这个指针找到之前版本的数据。该行记录上所有旧版本,在undo中都通过链表的形式组织。 - DB_ROW_ID:包含一个随着新行插入而单调递增的行ID,当由innodb自动产生聚集索引时,聚集索引会包括这个行ID的值,否则这个行ID不会出现在任何索引中。
上文提到,在多个事务并行操作某行数据的情况下,不同事务对该行数据的 UPDATE 会产生多个版本,然后通过回滚指针组织成一条 Undo Log 链。事务 A 对值 x 进行更新之后,该行即产生一个新版本和旧版本。假设之前插入该行的事务 ID 为 100,事务 A 的 ID 为 200,该行的隐藏主键为 1。
事务 A 的操作过程为:
- 对
DB_ROW_ID = 1的这行记录加排他锁 - 把该行原本的值拷贝到
undo log中,DB_TRX_ID和DB_ROLL_PTR都不动 - 修改该行的值这时产生一个新版本,更新
DATA_TRX_ID为修改记录的事务ID,将DATA_ROLL_PTR指向刚刚拷贝到undo log链中的旧版本记录,这样就能通过DB_ROLL_PTR找到这条记录的历史版本。如果对同一行记录执行连续的UPDATE,Undo Log会组成一个链表,遍历这个链表可以看到这条记录的变迁 - 记录
redo log,包括undo log中的修改
那么 INSERT 和 DELETE 会怎么做呢?其实相比 UPDATE 这二者很简单,INSERT 会产生一条新纪录,它的 DATA_TRX_ID 为当前插入记录的事务 ID;DELETE 某条记录时可看成是一种特殊的 UPDATE,其实是软删,真正执行删除操作会在 commit 时,DATA_TRX_ID 则记录下删除该记录的事务 ID。
3. 如何实现一致性读——ReadView
在 RU 隔离级别下,直接读取版本的最新记录就 OK,对于 SERIALIZABLE 隔离级别,则是通过加锁互斥来访问数据,因此不需要 MVCC 的帮助。因此 MVCC 运行在 RC 和 RR这两个隔离级别下,当 InnoDB 隔离级别设置为二者其一时,在 SELECT 数据时就会用到版本链。InnoDB 为了解决这个问题,设计了 ReadView(可读视图)的概念。ReadView是事务开启时,当前所有事务的一个集合(理解这句话),这个数据结构中存储了当前ReadView中最大的ID及最小的ID
(1) RR下ReadView的生成
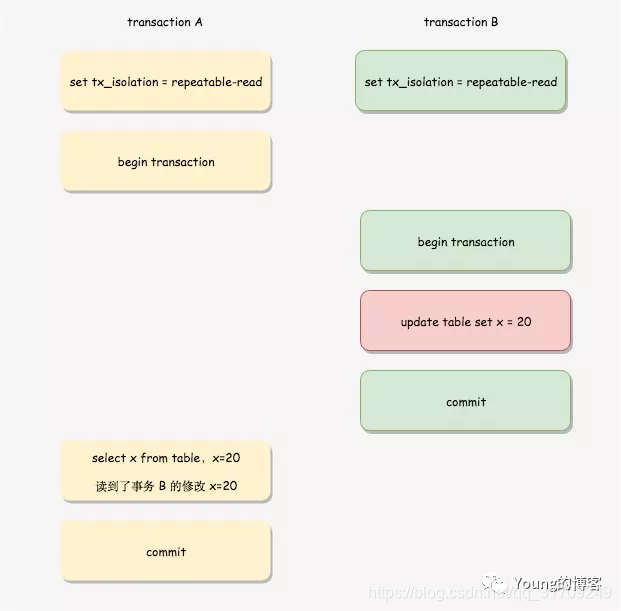
在 RR 隔离级别下,每个事务 touch first read 时(本质上就是执行第一个 SELECT语句时,后续所有的 SELECT 都是复用这个 ReadView,其它 update, delete, insert 语句和一致性读 snapshot 的建立没有关系),会将当前系统中的所有的活跃事务拷贝到一个列表生成ReadView。
下图中事务 A 第一条 SELECT 语句在事务 B 更新数据前,因此生成的 ReadView 在事务 A 过程中不发生变化,即使事务 B 在事务 A 之前提交,但是事务 A 第二条查询语句依旧无法读到事务 B 的修改。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MUZqzqT8-1594904003477)(高性能MySQL.assets/image-20200627222502865.png)]](https://img-blog.csdnimg.cn/20200716211221191.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMxNzA5MjQ5,size_16,color_FFFFFF,t_70)
下图中,事务 A 的第一条 SELECT 语句在事务 B 的修改提交之后,因此可以读到事务 B的修改。但是注意,如果事务 A 的第一条 SELECT 语句查询时,事务 B 还未提交,那么事务 A 也查不到事务 B 的修改
(2) RC下ReadView的生成
在 RC 隔离级别下,每个 SELECT 语句开始时,都会重新将当前系统中的所有的活跃事务拷贝到一个列表生成 ReadView。二者的区别就在于生成 ReadView 的时间点不同,一个是事务之后第一个 SELECT 语句开始、一个是事务中每条 SELECT 语句开始。
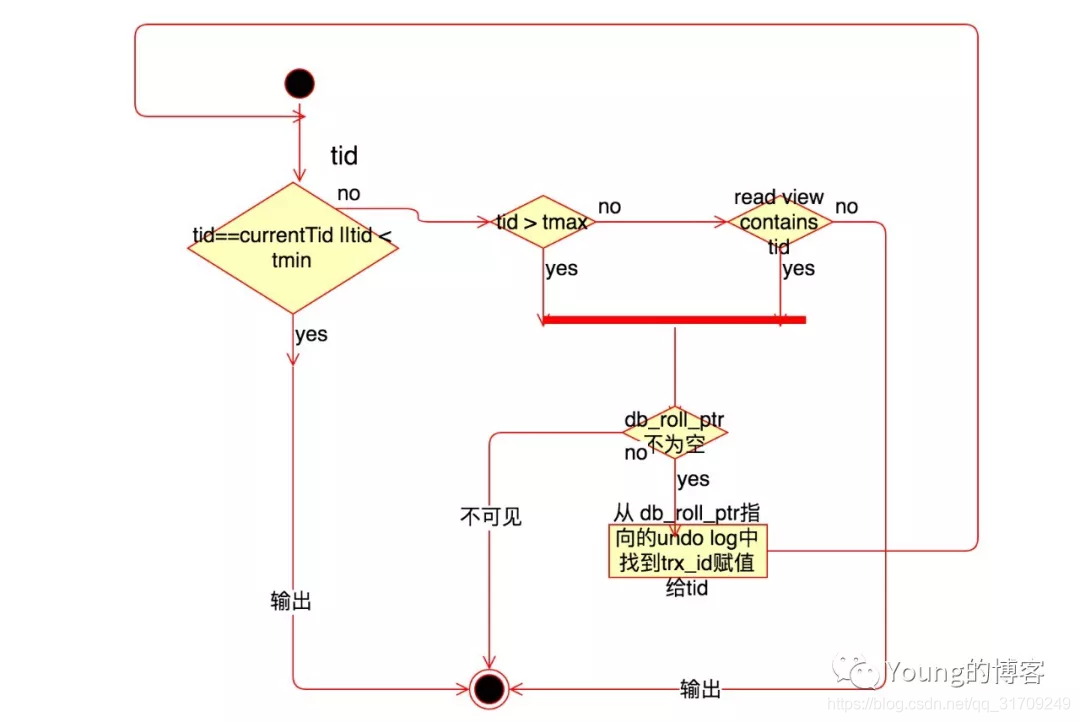
ReadView 中是当前活跃的事务 ID 列表,称之为 m_ids,其中最小值为 up_limit_id,最大值为 low_limit_id,事务 ID 是事务开启时 InnoDB 分配的,其大小决定了事务开启的先后顺序,因此我们可以通过 ID 的大小关系来决定版本记录的可见性,具体判断流程如下:
-
如果被访问版本的
trx_id小于m_ids中的最小值up_limit_id,说明生成该版本的事务在ReadView生成前就已经提交了,所以该版本可以被当前事务访问。 -
如果被访问版本的
trx_id大于m_ids列表中的最大值low_limit_id,说明生成该版本的事务在生成ReadView后才生成,所以该版本不可以被当前事务访问。需要根据Undo Log链找到前一个版本,然后根据该版本的 DB_TRX_ID 重新判断可见性。 -
如果被访问版本的
trx_id属性值在m_ids列表中最大值和最小值之间(包含),那就需要判断一下trx_id的值是不是在m_ids列表中。如果在,说明创建ReadView时生成该版本所属事务还是活跃的,因此该版本不可以被访问,需要查找 Undo Log 链得到上一个版本,然后根据该版本的DB_TRX_ID再从头计算一次可见性;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。 -
此时经过一系列判断我们已经得到了这条记录相对
ReadView来说的可见结果。此时,如果这条记录的delete_flag为true,说明这条记录已被删除,不返回。否则说明此记录可以安全返回给客户端。
1.4 事务
1. ACID
良好事务处理系统,必须具备ACID特征:
- 原子性: 事务是不可分割的最小工作单元,一个事务要么成功,要么失败
- 一致性: 数据库总是从一个一致状态转到另一个一致状态。
- 隔离性: 一个事务中的操作在提交前在另一个事务中不可见
- 持久性: 一旦事务提交,其所作的更改就会永久保存到数据库中
2. 并发带来的问题
- 脏读: 当一个事务允许读取另一个事务修改但未提交的数据时,就可能发生脏读。
- 不可重复读: 一个事务读取某一记录后,该数据被另一个事务修改提交,再次读取该记录时结果发生了改变
- 幻读: 一个事务第一次读取数据后,另一个事务增加或者删除了某些数据,再次读取时结果的数量发生了变化。
- 更新丢失: 第一类:当两个事务更新相同的数据时,如果第一个事务被提交,然后第二个事务被撤销;那么第一个事务的更新也会被撤销。第二类:当两个事务同时读取某一记录,然后分别进行修改提交;就会造成先提交的事务的修改丢失。
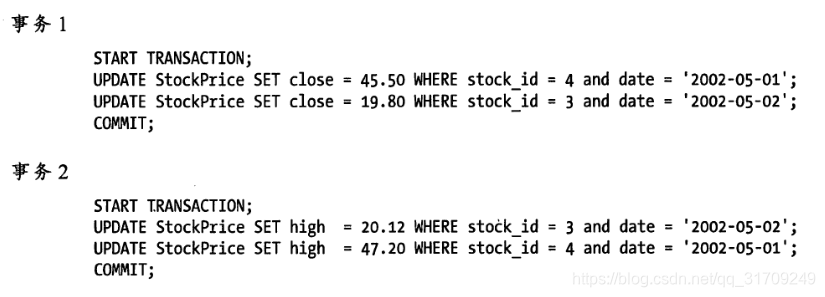
3. 事务的隔离级别
- 读未提交: 级别最低,不能避免脏读
- 读提交: 能避免脏读,不能避免不可重复读
- 可重复读: 能避免不可重复读,但不能避免幻读,InnoDB通过间隙所来防止幻读
- 串行化: 能避免幻读
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OCSM1vPB-1594904003480)(高性能MySQL.assets/1586874561200.png)]](https://img-blog.csdnimg.cn/20200716212154435.png)
4. 死锁
指两个或多个事务在同一资源上相互占用,并请求锁定对方占用的资源,谁都不释放,导致恶性循环。解决这种问题的方式,一种是死锁检测,另一个是死锁超时。
1.5 存储引擎
1. InnoDB引擎
-
数据存储在表空间tablespace中,表空间中又分为Segment、Extent、page
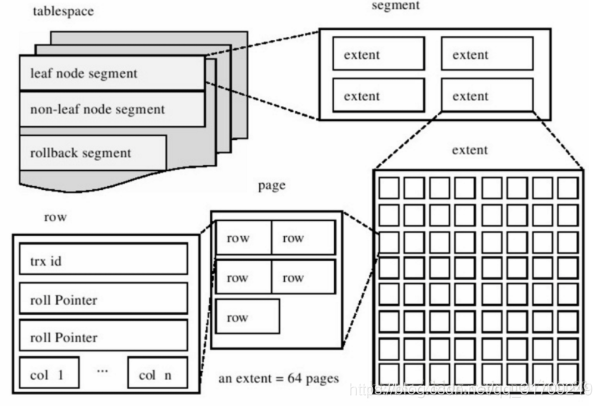
-
支持事务,通过MVCC来实现乐观锁,通过行锁实现悲观锁,间隙锁防止部分幻读
-
基于聚簇索引建立,聚簇索引对主键的查询有很高的性能,但是二级索引必须包含主键,查询二级索引后,需要回表去聚簇索引中查
2. MyISAM
- 不支持事务和行级锁,只支持表锁
- MyISAM将表存在两个文件中:数据文件(扩展名
.MYD)和索引文件(扩展名.MYI) ,表可存储的行记录数,一般受限于可用的磁盘空间或者操作系统中单个文件的最大尺寸 - 支持全文索引
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YkKTcrhw-1594904003481)(高性能MySQL.assets/image-20200703143252880.png)]](https://img-blog.csdnimg.cn/20200716212245478.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMxNzA5MjQ5,size_16,color_FFFFFF,t_70)
二、Schema与数据类型优化
2.1 数据类型优化
-
更小的通常更好: 使用可以正确存储数据的最小数据类型
MySQL中的数据类型可以分为:整型(tinyint、smallint、mediumint、bigint、int)、浮点型(double、float、DECIMAL)、字符串(char和varchar)、日期(date、time、datetime、timestamp(自动存储记录修改时间))、二进制几个大类。
-
简单就好: 尽量用简单的数据类型,能用整型的就不用字符串
-
尽量避免NULL: 最好设置列值为
NOT NULL,除非真的需要NULL值 -
使用枚举代替字符串类型: 枚举可以防止重复的存储相同的字符串

2.2 范式和反范式
1.三范式
- ①第一范式: 每一个列都是原子的,不可再分
- ②第二范式: 没有包含在主键中的列必须全部依赖于全部主键,而不能只依赖于主键的一部分而不依赖全部主键
- ③第三范式: 不能存在传递依赖,即不能存在:非主键列m既依赖于全部主键,又依赖于非主键列n的情况
2. 范式的优缺点
- 优点: 更新操作通常更快、冗余数据少
- 缺点: 通常需要大量的表关联,代价太大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 106
106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











