







居然被问到MR,好久没写MR了,此处凭借记忆和手记整理
一 、大数据去重
1. 以wc举例,来说明MR的过程
StringTokenizer(String str) :构造一个用来解析 str 的 StringTokenizer 对象。java 默认的分隔符是空格("")、制表符(\t)、换行符(\n)、回车符(\r)。
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
IntWritable one = new IntWritable(1);
Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException,InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,InterruptedException {
int sum = 0;
for(IntWritable val:values) {
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}2. 大数据去重
题目
/**
* 题目:数据去重
* 解题思路:将每行数据作为key值,value值为空
* 2020-3-1 a
2020-3-2 b
2020-3-3 c
2020-3-4 d
2020-3-5 a
2020-3-6 b
2020-3-7 c
2020-3-3 c
2020-3-1 b
2020-3-2 a
2020-3-3 b
2020-3-4 d
2020-3-5 a
2020-3-6 c
2020-3-7 d
2020-3-3 c
*/2.1 当然此题可以用SQL:数据导入Hive,group by
2.2 MR编程实现 map中 Value作为key写出;reduce中k-k写出
public class RemoveDupData {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJar("wordcountJar/wordcount.jar");
job.setMapperClass(RemoveDupDataMapper.class);
job.setReducerClass(RemoveDupDataReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
Path inputPath = new Path("input/RemoveDupData");
Path outputPath = new Path("output/RemoveDupData");
if(fs.isDirectory(outputPath)){
fs.delete(outputPath,true);
}
FileInputFormat.setInputPaths(job,inputPath);
FileOutputFormat.setOutputPath(job,outputPath);
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1 );
}
public static class RemoveDupDataMapper extends Mapper<LongWritable,Text,Text,NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
public static class RemoveDupDataReducer extends Reducer<Text,NullWritable,Text,NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
}3. 两个文件求相同字符串
3.1 如果文件不是特别大
读第一个文件,加入hashset,
读第二个文件,如果hashset中包含(contains),输出。3.2 如果文件比较大
1.ab两个文件mapreduce 去重追加输出为文件c
2.mapreduce 统计文件c次数出现为2的,输出
二 、MR的执行过程
网上看到一张图片,细品,贼有意思,分享给大家 ~
双击可点开查看大图
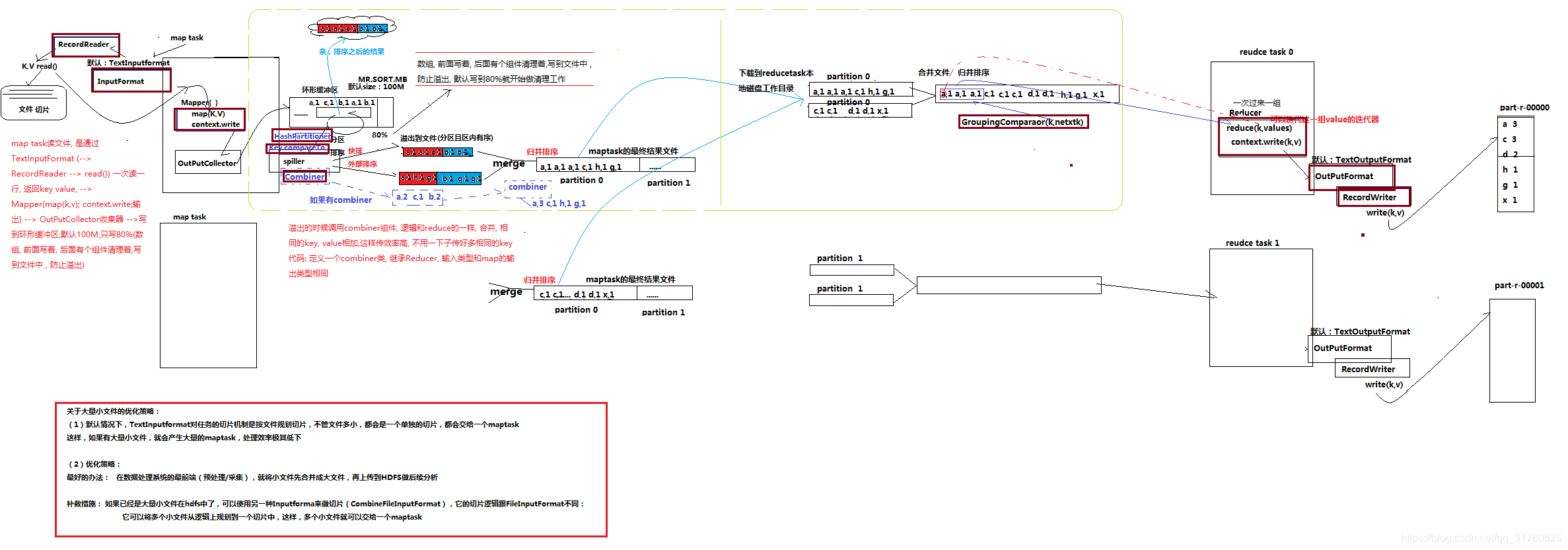
问题1 在Map任务和Reduce任务的过程中,一共发生了几次排序 ? 3次
1)环形缓冲区的每个分区按键排序。
当map函数产生输出时,会首先写入内存的环形缓冲区,当达到设定的阀值,在刷写磁盘之前,后台线程会将缓冲区的数据划分成相应的分区。
在环形缓冲区的每个分区中,后台线程按键进行内排序.
2)溢写文件归并排序。
在Map任务完成之前,磁盘上存在多个已经分好区,并排好序的,大小和缓冲区一样的溢写文件。
这时溢写文件将被合并成一个已分区且已排序的输出文件。
由于溢写文件已经经过第一次排序,所有合并文件只需要再做一次排序即可使输出文件整体有序。
3)reduce阶段归并多个map任务的输出文件。
在reduce阶段,需要将多个Map任务的输出文件copy到ReduceTask中后合并。
由于经过第二次排序,所以合并文件时只需再做一次排序即可使输出文件整体有序
在这3次排序中第一次是内存缓冲区做的内排序,使用的算法使快速排序,
第二次排序和第三次排序都是在文件合并阶段发生的,使用的是归并排序。














 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









