








思维导读已同步至git,视频文件同步至公众号 可获取
hadoop-shell
- 调用文件系统(FS)Shell命令应使用 bin/hadoop fs 的形式。
- 所有的FS shell命令使用URI路径作为参数。
URI格式是scheme://authority/path。HDFS的scheme是hdfs,对本地文件系统,scheme是file。其中 scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。
例如:/parent/child 可以表示成hdfs://namenode:namenodePort/parent/child
或者更简单的/parent/child(假设配置文件是namenode:namenodePort)
- 大多数FS Shell命令的行为和对应的Unix Shell命令类似。\
NameNode
是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
NameNode 工作特征
- Namenode始终在内存中保存metedata,用于处理“读请求”
- 到有“写请求”到来时,namenode会首先写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回
- Hadoop会维护一个fsimage文件,也就是namenode中 metedata 的镜像,但是fsimage不会随时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。Secondary namenode就是用来合并fsimage和edits文件来更新NameNode的metedata的。
SecondaryNameNode
HA的一个解决方案。但不支持热备。配置即可。
执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage.
默认在安装在NameNode节点上,但这样…不安全!
元数据
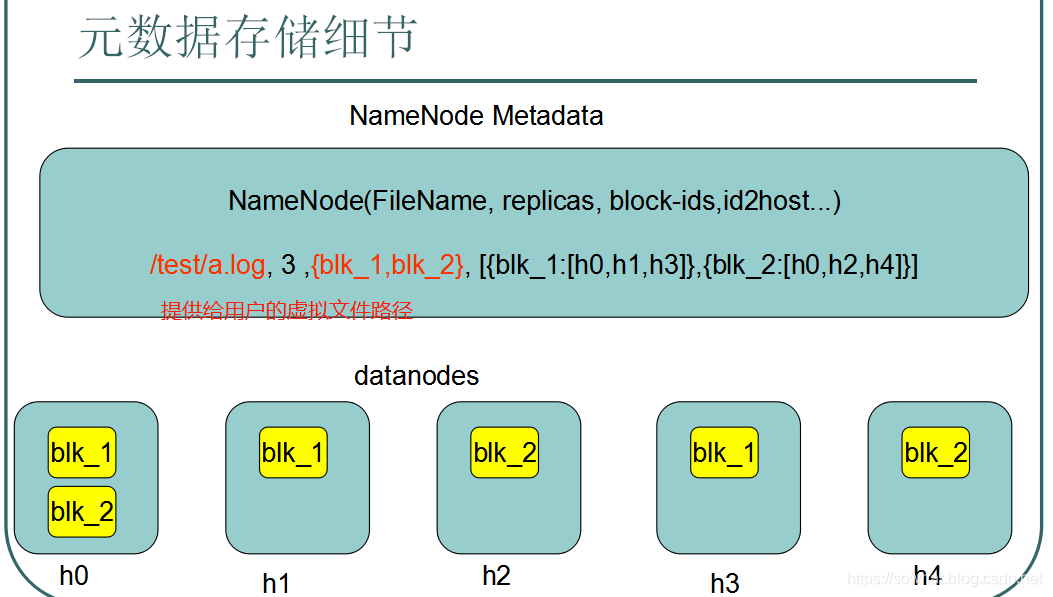
数据的存入跟读出时候大概步骤
client 比如将一个大文件切分为BLK01、BLK02、BLK03 然后调用API 进行在DN存储
- 一个BLK 通过客户端存3份算成功,这种易出错,写的次数太多,这种方法不用。
- 一个BLK 通过客户端存1份算成功,后台有异步的DN 进程来实现BLK 备份到不同节点上,如果失败由NN 来实现失败BLK的备份 重试。(DataNode,NameNode)
- 如果存入太多 4~5M的 文件到 DN 上,那么DN 上是没问题的,问题是 NN 是存储 关联关系的,会浪费元数据空间。
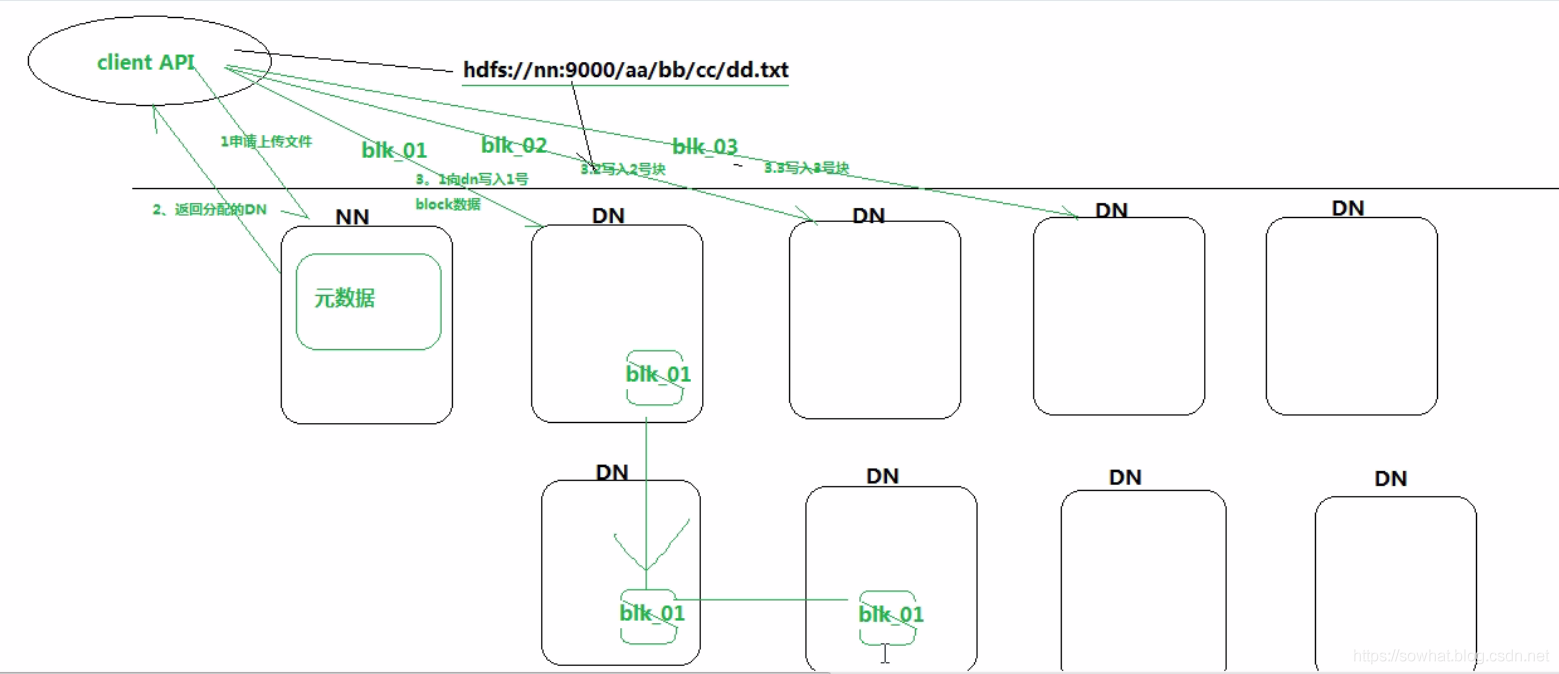
NameNode 之 元数据操作细节
- 客户端发送上传文件请求
- NN 检查是否可存储 以及存储后文件的具体信息,比如存到那个DN。将信息存到 一个固定大小(比如4M 存储最新的)edits_log 文件中
- NN 处理完后将 上一步存储信息返回给客户端。
- 客户端开始根据上一步信息进行文件存储。
- 上一步文件存储成功了告知NN,
- NN根据上一步成功信息将 edits_log 最新信息存入到内存中。以此保证内存查询最全数据信息。
- 比如内存中元数据跟fsimage 中元数据 完全一致 都是10M,接下来 新添加了4M元数据信息,则edits_log 大小为4M,内存中大小为14M,而fsimage为10M,此时根据edits_log文件的信息同步到fsimage
- checkpoint(跟神经网络训练一样 规则性备份) 每当edits_log 写满时,要将这一段时间的新元数据 flash 到fsimage中 。fsimage = edits_log + fsimage。然后清空edits_log
- edits_log 是日志,fsimage是元数据,合并的时候要先预处理edits_log 这样的话又耗费到内存空间。
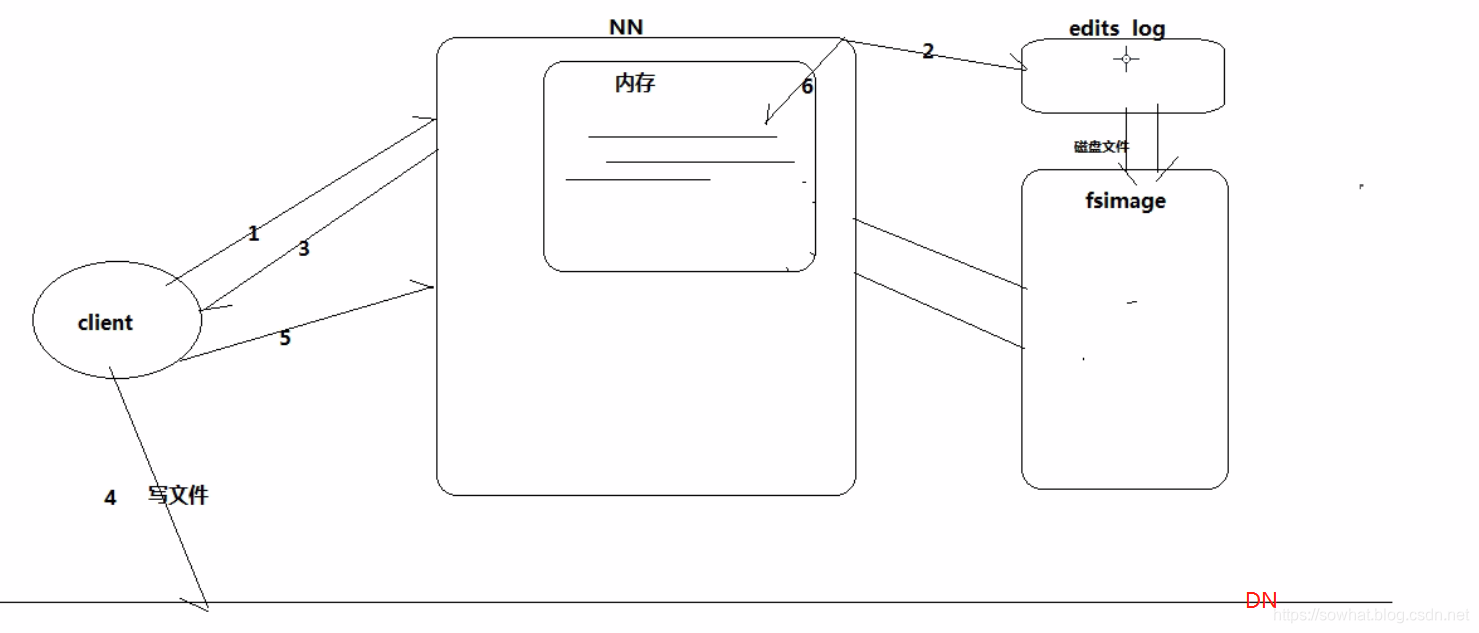
什么时候checkpiont(hdfs-site.xml)
- fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒。
- fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔。默认大小是64M。
元数据合并(checkpoint)细节
当 edits满了步骤
- NN(NameNode) 通知SN (Secondary NameNode)进行checkpoint。
- SN告知NN 准备好了,停止往edits文件写文件。
- 然后再NN 备份期间用edits.new 先用。
- SN 将NN 中fsimage 跟edits拷贝过来。
- 在SN 中进行合并,生成fsimage.chkpoint
- 上一步生成的文件 上传到NN, 进行替换。
- edits.new 变为edits。
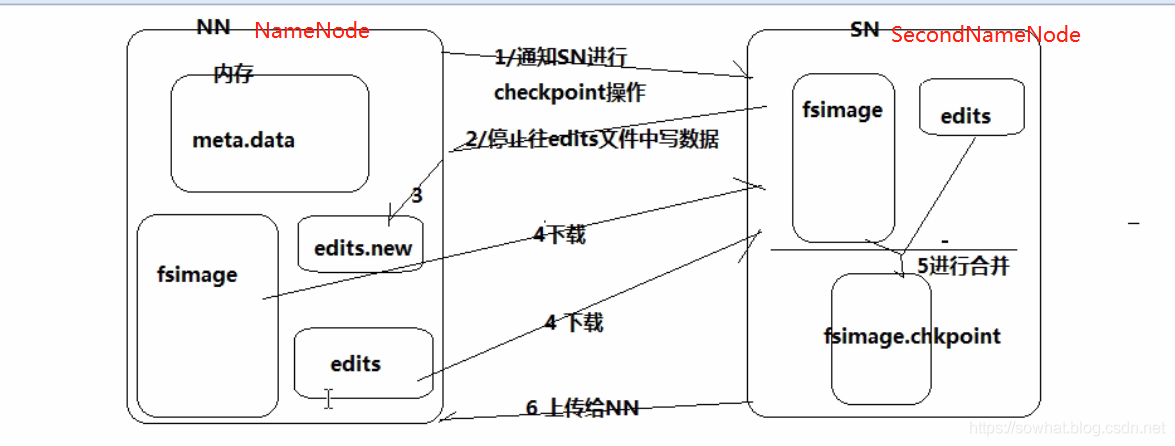
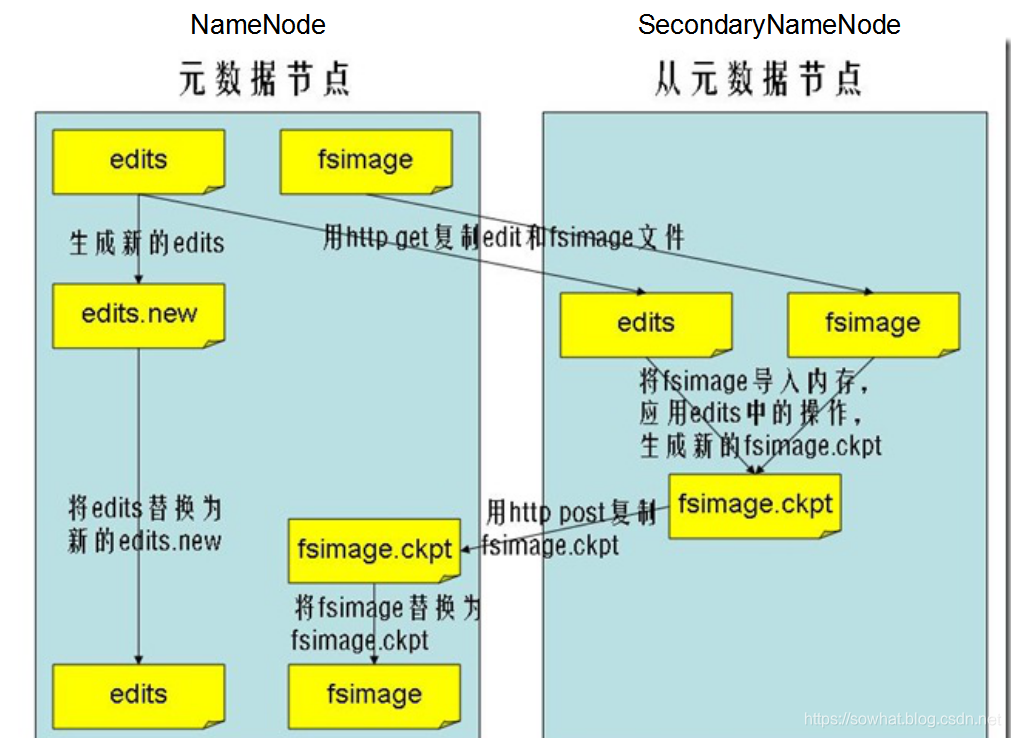
总结: 查询就用内存。 备份好的全部元数据 = fsimage + edits。 NN重启的时候 内存中元数据的恢复就靠前面两个文件了。
DataNode
功能:提供真实文件数据的存储服务。hdfs-site.xml
文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block,dfs.block.size设定文件块大小。
PS:不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间
Replication:多复本。默认是三个。dfs.replication属性
也可以自己去put 数据 然后 看在分布式数据集上的真实存储路径信息。
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4.1/data</value>
Shell命令练习:验证块大小
方法:上传大于128MB的文件(比如JDK8安装包),观察块大小
验证:使用 http://hadoop0:50070观察大小,或者直接到我们制定的分布式真实路径上把JDK8切片后的数据都cat到一个新文件中进行合并会发现,还可以还原成JDK8。
HDFS Java编程
package mytest.hdfs;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HdfsUtil
{
FileSystem fs = null;
@Before
public void init() throws Exception
{
// fs 的 HDFS 操作
// https://www.cnblogs.com/wpbing/archive/2019/07/23/11233399.html
//读取classpath下的xxx-site.xml 配置文件,并解析其内容,封装到conf对象中
Configuration conf = new Configuration();
//也可以在代码中对conf中的配置信息进行手动设置,会覆盖掉配置文件中的读取的值
conf.set("fs.defaultFS", "hdfs://weekend110:9000/");
//根据配置信息,去获取一个具体文件系统的客户端操作实例对象, 记得 操作时候 写上用户名称
fs = FileSystem.get(new URI("hdfs://weekend110:9000/"), conf, "hadoop");
}
/**
* 上传文件,比较底层的写法
* @throws Exception
*/
@Test
public void upload() throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://weekend110:9000/");
FileSystem fs = FileSystem.get(conf);
Path dst = new Path("hdfs://weekend110:9000/aa/sowhat.txt");
FSDataOutputStream os = fs.create(dst);
FileInputStream is = new FileInputStream("c:/sowhat.txt");
IOUtils.copy(is, os);
}
/**
* 上传文件,封装好的写法
* @throws Exception
* @throws IOException
*/
@Test
public void upload2() throws Exception, IOException
{
fs.copyFromLocalFile(new Path("c:/sowhat.txt"), new Path("hdfs://weekend110:9000/aaa/bbb/ccc/sowhat.txt"));
}
/**
* 下载文件
* @throws Exception
* @throws IllegalArgumentException
*/
@Test
public void download() throws Exception
{
fs.copyToLocalFile(new Path("hdfs://weekend110:9000/aa/sowhat.txt"), new Path("c:/sowhat.txt"));
}
/**
* 查看文件信息
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void listFiles() throws FileNotFoundException, IllegalArgumentException, IOException
{
// listFiles 列出的是 文件 信息,而且提供递归遍历 ls
RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path("/"), true);
while (files.hasNext())
{
LocatedFileStatus file = files.next();
Path filePath = file.getPath();
path = file.getPath();
String fileName = filePath.getName();
System.out.println(fileName);
}
System.out.println("---------------------------------");
// listStatus 可以列出文件和文件夹的信息,但是不提供自带的递归遍历
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus status : listStatus)
{
String name = status.getPath().getName();
System.out.println( name + (status.isDirectory() ? " is dir" : " is file"));
}
}
/**
* 创建文件夹
* @throws Exception
* @throws IllegalArgumentException
*/
@Test
public void mkdir() throws IllegalArgumentException, Exception
{
fs.mkdirs(new Path("/aaa/bbb/ccc"));
}
/**
* 删除文件或文件夹
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void rm() throws IllegalArgumentException, IOException
{
fs.delete(new Path("/aa"), true);
}
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://weekend110:9000/");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream is = fs.open(new Path("/jdk-7u65-linux-i586.tar.gz"));
FileOutputStream os = new FileOutputStream("c:/jdk7.tgz");
IOUtils.copy(is, os);
}
}
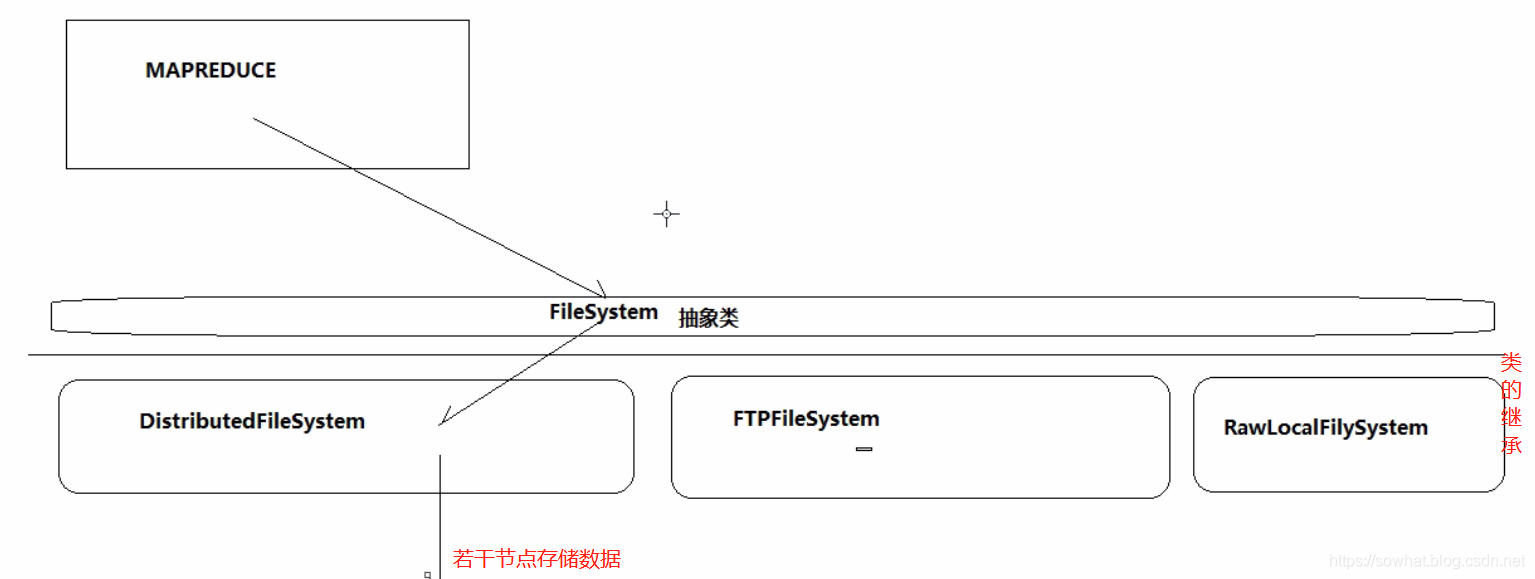
自我理解总结FileSystem涉及思想
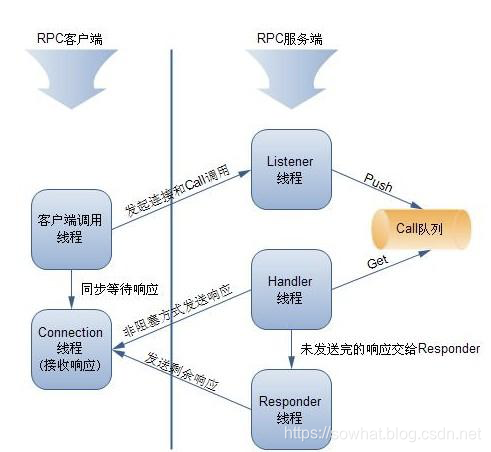
PRC(Romote Procedure Call) 远程过程调用
形象RPC讲解。远程过程调用底层实现机制如下图,
- RPC——远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
- RPC采用客户机/服务器模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
- hadoop的整个体系结构就是构建在RPC之上的(见org.apache.hadoop.ipc)
hadoop-rpc 流程如下
RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path("/"), true);
while (files.hasNext())
{
LocatedFileStatus file = files.next();
Path filePath = file.getPath();
file.getBlockLocations();// 这就是 PRC
path = file.getPath();
String fileName = filePath.getName();
System.out.println(fileName);
}
DN 跟NN 之间也时不时要通讯进行 状态汇报,任务分发等都是通过RPC,代理模式
代理对象(代理远程对象 动态代理、反射、socket 技术),然后在本地调用的时候跟调用远程一样 。
Hadoop中 RPC框架封装思想图如下:

RPCdemo
PS:客户端跟服务器端共有一套业务接口
1. 客户端业务接口
public interface LoginServiceInterface
{
public static final long versionID = 1L;
public String login(String username, String password);
}
2. 客户端通过PRC进行远程调用。
public class LoginController {
public static void main(String[] args) throws Exception {
// 远程调用的 IP地址名 端口号 要调用的 Interface
LoginServiceInterface proxy = RPC.getProxy(LoginServiceInterface.class,
1L, new InetSocketAddress("weekend110", 10000), new Configuration());
String result = proxy.login("sowhat", "123456");
System.out.println(result);
}
}
3. 服务器端的业务接口
public interface LoginServiceInterface
{
public static final long VersionID = 1L;
public String login(String username,String password);
}
4. 服务器业务接口实现
public class LoginServiceImpl implements LoginServiceInterface
{
public String login(String username, String password)
{
return username + "logged in success!";
}
}
5. 服务器端PRC被调用启动
// 服务器端 PRC 的开启
public class Starter
{
public static void main(String[] args) throws HadoopIllegalArgumentException,IOException
{
Builder builder = new RPC.Builder(new Configuration());
// IP 地址 端口号 协议接口 实现的协议接口类
builder.setBindAddress("weekend110").setPort(1000).setProtocol(LoginServiceInterface.class).setInstance(new LoginServiceImpl());
Server server = builder.build();
server.start();
}
}
延伸思考 服务调用动态转发跟负载均衡的实现
HDFS下载数据时源码追踪
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://weekend110:9000/");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream is = fs.open(new Path("/jdk-7u65-linux-i586.tar.gz"));
FileOutputStream os = new FileOutputStream("c:/jdk7.tgz");
IOUtils.copy(is, os);
}
- FileSystem 抽象类调用的那个分布式类,
FileSystem fs = FileSystem.get(conf);,根据配置文件看创建那个FileSystem实例,并且用到了反射机制。
FileSystem.get --> 通过反射实例化了一个DistributedFileSystem --> new DFSCilent()把他作为自己的成员变量
在DFSClient构造方法里面,调用了createNamenode,使用了RPC机制,得到了一个NameNode的代理对象,就可以和NameNode进行通信了
FileSystem --> DistributedFileSystem --> DFSClient --> NameNode的代理
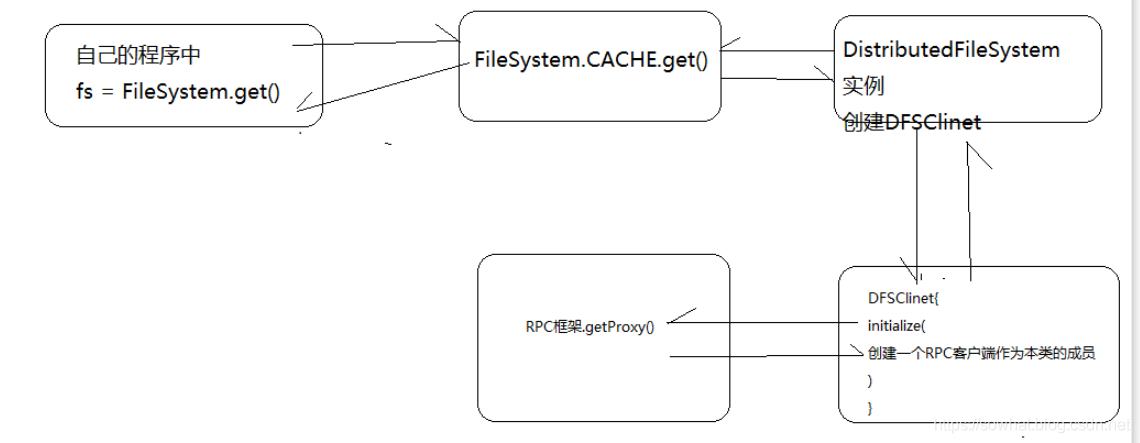
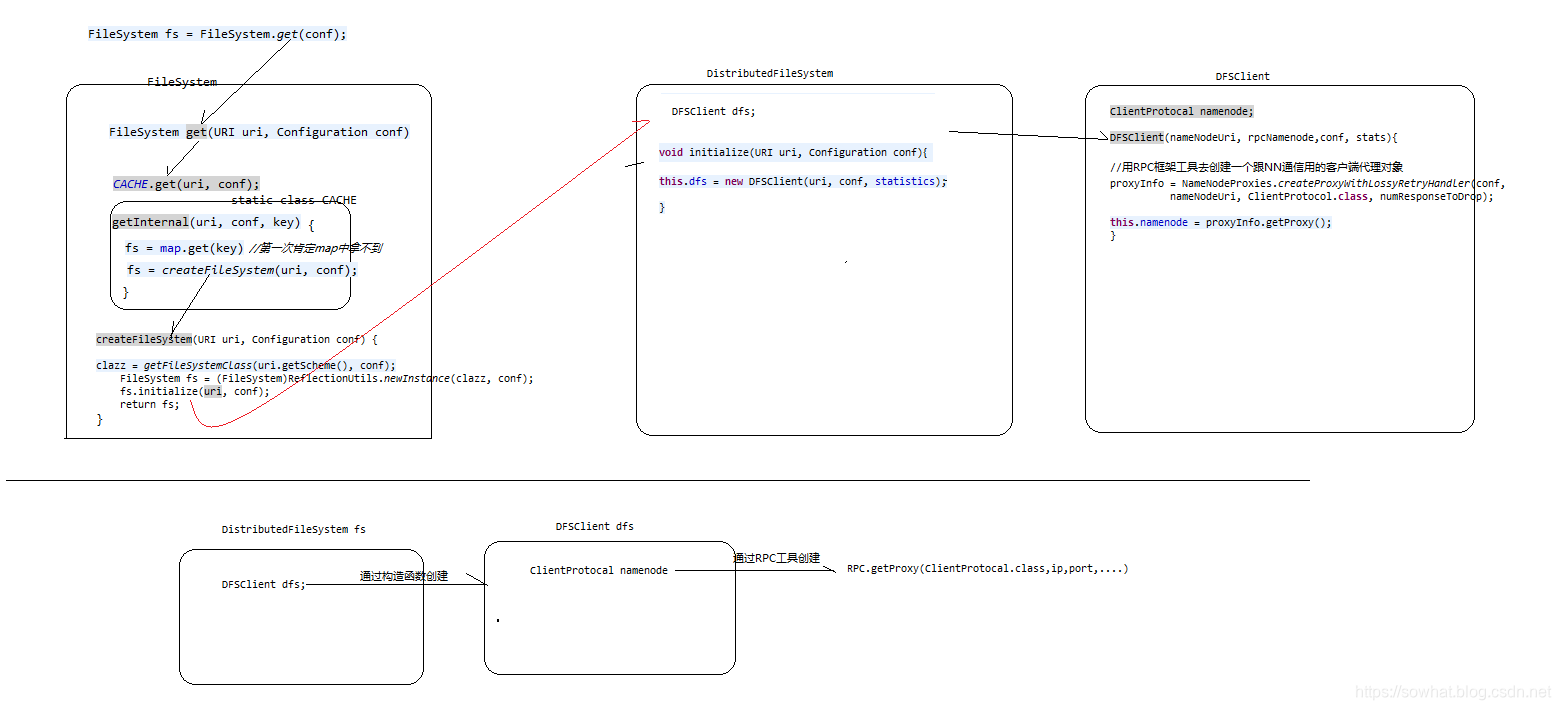

- fs.open里面涉及到了很多知识点,有RPC、接口类、NameNode、DataNode等数据。


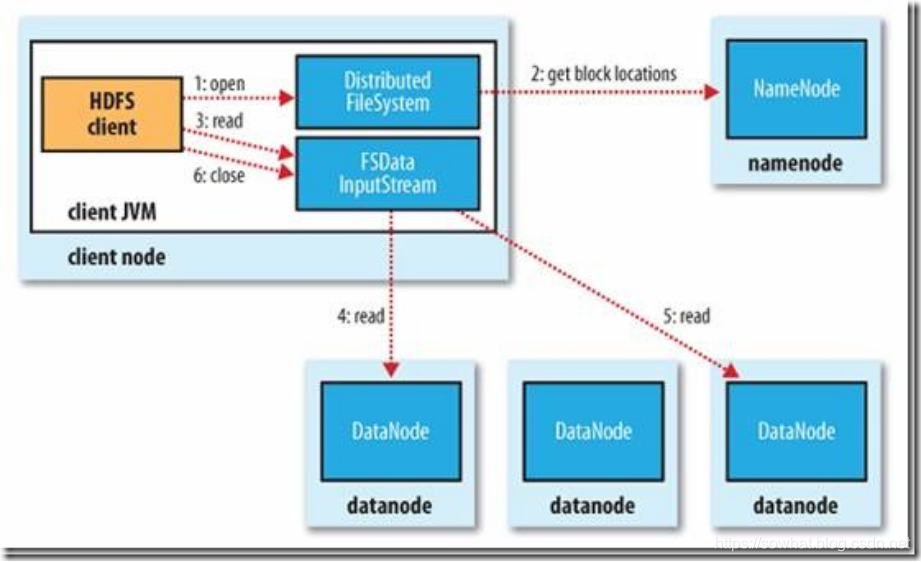
HDFS读过程
- 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件
- FileSystem用RPC调用元数据节点,得到文件的数据块信息,对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
- FileSystem返回FSDataInputStream给客户端,用来读取数据,客户端调用stream的read()函数开始读取数据。
- DFSInputStream连接保存此文件第一个数据块的最近的数据节点,data从数据节点读到客户端(client)
- 当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
- 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
- 在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
- 失败的数据节点将被记录,以后不再连接。
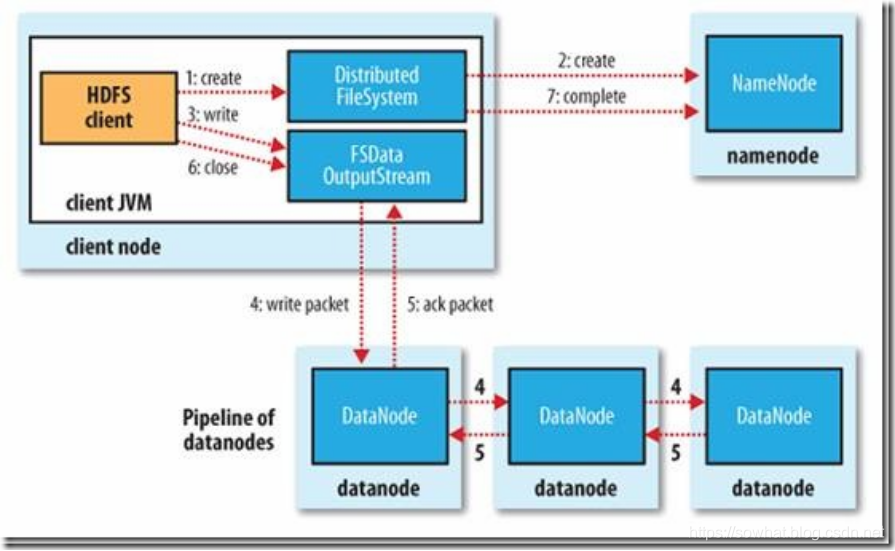
HDFS写过程
- 初始化FileSystem,客户端调用create()来创建文件
- FileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件,元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
- FileSystem返回DFSOutputStream,客户端用于写数据,客户端开始写入数据。
- DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
- DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
- 当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
- 如果数据节点在写入的过程中失败,关闭pipeline,将ack queue中的数据块放入data queue的开始,当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。















 1611
1611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











