






Apache Flink 是什么?
Flink是一个基于流计算的分布式引擎,以前的名字叫stratosphere,从2010年开始在德国一所大学里发起,也是有好几年的历史了,2014年来借鉴了社区其它一些项目的理念,快速发展并且进入了Apache顶级孵化器,后来更名为Flink。
Flink在德语中是快速和灵敏的意思,用来体现流式数据处理速度快和灵活性强等特点。

Flink提供了同时支持高吞吐、低延迟和exactly-once 语义的实时计算能力,另外Flink 还提供了基于流式计算引擎处理批量数据的计算能力,真正意义上实现了流批统一。
Flink 与 Hadoop 软件栈是什么关系?
Flink 独立于Apache Hadoop,且能在没有任何 Hadoop 依赖的情况下运行。
但是,Flink 可以很好的集成很多 Hadoop 组件,例如 HDFS、YARN 或 HBase。 当与这些组件一起运行时,Flink 可以从 HDFS 读取数据,或写入结果和检查点(checkpoint)/快照(snapshot)数据到 HDFS 。 Flink 还可以通过 YARN 轻松部署,并与 YARN 和 HDFS Kerberos 安全模块集成。
为什么选择Flink?
Flink具有先进的架构理念、诸多的优秀特性,以及完善的编程接口。
Flink的具体优势有如下几点:
(1)同时支持高吞吐、低延迟、高性能;
(2)支持事件时间(Event Time)概念;
事件时间的语义使流计算的结果更加精确,尤其在事件到达无序或者延迟的情况下,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响。
(3)支持有状态计算;
所谓状态就是在流计算过程中,将算子的中间结果数据保存在内存或者文件系统中,等下一个事件进入算子后,可以从之前的状态中获取中间结果,计算当前的结果,从而无需每次都基于全部的原始数据来统计结果。
(4)支持高度灵活的窗口(Window)操作;
(5)基于轻量级分布式快照(Snapshot)实现的容错;
(6)基于JVM实现独立的内存管理;
(7)Save Points(保存点);
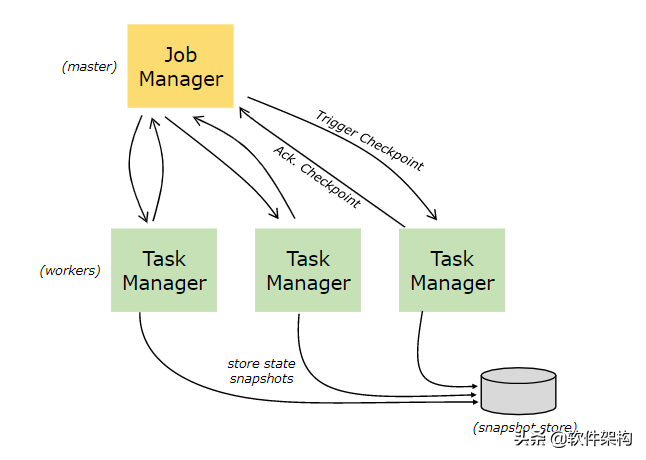
保存点是手动触发的,触发时会将它写入状态后端(State Backends)。Savepoints的实现也是依赖Checkpoint的机制。Flink 程序在执行中会周期性的在worker 节点上进行快照并生成Checkpoint。因为任务恢复的时候只需要最后一个完成的Checkpoint的,所以旧有的Checkpoint会在新的Checkpoint完成时被丢弃。Savepoints和周期性的Checkpoint非常的类似,只是有两个重要的不同。一个是由用户触发,而且不会随着新的Checkpoint生成而被丢弃。
Flink 基本架构
在Flink整个软件架构体系中,统一遵循了分层的架构设计理念,在降低系统耦合度的同时,为上层用户构建Flink应用提供了丰富且友好的接口。
整个Flink的架构体系可以分为三层:
- API & Libraries层;
- Runtime核心层;
- 物理部署层;
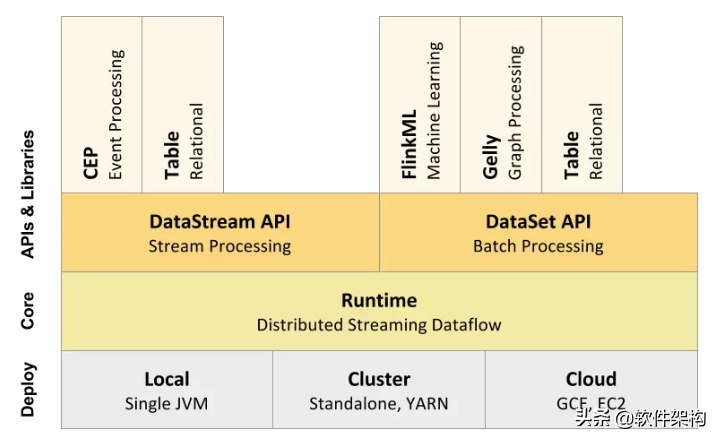
Deployment层: 该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN),云(GCE/EC2),Kubernetes等。
Runtime层:Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层: 主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
Libraries层:该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的计算框架,也分别对应于面向流处理和面向批处理两类。
- 面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);
- 面向批处理支持:FlinkML(机器学习库)、Gelly(图处理);
Flink运行流程及组件
核心概念:Job Managers,Task Managers,Clients
Flink也是典型的master-slave分布式架构。Flink的运行时,由两种类型的进程组成:
- JobManagers: 也就是masters ,协调分布式任务的执行 。用来调度任务,协调checkpoints,协调错误恢复等等。至少需要一个JobManager,高可用的系统会有多个,一个leader,其他是standby。
- TaskManagers: 也就是workers,用来执行数据流任务或者子任务,缓存和交互数据流。 至少需要一个TaskManager。
Client: Client不是运行时和程序执行的一部分,它是用来准备和提交数据流到JobManagers。之后,可以断开连接或者保持连接以获取任务的状态信息。
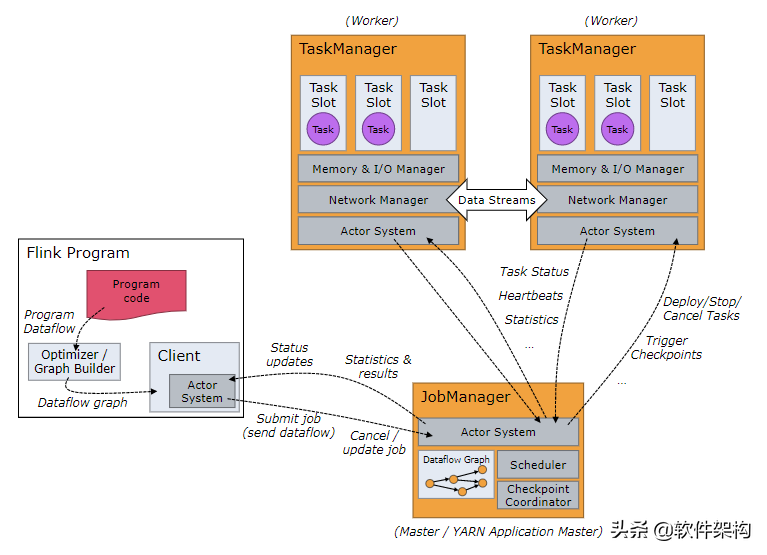
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager, JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。 TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
每个Worker(Task Manager)是一个JVM进程,通常会在单独的线程里执行一个或者多个子任务。为了控制一个Worker能够接受多少个任务,会在Worker上抽象多个Task Slot (至少一个)。
只有一个slot的TaskManager意味着每个任务组运行在一个单独JVM中。 在拥有多个slot的TaskManager上,subtask共用JVM,可以共用TCP连接和心跳消息,同时可以共用一些数据集和数据结构,从而减小任务的开销。
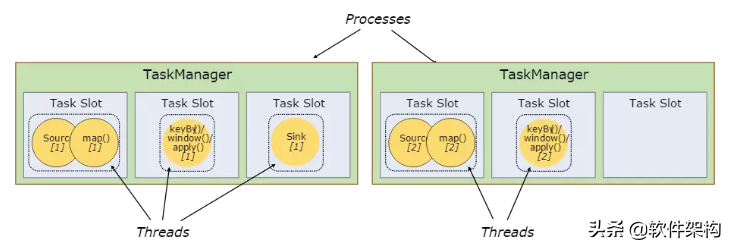
Flink的任务运行其实是多线程的方式,这和MapReduce多JVM进程的方式有很大的区别,Flink能够极大提高CPU使用效率,在多个任务之间通过TaskSlot方式共享系统资源,每个TaskManager中通过管理多个TaskSlot资源池对资源进行有效管理。














 3597
3597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









