







1.Hadoop集群搭建的配置
1.1搭建步骤如下链接:
https://blog.csdn.net/qq_31987649/article/details/85037833
1.2 启动hadoop
只需要启动Master 主节点上的hadoop
hadoop安装路径: / hadoop-2.6.5 /sbin
./start-all.sh 启动
./stop-all.sh 关闭
启动成功如下:
Master:

slave0:

slave1:

2.下载并解压 flume
下载版本
apache-flume-1.7.0-bin.tar.gz
2.1 解压目录入下 命令 tar -zxvf /app/soft/apache-flume-1.7.0-bin.tar.gz -C /app/install/
2.2修改配置文件 进入conf目录下
mv flume-env.sh.template flume-env.sh
vi flume-env.sh


2.3 在conf目录下创建 hdfs-avro.conf 配置文件
命令: vi hdfs-avro.conf 增加内容:
a1.sources = r1
#数据沉淀,可以多个,中间用空格分隔
a1.sinks = k1
#传输管道,一般只有一个,可以多个
a1.channels = c1
#配置source 消息生产者
#exec可以通过指定的操作对日志进行读取,使用exec时需要指定shell命令,对日志进行读取
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /app/logs/webProvider.log
# 配置channel,将buffer事件放在内存中,相当于数据缓冲区,接收source数据发送给sink
#传输管道的参数,类型是内存传输
a1.channels.c1.type = memory
#存储在通道中的最大事件数。
a1.channels.c1.capacity = 1000
#收集端的sink会在收集到了1000条以后再去提交事务(即发送到下一个目的地)
a1.channels.c1.transactionCapacity = 100
# 配置sink 接收器
#沉淀的方式是控制台打印,还可以有其他方式,如上传到hdfs。
a1.sinks.k1.type = hdfs
#设置hdfs接收器
a1.sinks.k1.hdfs.path = hdfs://192.168.28.129:9000/flume/testLog.log
#设置
a1.sinks.k1.hdfs.filePrefix = test
#a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.fileType=DataStream
# 把source和sink绑定在channel上
#指定传输管道,
a1.sources.r1.channels = c1
#设置数据沉淀接收的管道
a1.sinks.k1.channel = c1
2.4启动flume
进入 flume bin 目录 执行如下命令
./flume-ng agent -c ../conf -f ../conf/hdfs-avro.conf -n a1 -Dflume.root.logger=INFO,console
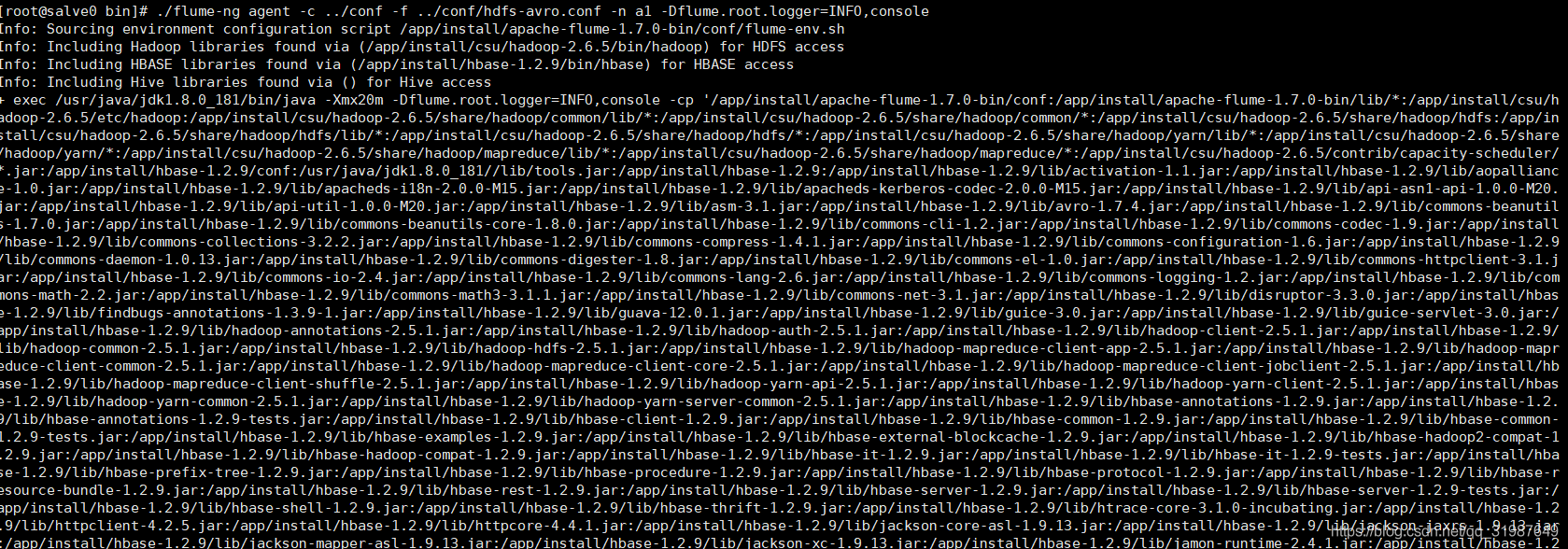 flume 成功启动后根据 hdfs-avro.conf 配置生成flume目录
flume 成功启动后根据 hdfs-avro.conf 配置生成flume目录

3.测试
输入命令 :echo 'hello qt'>>/app/logs/webProvider.log (向文件中写入数据)
![]()
/app/logs/webProvider.log 对应 hdfs-avro.conf 配置文件中的 要采集的数据源
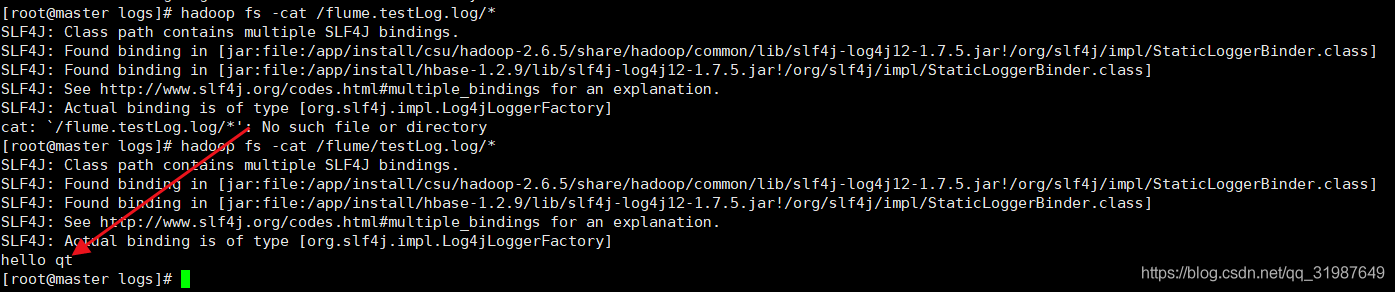
通过HDFS系统命令查看HDFS中生成的文件并查看文件中的内容
命令: hadoop fs -ls /flume/testLog.log/*
成功写入hdfs中














 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









