







上节写到读取静态文件,接下来仿一个读取web.xml配置文件的功能。
首先,读取XML我参考的是这篇文章:https://www.cnblogs.com/hongwz/p/5514786.html
但是这篇文章里的读取XML是远远不够的,内容中的读取XML方法是读取写死固定的XML,而且只能读取到第一、二层节点,web.xml中可不远远不止一两层,于是得重新写个可以读取不限深度的XML的方法。
第一次修改的XML方法如下:
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class XmlUtil {
/*
* 用Map封装XML实体
* 一个标准的XML节点有3个参数:节点名String,参数名List<Map<String,Object>>,子节点List<Map>
*
*
* */
public static Object read(String path) throws Exception {
//SAXReader就是一个管道,用一个流的方式,把xml文件读出来
SAXReader reader = new SAXReader();
File file = new File(path);
Map result = new HashMap();
Document document = reader.read(file);
Element root = document.getRootElement();
List<Element> childElements = root.elements();
result.put("firstElement", root.getName());
result.put("Attribute", root.attributes());
for (Element child : childElements) {
//未知属性名情况下
List<Attribute> attributeList = child.attributes();
for (Attribute attr : attributeList) {
System.out.println(attr.getName() + ": " + attr.getValue());
}
//未知子元素名情况下
List<Element> elementList = child.elements();
for (Element ele : elementList) {
System.out.println(ele.getName() + ": " + ele.getText());
}
System.out.println();
//这行是为了格式化美观而存在
System.out.println();
}
return null;
}
}
该方法能读取到 第二层节点的内容

需要注意的是,web.xml是在tomcat启动的时候读取的,所以我在监听8080端口的时候读取的web.xml,web.xml文件我规定放在resource目录下
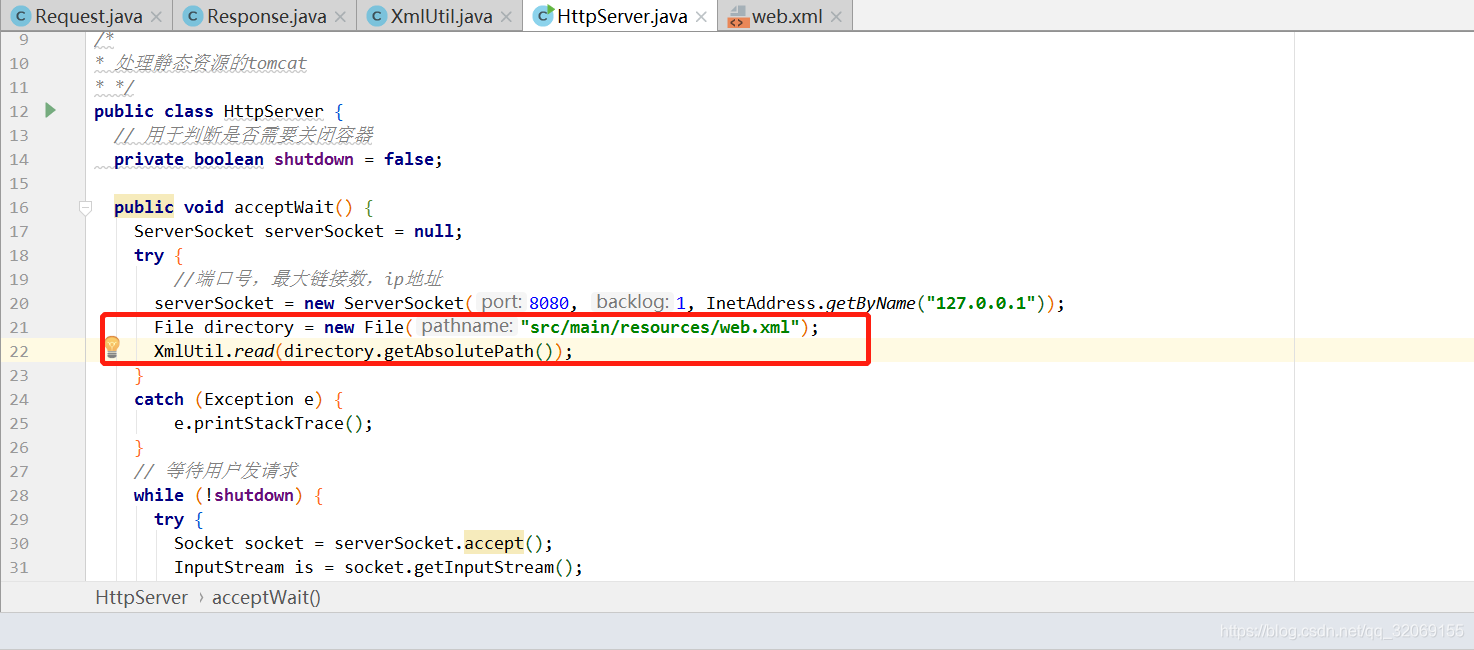
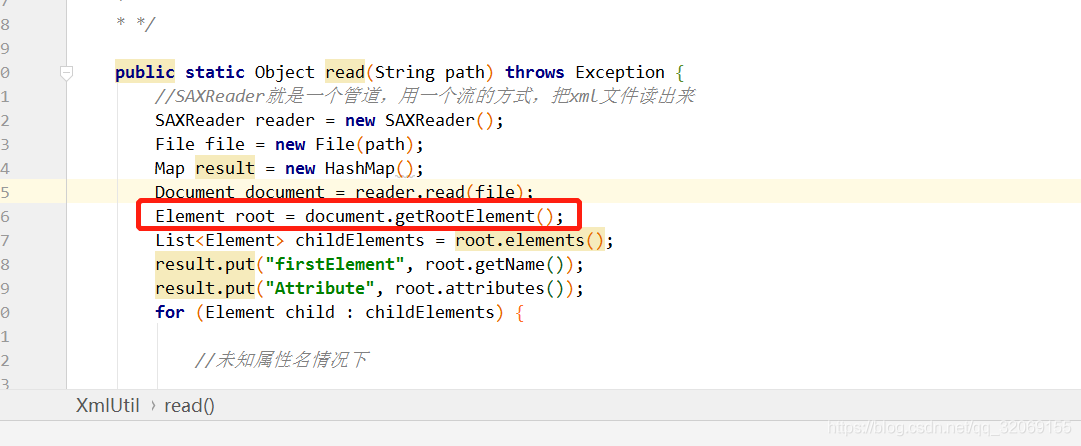
root就是第一层节点,也就是<web></web>
root.elements是读取<web></web>的子节点
然后对<web></web>的子节点和属性进行循环输出,最终输出成
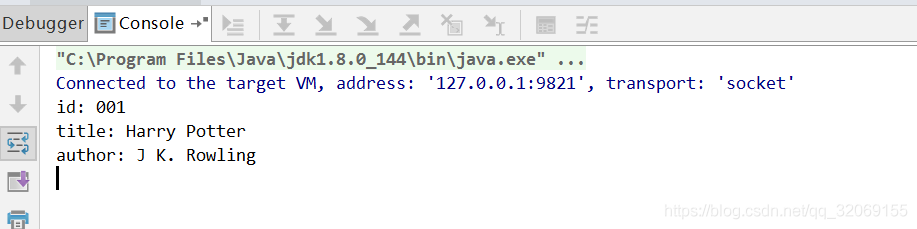
xml从结构上还是比较简单的,
但是上面的这个方法只能读取到第二层节点<title></title>,<author></author>,如果在title节点中再加个子节点,那么就读取不到了,
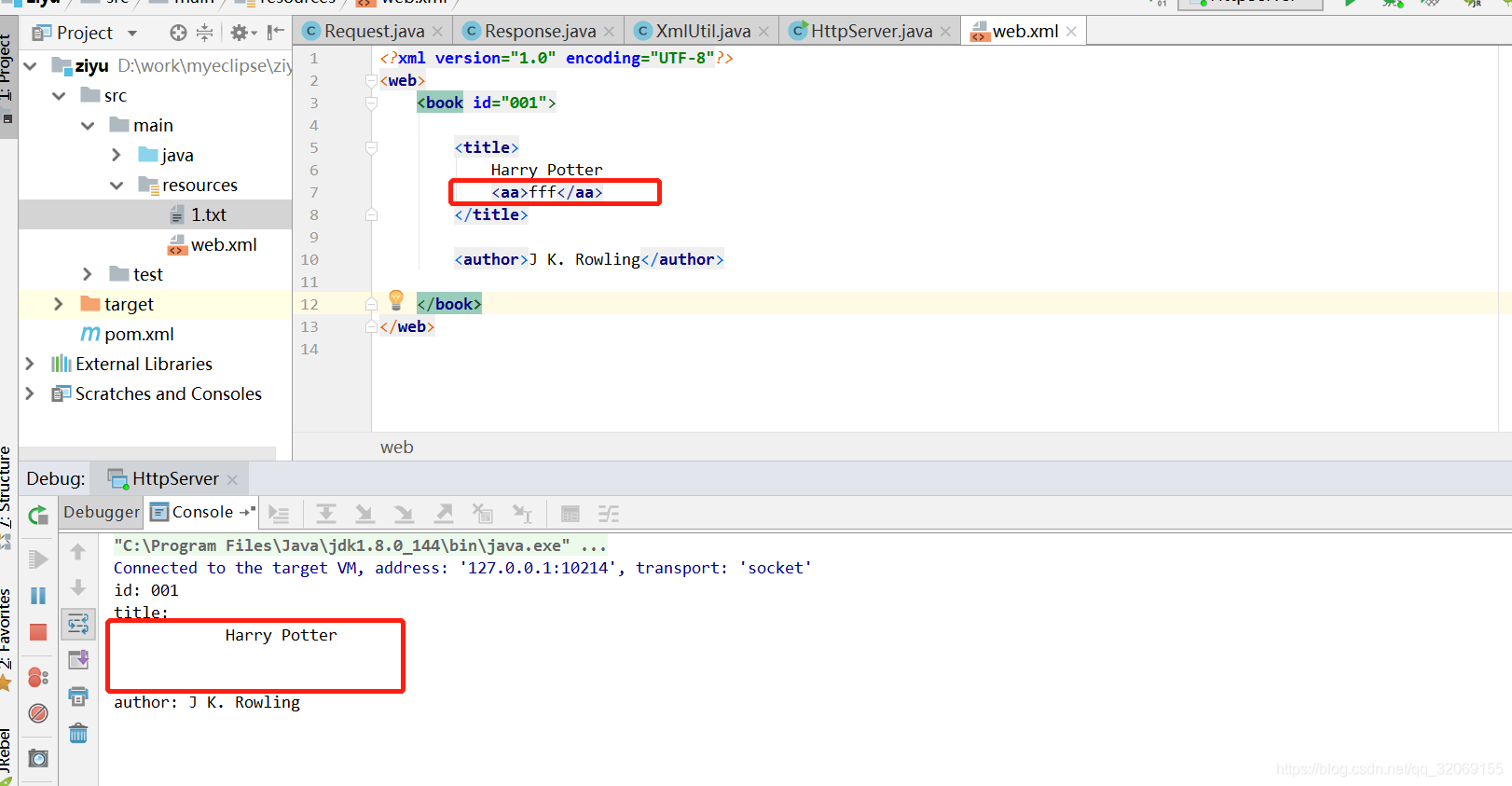
如图,确实读取不到,
OK,那么接下来就是对xml的读取方法进行修改,让他可以无限深度的读取xml。
我们先不要那么快就敲代码,先分析下XML结构
就像上面说的一样,XML结构上比较简单,
就只有节点、属性、内容这三个东西
是滴。。。。。。
============================================================这是分隔符,代表有重大改变
刚刚突然想到,貌似我不用一下子读取全部的节点,只需要读取到第一个就行了,用到了再读取他的子节点,所以就不用改成无限深度的读取xml,只要改成返回第一个节点的方法就行了。
所以代码改成如下:
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class XmlUtil {
/*
* 用Map封装XML实体
* 一个标准的XML节点有3个参数:节点名String,参数名List<Map<String,Object>>,子节点List<Map>
* */
public static Object read(String path) throws Exception {
//SAXReader就是一个管道,用一个流的方式,把xml文件读出来
SAXReader reader = new SAXReader();
File file = new File(path);
Document document = reader.read(file);
Element root = document.getRootElement();
return root;
}
}
读取到了第一个节点,然后再写一个方法解析,因为只是简单版tomcat,所以web.xml中的内容就不做太多解析
web.xml中的配置我是参照以下博客改的:
https://www.cnblogs.com/hxsyl/p/3435412.html
https://www.cnblogs.com/vanl/p/5737656.html
https://www.cnblogs.com/hafiz/p/5715523.html
下面是摘抄上面链接的一些原文,作为对web.xml的一些介绍:
xml必须有且只有一个根节点,大小写敏感,标签不嵌套,必须配对。
web.xml是不是必须的呢?不是的,只要你不用到里面的配置信息就好了,不过在大型web工程下使用该文件是很方便的,若是没有也会很复杂。
那么web.xml能做的所有事情都有那些?其实,web.xml的模式(Schema)文件中定义了多少种标签元素,web.xml中就可以出现它的模式文件所定义的标签元素,它就能拥有定义出来的那些功能。web.xml的模式文件是由Sun公司定义的,每个web.xml文件的根元素<web-app>中,都必须标明这个web.xml使用的是哪个模式文件。
在这里我就只写几个主要标签的解析:
Servlet配置(Servlet放后面写)
<servlet>
<servlet-name>servlet名称</servlet-name>
<servlet-class>servlet类全路径</servlet-class>
<init-param>
<param-name>参数名</param-name>
<param-value>参数值</param-value>
</init-param>
<run-as>
<description>Security role for anonymous access</description>
<role-name>tomcat</role-name>
</run-as>
<load-on-startup>指定当Web应用启动时,装载Servlet的次序</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>servlet名称</servlet-name>
<url-pattern>映射路径</url-pattern>
</servlet-mapping>指定欢迎文件页配置
<welcome-file-list>
<welcome-file>index.jsp</welcome-file>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
</welcome-file-list>配置错误页面
(1).通过错误码来配置error-page
<!--配置了当系统发生404错误时,跳转到错误处理页面NotFound.jsp-->
<error-page>
<error-code>404</error-code>
<location>/NotFound.jsp</location>
</error-page>编码过程我就不详写了,
最终XML解析类如下:
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class XmlUtil {
/*
* 用Map封装XML实体
* 一个标准的XML节点有3个参数:节点名String,参数名List<Map<String,Object>>,子节点List<Map>
* */
public static Object read(String path) throws Exception {
//SAXReader就是一个管道,用一个流的方式,把xml文件读出来
SAXReader reader = new SAXReader();
File file = new File(path);
Document document = reader.read(file);
Element root = document.getRootElement();
return root;
}
//解析Web.xml analysis 解析
public static boolean analysisWeb(){
File directory = new File("src/main/resources/web.xml");
try {
Element root = (Element) read(directory.getAbsolutePath());
if (!"web-app".equals(root.getName())){
return false;
}else{
List<Element> elements = root.elements();
for ( Element element : elements ) {
//welcome-file-list 欢迎文件页配置
if ("welcome-file-list".equals(element.getName())){
List<Element> welcome_file_list = element.elements();
if (welcome_file_list.size() > 0){
for ( Element welcome_file : welcome_file_list ){
if ("welcome-file".equals(welcome_file.getName()))
Response.indexPages.add(welcome_file.getText());
}
}
}
//error-page 通过错误码来配置error-page
// if ("error-page".equals(elements)){
// List<Element> welcome_file_list = element.elements();
// if (welcome_file_list.size() > 0){
// for ( Element welcome_file : welcome_file_list ){
// if ("welcome-file".equals(welcome_file.getName()))
// Response.Index.add(welcome_file.getText());
// }
// }
// }
}
}
} catch (Exception e) {
e.printStackTrace();
return false;
}
return false;
}
}
能把欢迎页读取出来,那么错误页也是一样的,
同时,Response.java我也有做修改:
import java.io.*;
import java.util.ArrayList;
import java.util.List;
public class Response {
public static final int BUFFER_SIZE = 2048;
//浏览器访问D盘的文件
private static final String RESOURCE ="src/main/resources";
private Request request;
private OutputStream output;
public static List<String> indexPages = new ArrayList<String>();
public Response(OutputStream output) {
this.output = output;
}
public void setRequest(Request request) {
this.request = request;
}
public void sendStaticResource() throws IOException {
byte[] bytes = new byte[BUFFER_SIZE];
FileInputStream fis = null;
try {
//首页
if ("/".equals(request.getUrL())){
if (indexPages.size() > 0) {
File file = new File(RESOURCE, indexPages.get(0));
if (null != getFile(file)){
String retMessage = (String) getFile(file);
output.write(retMessage.getBytes());
return;
}
}else{
String retMessage = "<h1> Index not Found</h1>";
String returnMessage ="HTTP/1.1 404 File Not Found\r\n" +
"Content-Type: text/html\r\n" +
"Content-Length: "+retMessage.length()+"\r\n" +
"\r\n" +
retMessage;
output.write(returnMessage.getBytes());
return;
}
}
//====================================首页结束
//拼接本地目录和浏览器端口号后面的目录
File file = new File(RESOURCE, request.getUrL());
String retMessage = (String) getFile(file);
if (null != retMessage){
output.write(retMessage.getBytes());
}else{
//文件不存在,返回给浏览器响应提示,这里可以拼接HTML任何元素
retMessage = "<h1>"+file.getName()+" file or directory not exists</h1>";
String returnMessage ="HTTP/1.1 404 File Not Found\r\n" +
"Content-Type: text/html\r\n" +
"Content-Length: "+retMessage.length()+"\r\n" +
"\r\n" +
retMessage;
output.write(returnMessage.getBytes());
}
}
catch (Exception e) {
System.out.println(e.toString() );
}
finally {
if (fis!=null)
fis.close();
}
}
public Object getFile(File file) throws Exception {
FileInputStream fis = null;
String retMessage = null;
//如果文件存在,且不是个目录
if (file.exists() && !file.isDirectory()) {
fis = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(fis,"UTF-8"); //最后的"GBK"根据文件属性而定,如果不行,改成"UTF-8"试试
BufferedReader br = new BufferedReader(reader);
String line;
StringBuilder readLine = new StringBuilder();
while ((line = br.readLine()) != null) {
readLine.append(line);
}
retMessage = "HTTP/1.1 200 OK\r\n" +
"Content-Type: text/html;charset=utf-8\r\n" +
"Content-Length: "+ readLine.toString().getBytes().length +"\r\n" +
"\r\n" +
readLine;
}else {
return null;
}
return retMessage;
}
}读取File的代码我提取出来了
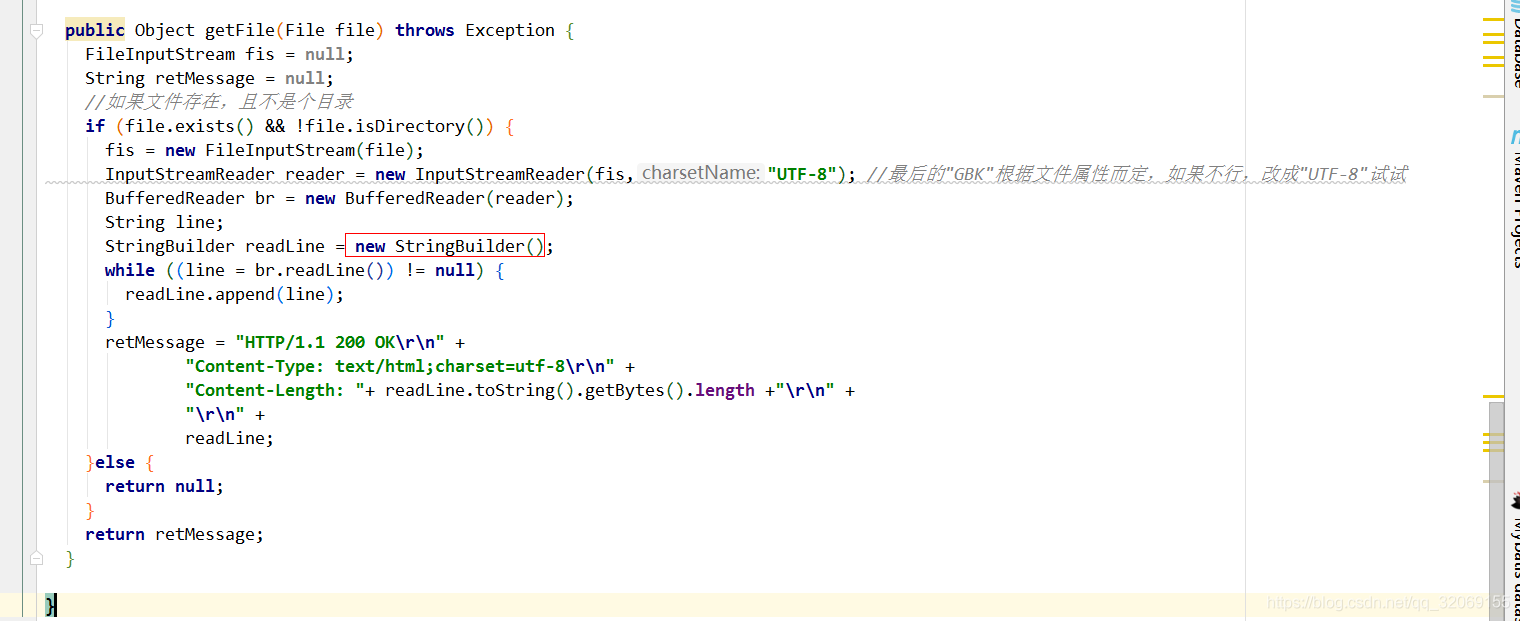
这是读取首页的代码
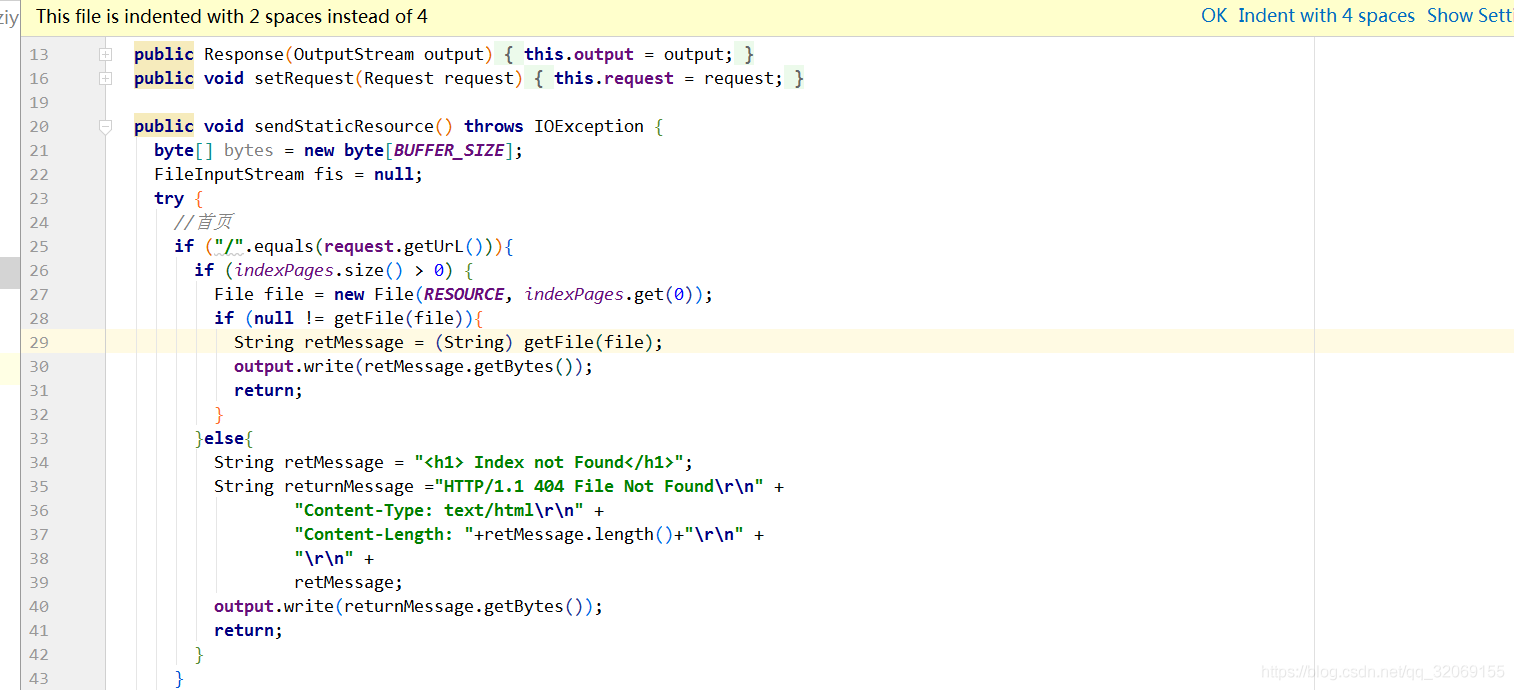
当Url为 "/" 的时候就是http://localhost:8080/默认的这个网址,也就是首页
如果是访问首页,我就会去拿indexPages这个变量
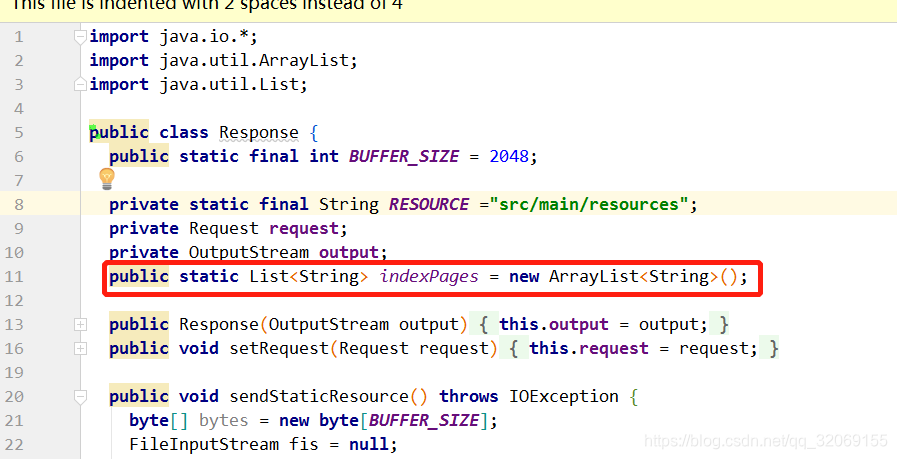
这个indexPages是在类启动的时候加载进来的,
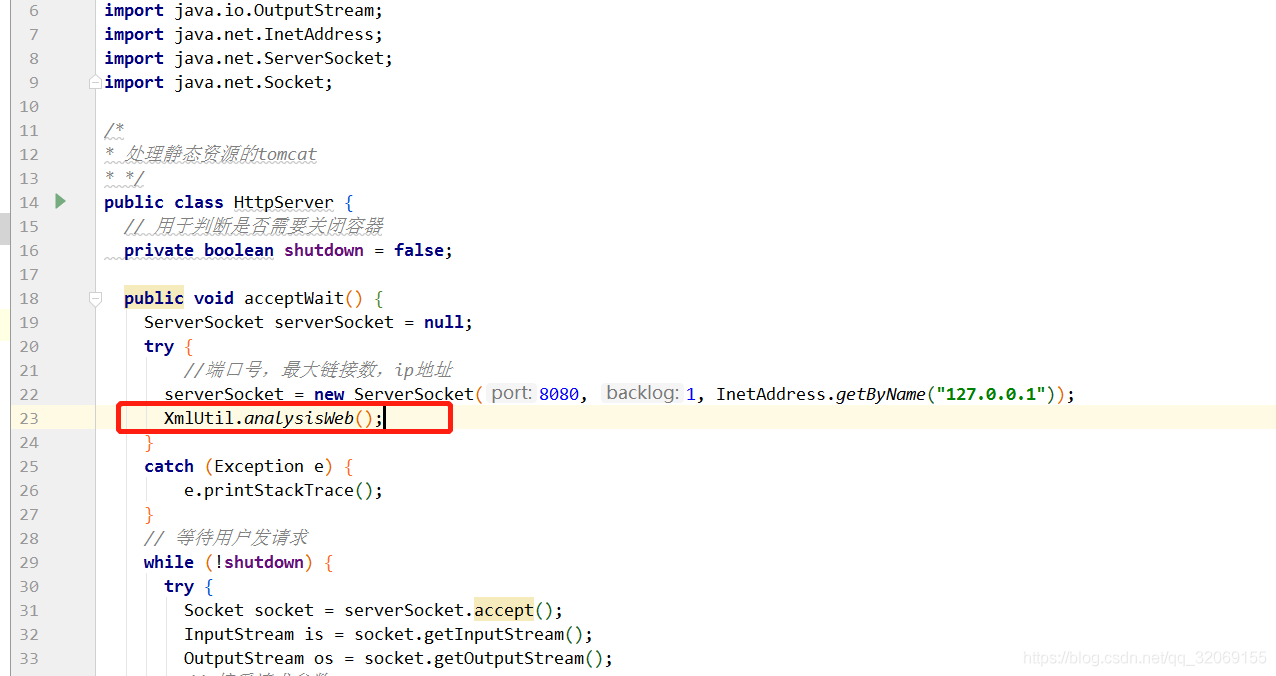
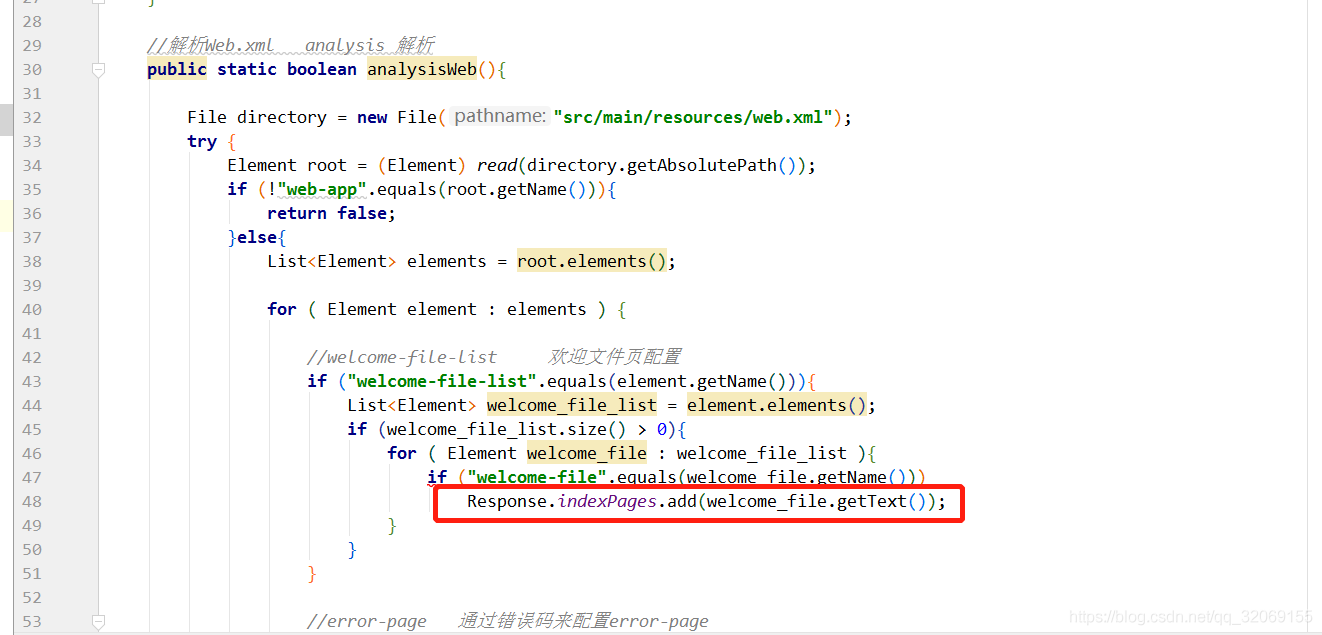 解析web.xml是如果有 welcome-file 这个标签我就把这个首页地址存进indexPages中
解析web.xml是如果有 welcome-file 这个标签我就把这个首页地址存进indexPages中
这是我的index页面
最后,启动服务器,访问localhost:8080
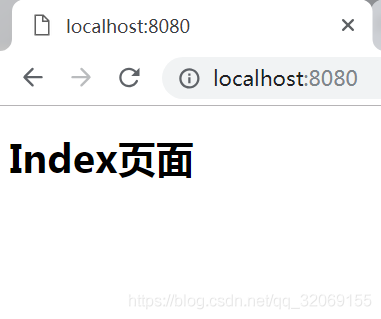
返回成功!
第二节xml的读取就到此告一段落了,
如果有什么写的不对的地方,欢迎下方评论指出!
接下来的第三节会解析java文件,一个真正意义上的简单版tomcat功能。














 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









