






目录
Surrogate Confounding
在某些情况下,由于未测量的混杂因素,你无法关闭所有的后门路径。在下面的例子中,经理的素质导致经理选择参加培训和团队的参与度提升。因此,在治疗(培训)和结果(团队参与度)的关系中存在混杂。但在这个案例中,你无法对混杂因素进行条件化,因为它无法测量。在这种情况下,由于混杂因素的偏差,治疗对结果的因果效应是无法识别的。然而,你有其他可测量的变量可以作为经理素质的代理变量。这些变量不在后门路径上,但控制它们将有助于减少偏差(即使不能完全消除)。这些变量有时被称为替代混杂因素。
在这个例子中,你无法直接测量经理的素质,但你可以测量其部分原因,如经理的工作年限或教育水平;以及其部分结果,如团队的流失率或表现。控制这些替代变量不足以消除偏差,但它确实有所帮助: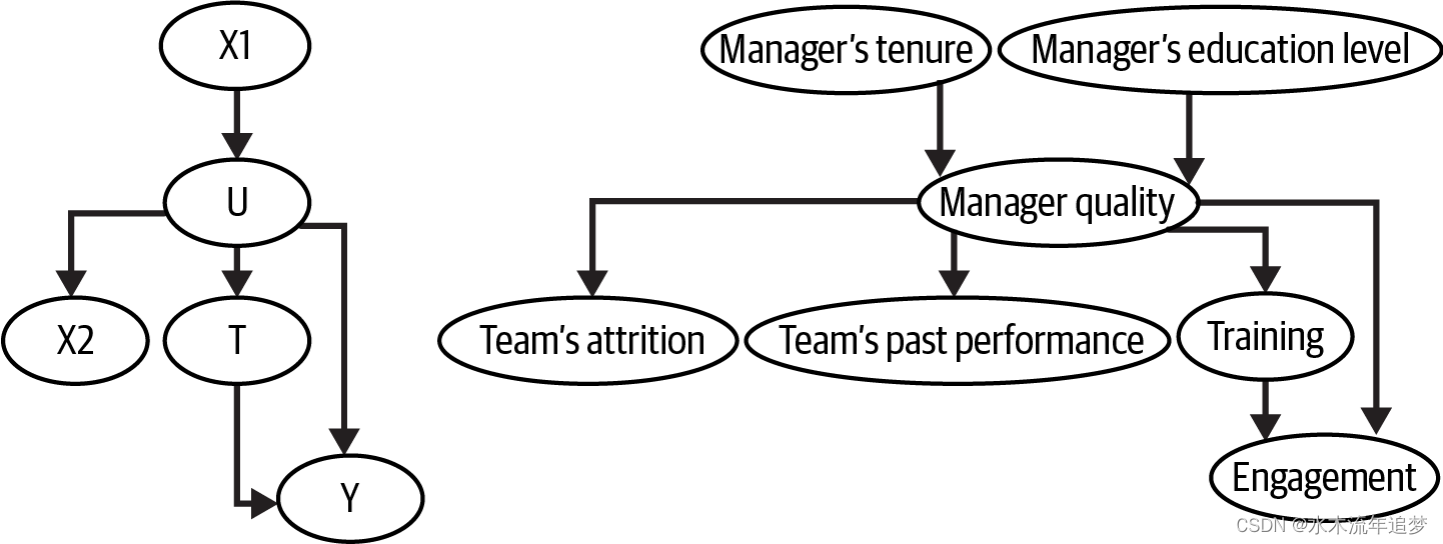
Randomization Revisited
在许多重要且与现实紧密相关的研究问题中,混杂因素是一个主要问题,因为你永远无法确定自己已经控制了所有混杂因素。但如果你打算主要在工业界使用因果推断,我有一个好消息给你。在工业界,你主要感兴趣的是学习公司可以控制的事物的因果效应——如价格、客户服务和营销预算——以便优化它们。在这些情况下,很容易知道混杂因素是什么,因为企业通常知道它用于分配治疗的信息是什么。不仅如此,即使它不知道,几乎总有一种选择是干预治疗变量。这正是A/B测试的要点所在。当你随机化治疗时,你可以从一个有未观测混杂因素的图转化为一个治疗的唯一原因是随机性的图: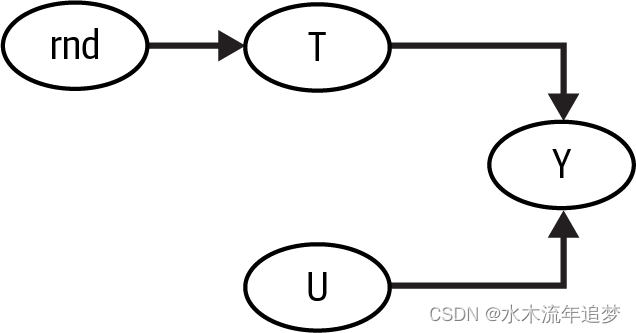
因此,除了尝试弄清楚为了识别效应你需要对哪些变量进行条件化之外,你还应该问自己有哪些可能的干预措施可以改变图,使之成为一个感兴趣的因果量可识别的图。
当你有未观测的混杂因素时,并非一切都无药可救。在第四部分,我将介绍可以利用数据中的时间结构来处理未观测混杂因素的方法。第五部分将涵盖使用工具变量达到相同目的的应用。
Selection Bias
如果你认为混杂偏倚已经在你的因果推断鞋子里埋下了难以察觉的小石头,那么等到你听到选择偏倚时,你可能会更加惊讶。虽然混杂偏倚发生在你没有控制治疗和结果的共同原因时,选择偏倚则更多与对共同结果和中介变量的条件化有关。
Conditioning on a Collider
考虑这样一个情况,你为一家软件公司工作,想要估计你刚刚实施的一个新功能的影响。为了避免任何形式的混杂偏倚,你进行了新功能的随机推广:10%的客户被随机选中获得新功能,而其余人则没有。你想要知道这个功能是否让客户更开心、更满意。由于满意度不容易直接测量,你使用净推荐者得分(NPS)作为其代理指标。为了测量NPS,你向推广组(已接受治疗)和对照组的客户发送调查问卷,询问他们是否会推荐你的产品。当结果出来时,你发现拥有新功能且回应了NPS调查的客户,其NPS得分比没有新功能但也回应了NPS调查的客户更高。你能说这个差异完全是由新功能对NPS的因果效应造成的吗?要回答这个问题,你应该从代表这种情况的图开始:
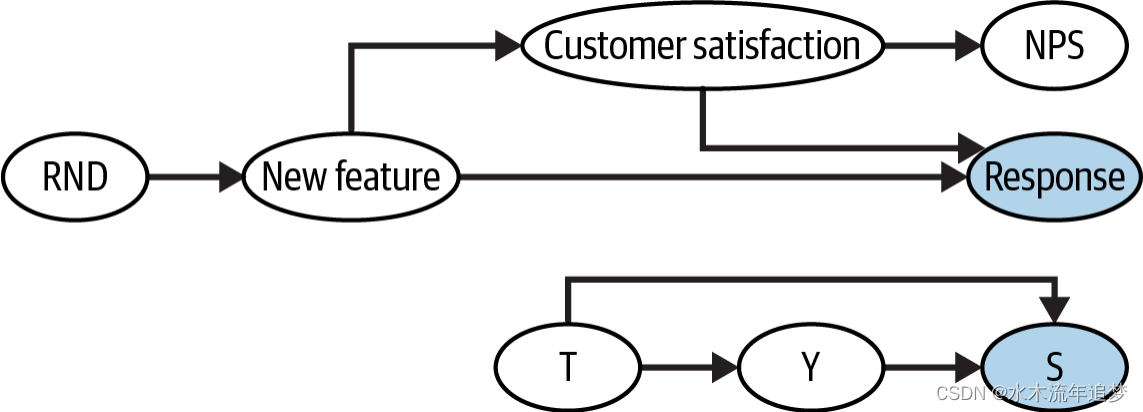
长话短说,遗憾的是,答案是否定的。这里的问题在于,你只能测量那些回应了NPS调查的客户的NPS。你正在估计治疗组和对照组之间的差异,同时也对回应了NPS调查的客户进行条件化。尽管随机化允许你将ATE识别为治疗组和对照组之间结果的差异,但一旦你对共同结果进行条件化,也会引入选择偏倚。为了看清这一点,你可以重新创建这个图并删除新功能到客户满意度的因果路径,这也会关闭直接通往NPS的路径。然后,你可以检查在对回应进行条件化后,NPS是否仍然与新功能相连。你会发现确实如此,这意味着关联通过非因果路径在两个变量间流动,这正是偏倚的含义:
nps_model = nx.DiGraph([
("RND", "New Feature"),
# ("New Feature", "Customer Satisfaction"),
("Customer Satisfaction", "NPS"),
("Customer Satisfaction", "Response"),
("New Feature", "Response"),
])
not(nx.d_separated(nps_model, {"NPS"}, {"New Feature"}, {"Response"}))
True为了培养你对这种偏倚的直觉,让我们重新赋予你神一般的能力,假装你可以看到反事实结果的世界。也就是说,你可以看到所有客户在对照组下会有的NPS(NPS0)和在治疗组下会有的NPS(NPS1),即使那些没有回答调查的客户也是如此。我们还模拟数据,这样我们知道真实效应。这里,新功能将NPS提高了0.4(对于任何商业标准来说,这是一个很高的数字,但请为了这个例子忍受一下)。我们还假设新功能和客户满意度都会增加回应NPS调查的可能性,就像我们在前面的图中所示的那样。有了测量反事实的能力,如果你按治疗组和对照组汇总数据,这就是你看到的情况:
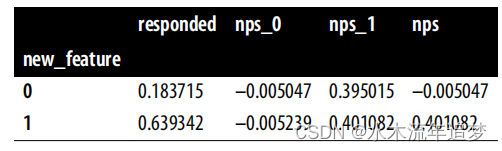
首先,注意到有63%的拥有新功能的客户回应了NPS调查,而对照组中只有18%的客户回应了它。接下来,如果你看治疗组和对照组的行,你会看到从NPS0到NPS1增加了0.4。这仅仅意味着新功能对两组的影响都是0.4。最后,注意到治疗组(new_feature=1)和对照组(new_feature=0)之间的NPS差异大约是0.4。再次,如果你能看到那些没有回应NPS调查的客户的NPS,你只需比较治疗组和对照组就能得到真实的ATE。
当然,在现实中,你无法看到NPS0和NPS1列。你也看不到这样的NPS列,因为你只有那些回应了调查的客户(对照组的18%和治疗组的63%)的NPS: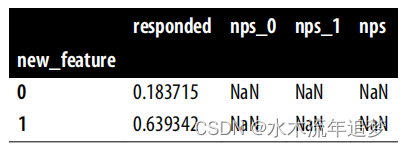
如果你进一步根据回应者细分分析,你会看到那些回应了调查的客户的NPS。但请注意,在这个群体中,治疗组和对照组之间的差异不再是0.4,而只是大约一半(0.22)。怎么会这样呢?这全都是由于选择偏倚:

加入那些无法观测的数量,你可以看到正在发生什么(在这里专注于回应者群体):
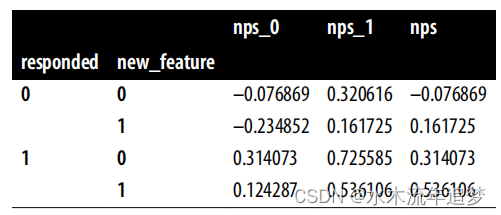
最初,治疗组和对照组在基线满意度Y0方面是可比的。但一旦你对那些回应了调查的人进行条件化,治疗组的基线满意度E(Y0|T=0,R=1)低于E(Y0|T=1,R=1)。这意味着,在对那些回应的人进行条件化之后,治疗组和对照组之间简单的平均数差异并不能识别ATE:
如果结果,即客户满意度,影响了回应率,那个偏差项将不会为零。由于满意的客户更可能回答NPS调查,因此在这种情况下,识别是不可能的。如果治疗增加了满意度,那么对照组将包含更多基线满意度高于治疗组的客户。这是因为治疗组将包括那些本来就很满意(高基线满意度)的客户,加上那些原本满意度较低,但由于治疗,变得更满意并回应了调查的客户。
















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











