







Image-to-Image Translation with Conditional Adversarial Networks
问题:欧几里得距离会导致"模糊"的现象,因为它是在所有训练集上取平均得到的。
CGAN是一种解决方法:
其结构为:
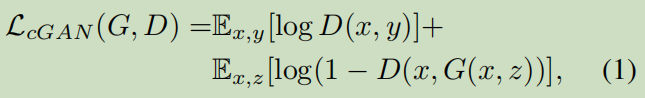
传统的GAN是这样的,等式右边第一项少了x:
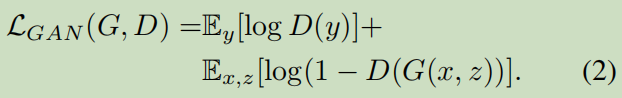
同时尝试利用L1距离来减少“blurring”,
![]()
最终的目标函数长这样:
![]()
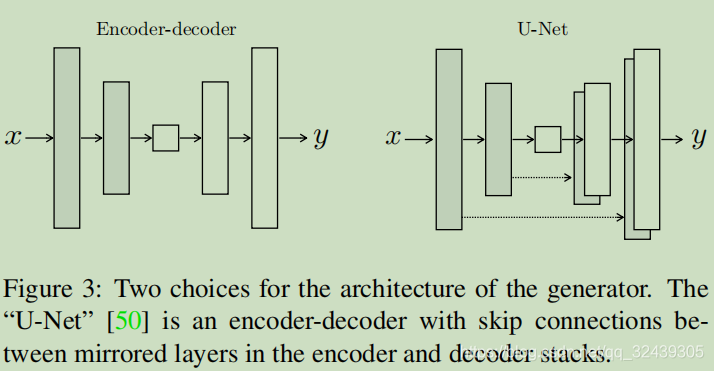
U-net被用于图像分割,在我之前关于Nature GAN的博客中也有用到。
关于生成器,采用了马可夫模型(Markovian model )
许多情况下,它们可以准确地捕获低频率。对于出现这种情况的问题,我们不需要一个全新的框架来强制低频率的正确性。 L1已经做好了。为了模拟高频,将我们的注意力限制在局部图像块中的结构就足够了。因此,我们设计了一个鉴别器体系结构 - 我们称之为PatchGAN - 仅在补丁规模上惩罚结构。该鉴别器试图对图像中的每个N×N补片是真实的还是假的进行分类。我们在图像上运行这个鉴别器卷积,平均所有响应以提供D的最终输出.我们证明N可以比图像的完整尺寸小得多,并且仍然可以产生高质量的结果。这是有利的,因为较小的PatchGAN具有较少的参数,运行得更快,并且可以应用于任意大的图像。
优化和推理
正如原始GAN论文中所建议的那样,我们不是将G训练为最小化log(1 - D(x,G(x,z)),而是训练最大化log D(x,G(x,z)).此外,我们在优化D的同时将目标除以2,这减慢了D学习相对于G的速率。我们使用minibatch SGD并应用Adam优化器,学习率为0.0002,并且动量参数β1= 0.5,β2= 0.999。
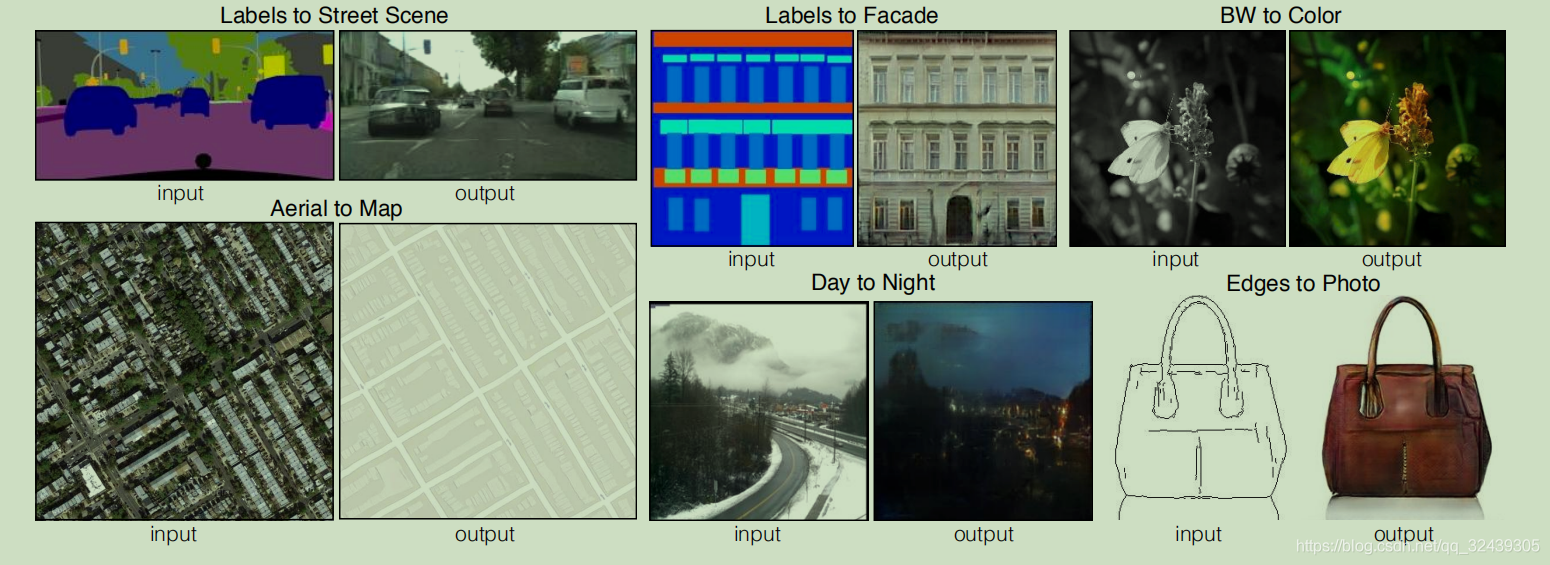
附:数据集


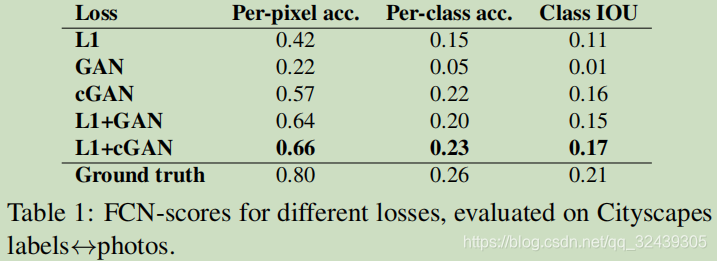
IOU 为目标窗口交叠率
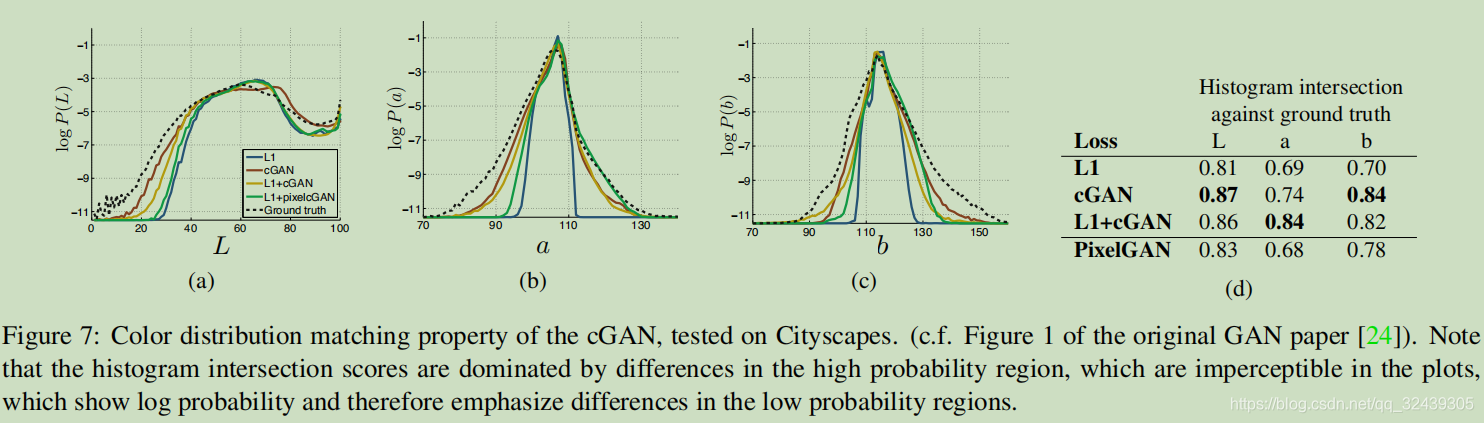
总结
本文的结果表明,cGAN是许多图像到图像转换任务的有前途的方法,特别是涉及高度结构化图形输出的任务。这些网络学习了适应手头任务和数据的损失,这使得它们可以在各种环境中使用。














 1550
1550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









