







1、path 环境变量的作用:
为了让 cmd 找到各种命令 exe 工具,配 path 环境变量就找 exe 所在目录配置就可以了。
C:\Anaconda3\Scripts---找pip.exe
C:\Anaconda3----python.exe
多个版本,如何共存?
python3.7
anaconda
放在前面的先被使用
2、修改完 path,要重启 cmd
where python
path
------------
pip install redis
pip install aiohttp
pip install asyncio
一、反爬策略
- 封装请求头
- user-agent
- referer
- cookie
- 限制访问频率
- 代理池
- 在用户访问高峰期进行爬取,冲散日志。
- 设置等待时长。
time.sleep()
- ajax 异步请求,用接口获取数据。
- 能一次性获取的数据,绝不发送第二次请求(获取数据的过程中尽量减少请求次数。)
- 能在列表页获取的数据,绝不进详情页
- 页面内容是 js 代码。
- selenium + phantomjs 的组合进行页面内容的获取。
二、html页面技术
1、js
页面在请求 html 的过程中,服务器返回 html,同时还会请求 js 文件。
2、jquery
jQuery 是 js 库,为了方便 js 开发。一个网站使用 jQuery 的特征,就是源代码里包含了 jQuery入口,比如:
<script type="text/javascript" src="http://statics.huxiu.com/w/mini/static_2015/js/sea.js?v=201601150944"></script>
如果你在一个网站上看到 jQuery,那么采集这个网站的数据的时候要格外小心。jQuery 可以动态地创建 HTML 内容,只有在 JavaScript 代码执行之后才会显示。如果你用传统的方法采集页面内容,就只能获得 JavaScript 代码执行之前页面上的内容。
3、ajax
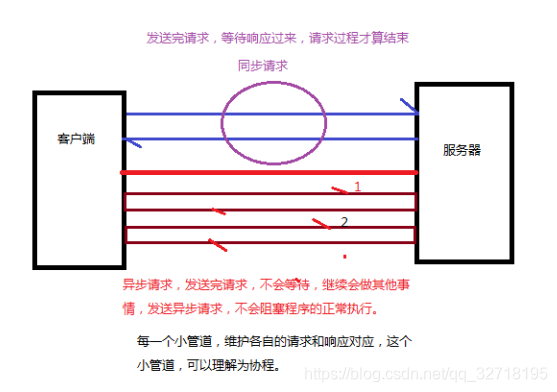
ajax :web的异步请求技术
同步请求,异步请求。
三、selenium 和 phantomjs
1、什么是 selenium?
selenium 是一个 web 自动化测试工具。但是它本身是不带浏览器的。这个工具其实就是作为一些外部工具驱动来使用的,可以控制一些外部应用来完成自动化测试。
2、什么是 phantomjs?
phantomjs:他其实就是一个内置无界面浏览器引擎。 — 无界面可以提高程序运行速度。
因为 phantomjs 是一个浏览器引擎,所以他最大的功能就是执行页面的 js 代码。
3、安装 selenium 和 phantomjs
selenium 安装:pip install selenium==2.48.0
phantomjs 安装:
百度搜索’phantomjs镜像’ -->下载一个Windows版本的 -->phantomjs-2.1.1-windows.zip
可视化的 chrome 浏览器插件,chromedriver 安装:
百度搜索 “chromedriver镜像” --> 保证 chrome 是正版 -->查看自己 chrome 的版本号 -->找一个和自己版本号最接近的版本下载。
将下载好的 exe 文件复制到:C:\Anaconda3\Scripts
4、案例:百度(selenium)
# 导包
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# 1、创建一个浏览器驱动
driver = webdriver.Chrome()
# 2、用浏览器请求url
driver.get('https://www.baidu.com/')
# 在百度的输入框里面输入python爬虫,搜索
input = driver.find_element_by_id('kw')
print(input) # WebElement对象
# WebElement其实就是页面中一些web组件。div,span,input
# WebElement可以做什么呢?
# click()
# send_keys()
# 截屏
# driver.save_screenshot('before.png')
input.send_keys(u'python爬虫')
# driver.save_screenshot('after.png')
# 点击百度一下
driver.find_element_by_id('su').click()
"""
哪些方法可以得到WebElement对象?
find_element_by_id --通过id来查找
find_element_by_css_selector --通过css选择器查找
find_element_by_xpath --通过xpath表达式查找
"""
# 获取元素的坐标
# print(input.location)
# 元素的大小
# print(input.size)
# 获取属性值
# print(input.get_attribute('value'))
# 快捷键的使用
input.send_keys(Keys.CONTROL,'a')
input.send_keys(Keys.CONTROL,'x')
input.send_keys(u'人工智能')
driver.find_element_by_id('su').click()
# driver.quit() # 退出浏览器
driver.close() # 关闭当前页
5、案例:爬取豆瓣图书(页面内容是js代码)
请求url:https://search.douban.com/book/subject_search?search_text=python&cat=1001&start=0
要求:
- 实现分页
- 字段
- 书名
- 评分
- 作者
- 出版社
- 出版日期
- 价格
- 详情页url
- 将数据写入excel中
思考:返回的response.text中没有书籍信息,为什么会出现这样的情况?该怎么解决?
返回的页面内容是 js 代码,用 selenium + phantomjs 解析页面内容
import time,os
import requests
from lxml import etree
from selenium import webdriver
import xlwt
import xlrd
from xlutils.copy import copy
# 实现excel的追加写入
def write_to_excel_append(books,filename):
# 要写入数据的行数
index = len(books)
# 打开工作簿
work_book = xlrd.open_workbook(filename) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5881
5881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









