






概述
在组件开发迭代的过程中,随着使用时间的增加,数据库中的数据量也不断增加,因此数据库查询越来越慢。
通常加速数据库的方法很多,如添加特定的索引,将日志目录换到单独的磁盘分区,调整数据库引擎的参数等。这些方法都能将数据库的查询性能提高到一定程度。
对于许多应用数据库来说,许多数据是历史数据并且随着时间的推移它们的重要性逐渐降低。如果能找到一个办法将这些可能不太重要的数据隐藏,数据库查询速度将会大幅提高。可以通过DELETE来达到此目的,但同时这些数据就永远不可用了。
分区表是关系型数据库提供的一个亮点特性,比如Oracle对分区表的支持已经非常成熟,广泛使用于生产系统,PostgreSQL也支持分区表,只是道路有些曲折,早在10版本之前PostgreSQL分区表一般通过继承加触发器方式实现,这种分区方式不能算是内置分区表,而且步骤非常烦琐,PostgreSQL10版本一个重量级的新特性是支持内置分区表,在分区表方面前进了一大步,目前支持范围分区和列表分区。
表分区
表分区是指在逻辑上将一个大表拆分为较小的物理部分。分区可以带来几个好处:
- 在某些情况下,查询性能可以显著提高,尤其是当表的大多数大量访问的行都放在单个分区或少量分区中时。分区取代了索引的前导列,减小了索引大小,使索引中大量使用的部分更可能适合内存。
- 当查询或更新访问单个分区的很大一部分时,可以通过利用该分区的顺序扫描来提高性能,而不是使用分散在整个表中的索引和随机访问读取。
- 如果分区设计中计划了分区,则可以通过添加或删除分区来完成批量加载和删除。使用执行或删除单个分区比批量操作快得多。
- 很少使用的数据可以迁移到更便宜、更慢的存储介质。
只有当一个表会很大时,这些好处通常才是值得的。表将从分区中受益的确切点取决于应用程序,尽管经验法则是表的大小应超过数据库服务器的物理内存。
什么时候考虑使用表分区Partition?
- 一张表的查询速度已经慢到影响使用的时候。
- sql经过优化
- 数据量大
- 表中的数据是可以分段的
- 对数据的操作往往只涉及一部分数据,而不是所有的数据
随着使用时间的增加,数据库中的数据量也不断增加,因此数据库查询越来越慢。
加速数据库的方法很多,如添加特定的索引,将日志目录换到单独的磁盘分区,调整数据库引擎的参数等。这些方法都能将数据库的查询性能提高到一定程度。
对于许多应用数据库来说,许多数据是历史数据并且随着时间的推移它们的重要性逐渐降低。如果能找到一个办法将这些可能不太重要的数据隐藏,数据库查询速度将会大幅提高。可以通过DELETE来达到此目的,但同时这些数据就永远不可用了。
PostgreSQL 11 内置分区分表
PostgreSQL 中的分区支持
PostgreSQL从10.0版本开始,开始引入内置分区机制partition。
Partition数据库表分区把一个大的物理表分成若干个小的物理表,并使得这些小物理表在逻辑上可以被当成一张表来使用。
- 主表/父表/Master Table 该表是创建子表的模板。它是一个正常的普通表,但通常情况下它应该并不储存任何数据,而是将所有记录重定向到子表中进行存储。
- 子表/分区表/Child Table/Partition Table 这些表继承并属于一个主表。子表中存储所有的数据。主表与分区表属于一对多的关系,也就是说,一个主表包含多个分区表,而一个分区表只从属于一个主表
数据库表分区的优势
- 在特定场景下,查询性能可以极大提高,尤其是当大部分经常访问的数据记录在一个或少数几个分区表上时。表分区减小了索引的大小,并使得常访问的分区表的索引更容易保存于内存中。
- 当查询或者更新访问一个或少数几个分区表中的大部分数据时,可以通过顺序扫描该分区表而非使用大表索引来提高性能。
- 可通过添加或移除分区表来高效的批量增删数据。如可使用ALTER TABLE NO INHERIT可将特定分区从主逻辑表中移除(该表依然存在,并可单独使用,只是与主表不再有继承关系并无法再通过主表访问该分区表),或使用DROP TABLE直接将该分区表删除。这两种方式完全避免了使用DELETE时所需的VACUUM额外代价。
- 很少使用的数据可被迁移到便宜些的慢些的存储介质中
以上优势只有当表非常大的时候才能体现出来。一般来说,当表的大小超过数据库服务器的物理内存时以上优势才能体现出来。
PostgreSQL 11 的新特性
PostgreSQL从10版本支持通过表继承来实现表的分区。父表是普通表并且正常情况下并不存储任何数据,它的存在只是为了代表整个数据集。
从11版本开始PostgreSQL可实现如下3种表分区。
- 范围分区 每个分区表包含一个或多个字段组合的一部分,并且每个分区表的范围互不重叠。比如可近日期范围分区
- 列表分区 分区表显示列出其所包含的列值
- 哈希分区 PostgreSQL11版本引入,可以根据自定义的hash规则,通过为每个分区指定模数和余数来对表进行分区。每个分区将保存分区键的哈希值除以指定的模数将生成指定余数的行。
如果项目组件的数据表需要使用上面未列出的表分区形式,可以使用替代方法(如基于10版本的继承和视图)。这些方法通常更具有灵活性,但可能部分特性没有内置的分区优化,所幸的是,目前PostgreSQL 11 版本已经对此做了大量优化。
PostgreSQL 内置分区表使用
PostgreSQL 10 一个重量级新特性是支持内置分区表,用户不需要预先在父表上定义INSERT、DELETE、UPDATE 触发器,对父表的DML操作会自动路由到相应分区,相比传统分区表大幅度降低了维护成本,目前仅支持范围分区和列表分区,本小节将以创建范围分区表为例,演示 PostgreSQL 10 内置分区表的创建、使用与性能测试。
创建分区表
创建分区表的主要语法包含两部分:创建主表和创建分区。创建主表语法如下:
代码语言:javascript
复制
CREATE TABLE table_name ( ... )
{ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) }
创建主表时须指定分区方式,可选的分区方式为RANGE范围分区或LIST列表分区,并指定字段或表达式作为分区键。 创建分区的语法如下:
代码语言:javascript
复制
CREATE TABLE table_name
PARTITION OF parent_table [ (
) ] FOR VALUES partition_bound_spec
创建分区时必须指定是哪张表的分区,同时指定分区策略partition_bound_spec,如果是范围分区,partition_bound_spec须指定每个分区分区键的取值范围,如果是列表分区partition_bound_spec,需指定每个分区的分区键值。
PostgreSQL10创建内置分区表主要分为以下几个步骤:
- 创建父表,指定分区键和分区策略。
- 创建分区,创建分区时须指定分区表的父表和分区键的取值范围,注意分区键的范围不要有重叠,否则会报错。
- 在分区上创建相应索引,通常情况下分区键上的索引是必须的,非分区键的索引可根据实际应用场景选择是否创建。
内置分区表注意事项
使用内置分区表有以下注意事项:
- 1.当往父表上插入数据时,数据会自动根据分区键路由规则插入到分区中,目前仅支持范围分区和列表分区。
- 2.分区表上的索引、约束需使用单独的命令创建,目前没有办法一次性自动在所有分区上创建索引、约束。
- 3.内置分区表不支持定义(全局)主键,在分区表的分区上创建主键是可以的。
- 4.内置分区表的内部实现使用了继承。
- 5.如果UPDATE语句的新记录违反当前分区键的约束则会报错,UPDAET语句的新记录目前不支持跨分区的情况。
- 6.性能方面:根据本节的测试场景,内置分区表根据非分区键查询相比普通表性能差距较大,因为这种场景分区表的执行计划会扫描所有分区;根据分区键查询相比普通表性能有小幅降低,而查询分区表子表性能相比普通表略有提升。
- 继承式表分区的使用
PostgreSQL从10版本开始,引入了基于继承的分区机制。
创建主表/父表
不用为该表定义任何检查限制,除非需要将该限制应用到所有的分区表中。同样也无需为该表创建任何索引和唯一限制。这里我们以项目开发中常用到的告警查询为例,创建一张tb_test_alarm表。
代码语言:javascript
复制
CREATE TABLE public.tb_test_alarm (
id varchar(64) NOT NULL,
alarm_type varchar(10) NOT NULL,
happen_time timestamptz NOT NULL,
create_time timestamptz NULL,
update_time timestamptz NULL,
"desc" text NULL,
device_id varchar(64) NOT NULL,
CONSTRAINT tb_test_pk PRIMARY KEY (id)
);
创建的表结构如下图所示

创建子分区表
每个分区表必须继承自主表,并且正常情况下都不要为这些分区表添加任何新的列。子表尽量保持和父表一致的字段。
此处以每月分区表为例
代码语言:javascript
复制
create table tb_test_alarm_2020_12 () inherits (tb_test_alarm);
create table tb_test_alarm_2020_11 () inherits (tb_test_alarm);
create table tb_test_alarm_2020_10 () inherits (tb_test_alarm);
create table tb_test_alarm_2020_09 () inherits (tb_test_alarm);
创建分区表路由函数
代码语言:javascript
复制
--创建分区函数
CREATE OR REPLACE FUNCTION alarm_partition_trigger()
RETURNS TRIGGER AS $$
BEGIN
IF NEW.happen_time >= '2020-09-01 00:00:00' and NEW.happen_time <= '2020-09-30 23:59:59'
THEN
INSERT INTO tb_test_alarm_2020_09 VALUES (NEW.*);
ELSIF NEW.happen_time >= '2020-10-01 00:00:00' and NEW.happen_time <= '2020-10-31 23:59:59'
THEN
INSERT INTO tb_test_alarm_2020_10 VALUES (NEW.*);
ELSIF NEW.happen_time >= '2020-11-01 00:00:00' and NEW.happen_time <= '2020-11-30 23:59:59'
THEN
INSERT INTO tb_test_alarm_2020_11 VALUES (NEW.*);
ELSIF NEW.happen_time >= '2020-12-01 00:00:00' and NEW.happen_time <= '2020-12-31 23:59:59'
THEN
INSERT INTO tb_test_alarm_2020_12 VALUES (NEW.*);
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
--挂载分区Trigger
CREATE TRIGGER insert_almart_partition_trigger
BEFORE INSERT ON tb_test_alarm
FOR EACH ROW EXECUTE PROCEDURE alarm_partition_trigger();
插入成功后,可以看到100万条数据成功执行了插入,且由于我们前面编写的分区路由函数生效,数据会根据happen_time自动的插入到子表中。这里数据仍会显示在父表中,但是实际上父表仅仅作为整个分区表结构的展示,实际插入的记录是保存在子表中。如下图所示。
设置分表约束前,查询效率。执行查询语句
代码语言:javascript
复制
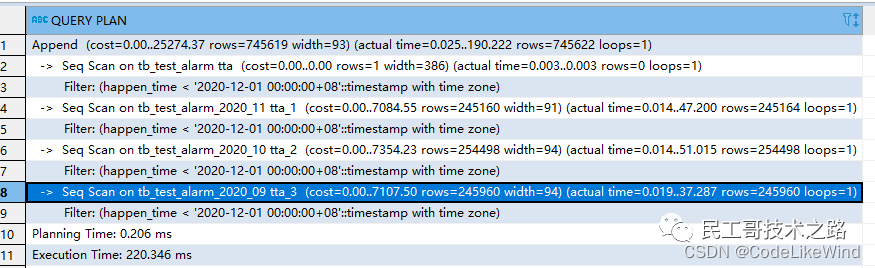
explain analyze select * from tb_test_alarm tta where happen_time < '2020-12-01 00:00:00'
结果如下:

需要消耗 474.307ms,扫描主表下所有子表来查询。
在执行查询时,PostgreSQL默认将会把查询条件应用到该表结构的所有分区上,因为PosgreSQL不知道这些分区表表名和表内容的关联性。于是需要添加表约束,它会告诉数据库这些表的内容,并允许规划器根据条件去查询对应的子分区,这样在很多情况下,能极大地加快查询速度。
应用分区表约束的语法为ADD CHECK(CONDITION)
代码语言:javascript
复制
ALTER TABLE tb_test_alarm_2020_12
ADD CONSTRAINT tb_test_alarm_2020_12_check_time_key
CHECK (happen_time>='2020-12-01 00:00:00' and happen_time <= '2020-12-31 23:59:59');
ALTER TABLE tb_test_alarm_2020_11
ADD CONSTRAINT tb_test_alarm_2020_11_check_time_key
CHECK (happen_time>='2020-11-01 00:00:00' and happen_time <= '2020-11-30 23:59:59');
ALTER TABLE tb_test_alarm_2020_10
ADD CONSTRAINT tb_test_alarm_2020_10_check_time_key
CHECK (happen_time>='2020-10-01 00:00:00' and happen_time <= '2020-10-31 23:59:59');
ALTER TABLE tb_test_alarm_2020_09
ADD CONSTRAINT tb_test_alarm_2020_09_check_time_key
CHECK (happen_time>='2020-09-01 00:00:00' and happen_time <= '2020-09-30 23:59:59');
建议对每个分区表增加一个特定的约束,以防止全表查询扫描查询时间过长。
并且在PostgreSQL中,这些表约束是可以重叠的,但一般来说创建非重叠的表约束会更好。重叠的表约束只有在一定特定场景下有意义。
在创建好上述告警信息表及分区表后,我们可以执行一次插入操作和查询,并分析其查询计划来查看分区是否生效以及效果如何。
再次执行查询操作,会发现,sql没有去查询表4的内容,时间也有所缩短:
参考文章:https://blog.csdn.net/Auspicious_air/article/ details/130058329 https://blog.csdn.net/qq_36125072/ article/details/125523756
















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











