









SNMP企业级子代理开发流程
SNMP子代理开发
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
项目背景
为几家不同公司提供SNMP网管服务,根据不同公司提供的mib文件父节点不同,每一个mib文件都可以正常使用snmpget/snmptrap/snmpwalk/snmpbulk等功能
开发前需要了解的SNMP基础知识
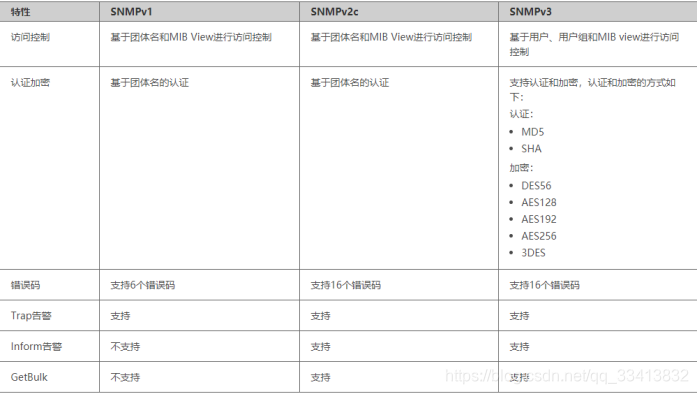
为不同种类的设备、不同厂家生产的设备、不同型号的设备,定义为一个统一的接口和协议,使得管理员可以是使用统一的外观面对这些需要管理的网络设备进行管理。通过网络,管理员可以管理位于不同物理空间的设备,从而大大提高网络管理的效率,简化网络管理员的工作。对于网络管理,我们面对的数据是设备的配置、参数、状态等信息,面对的操作是读取和设置;同时,因为网络设备众多,为了能及时得到设备的重要状态,还要求设备能主动地汇报重要状态,其中Snmp有三个主要报文形式:
- Get:读取网络设备的状态信息。
- Set:远程配置设备参数。
- Trap:管理站及时获取设备的重要信息。


子代理开发流程
1.准备好mib2c环境
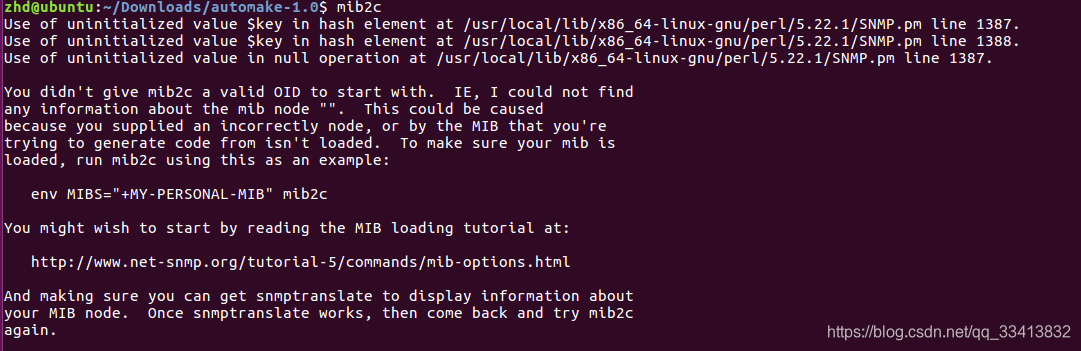
- 如图是安装net-snmp后产生可执行的mib2c文件,当时在使用时发生错误,使用apt-get install libsnmp-perl搭建mib2c环境即可
==如命令所示,根据你提供的mib文件可以生成相应模板
这里还没区分为agent开发,在使用命令编译后,可选项有scalar(标量),标量可能是一个固定的数据,电源信息风扇信息等,区别于scalar的还有table类型,即一张表,具体交换机应用场景有端口信息表,模块状态对应表等。
- 生成标量代码
env MIBS="+/usr/share/snmp/mibs/XXX-PFXOE-MIB.txt" mib2c -c mib2c.scalar.conf pfxoe
- 生成通知代码
env MIBS="+/usr/share/snmp/mibs/XXX-PFXOE-MIB.txt" mib2c -c mib2c.notify.conf pfxoeTraps
- 生成表格代码
env MIBS="+/usr/share/snmp/mibs/XXX-PFXOE-MIB.txt" mib2c -c mib2c.iterate.conf serviceInfo
2.准备好mib文件
编写符合标准的mib文件
3.在设备上正常启动snmp主服务
service snmpd status即可
其中snmpd为服务端,snmp为客户端,这点需要了解
4. 修改处理代码,根据数据类型和长度
如1可以生成三个.c后缀的文件,函数名根据你提供的mib文件生成,可以看作是一种模板,包括trap/table/scalar类型,
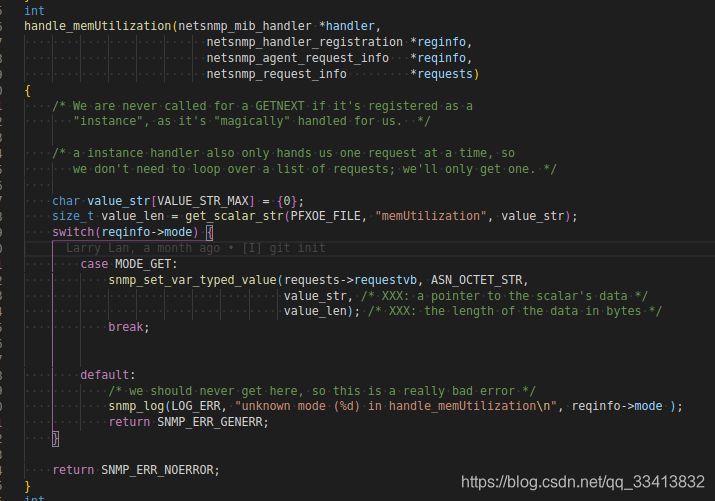
调试成功后
net-snmp-config --compile-subagent --cflags -DPEN=90909 snmp-subagent-90909 handle.c pfxoe.c serviceInfo.c pfxoeTraps.c
- 即可生成子代理
__ 需用sudo权限运行 __
SNMP配置文件中可以做哪些事情?
配置文件在/etc/snmp/snmpd.conf下
一些功能在缺省文件下以及给出示例,根据net-snmp版本不同修改的方式会有所不同
作者开发是基于net-snmp 5.7.3版本
其中需要注意的是每次修改后都要重启snmp服务 指令可以为service snmpd restart
主要包括
- 1.配置用户
- 2.控制提供snmp服务的oid节点
- 3.配置发送trap用户/团体名/密钥/版本/类型
SNMP的v3用户如何删除/新增以及V3TRAP设置
createUser noAuthUser
rwuser noAuthUser noauth
createUser authOnlyUser MD5 authPassword
rwuser authOnlyUser auth
createUser authPrivUser MD5 authPassword DES privPassword
rwuser authPrivUser priv
所代码块所示,需要在配置文件中添加如上命令,重启snmp服务后,会自动编译在生成md5/des密钥在/var/lib/snmp/snmpd.conf下,且不能更改/var/lib/snmp/snmpd.conf这个文件(你改了也没用)
主要支持三种类型用户,可选MD5/DES加密认证协议
- 删除
snmpusm -v 3 -u noAuthUser -l noAuthNoPriv localhost delete noAuthUser snmpusm -v 3 -u authOnlyUser -l authNoPriv -a MD5 -A authPassword localhost delete authOnlyUser snmpusm -v 3 -u authPrivUser -l authPriv -a MD5 -A authPassword -x DES -X privPassword localhost delete authPrivUser sudo /etc/init.d/snmpd restart
V3trap在网上不多见,在官网上是这样描述
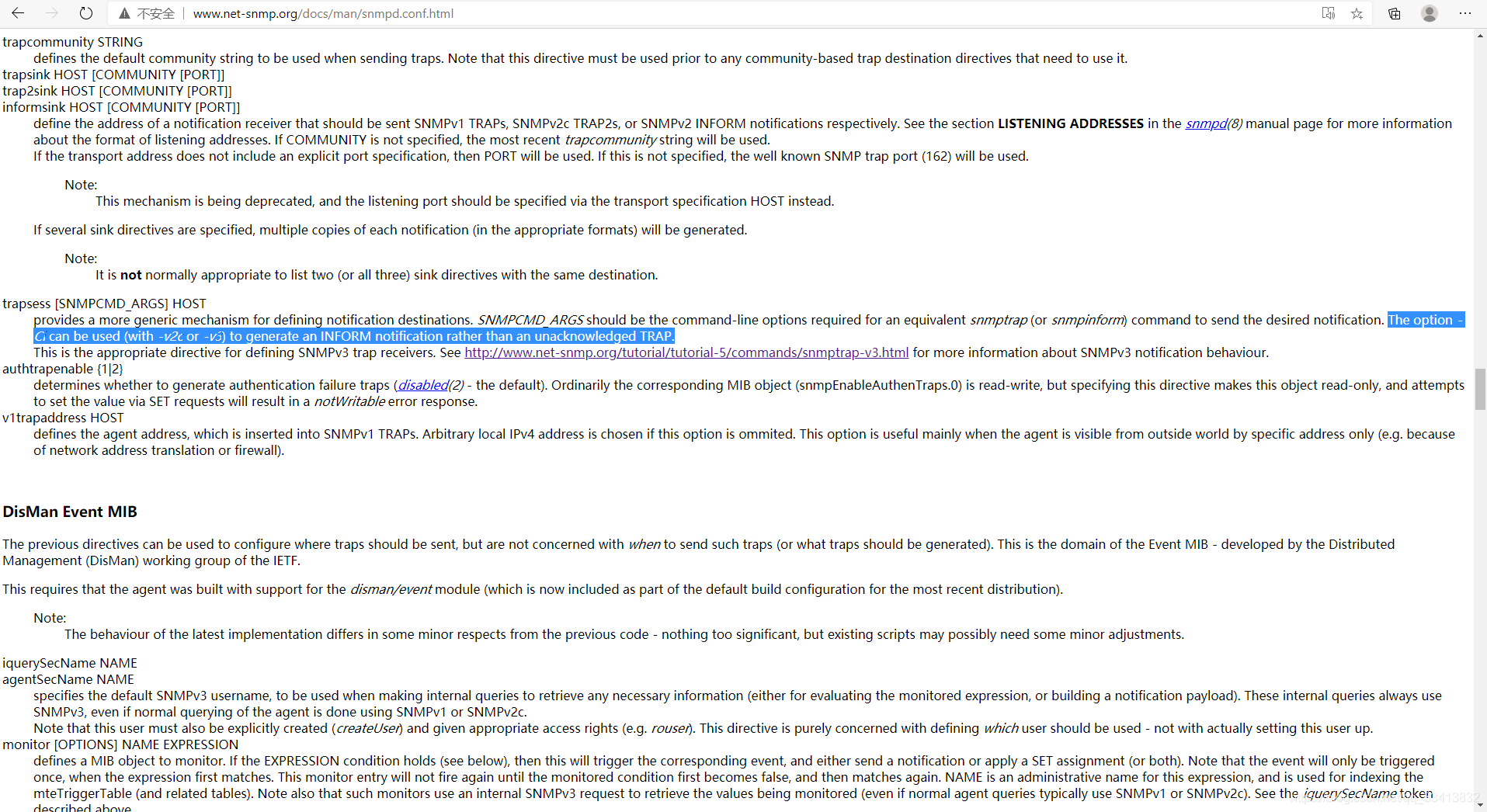
测试后命令如下
#trapsess -v3 -u noAuthUser localhost
#trapsess -v3 -u authOnlyUser 192.168.0.203
#trapsess -v3 -u authPrivUser 192.168.0.203:166
# send SNMPv3 INFORMs
#trapsess -v3 -Ci -u noAuthUser localhost
#trapsess -v3 -Ci -u authOnlyUser 192.168.0.203
#trapsess -v3 -Ci -u authPrivUser 192.168.0.203:166
加上Ci即为inform类型
在开启mib浏览器时,你需要知道的事情
SNMP采用UDP 161端口接收和发送请求,162端口接收trap,执行SNMP的设备缺省都必须采用这些端口,但端口是可配置的,也在snmp配置文件中体现
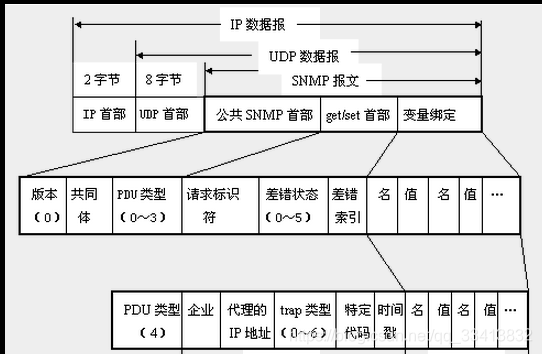
- 当你想用snmpget的时候,需要选择你是v1/v2c/v3类型登录,其中v2c/v3还需要输入团体号,v3需要输入密码
测试过程中遇到的坑以及问题
- TRAP方面
因为是子代理开发,在单位时间触发一次trap条件时,却有两次trap,且第一次都为3s左右,而trap定时器写的30s,通过排查发现是init_traps函数的问题,可能是snmp主服务也在调用这个定时器,修改函数名称即可解决该问题
- 消息中间件方面
端口拆分引起的index问题,因为通信是用的csv文件进行操作,agent通过读取csv文件信息反馈给client,所以每个端口的index需保持一致
csv文件里有空字符串情形,因为csv文件是逗号作为分隔符体现在代码中,在字符串处理方向上需要注意。
- 后台服务器方面
采用subprosess输入命令,因为需要支持用户用web操作配置snmp配置文件,所以需要开发一个可以替换snmpd.conf文件中某一行的代码,思路是遍历每一行,用一个备份文件存储每一行信息,用正则表达式选择是哪一行需要替换,以及替换文本是什么,如果没有这一行则在末尾新增。
端口/模块信息等则用REST服务端的多线程在后台进行处理更新
在写csv文件时,我用的是一个列表存储所有同类型元素的方法,想用列写入csv,但由于环境的特点,有时候一些信息获取不到,导致zip解析出的长度不一,zip方法遍历写csv时会取最短列表来写,导致行缺失.所以需要判断列表长度,对缺失的数据进行补全
def modify_file_line(file_path, items):
"""
Map each line of text,
If the re_key_word is not matched, this line will NOT be modified;
If the re_key_word is matched, the line will be modified to the set context, and the line will be deleted if it is found again;
If the full text does not match the re_key_word, add the set context at the end of the text.
"""
if not items:
return
if not isinstance(items, list):
return
config_bak = file_path + '.bak'
shutil.copy(file_path, config_bak)
f = open(file_path, 'w')
with open(config_bak) as fb:
written = False
for line in fb.readlines():
for i, item in enumerate(items):
if 're_key_word' not in item:
continue
if 'context' not in item:
continue
if re.match(item['re_key_word'], line) and not item.get('written'):
f.writelines(item['context'])
items[i].update(dict(written = True))
elif not i:
for re_str in map(lambda x: x['re_key_word'], items):
if re.match(re_str, line):
break
else:
f.writelines(line)
for i, item in enumerate(items):
if 're_key_word' not in item:
continue
if 'context' not in item:
continue
if not item.get('written'):
f.writelines(item['context'])
f.close()
os.remove(config_bak)














 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









