










address
http://urban-computing.com/pdf/kdd19-BinWang.pdf
ABSTRACT
- propose a novel negative log-likelihood error loss function(new loss function)
- single-value forecasting and uncertainty quantification(deep uncertainty quantification)
- this approach significantly improves accuracy by 47.76% , which is a state-of-the-art result on this benchmark dataset
一、INTRODUCTION
- The most common method currently utilized in meteorology is the use of physical models to simulate and predict meteorological dynamics known as numerical weather prediction, or NWP may not be reliable due to the instability
- the NWP may not be reliable due to the instability of these differential equations
- require big data and a tedious amount of feature engineering
二、RELATED WORKS
三、OUR METHOD
3.1 Problem Statement
3.1.1 Notations.
for a weather station s .

- E为历史气候特征数据
- D为将来的数字预报数值和station ID ,timestamps
- X为【ED】即输入的数据
- Y为目标预测数据,即这里应该算是ture target value
3.1.2 Task Definition
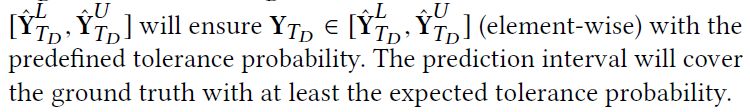
给于X, 预测Y的估计值。真实Y在估计近似Y的一个区间内,并满足一个容忍可能性
数据为当天凌晨3点到第二天的15点。即37个小时的预测区间。
target value为t2m、 rh2m、w10m 。
The proposed method can be easily extended for any time interval prediction and more target variables.
3.2 Information Fusion Methodology
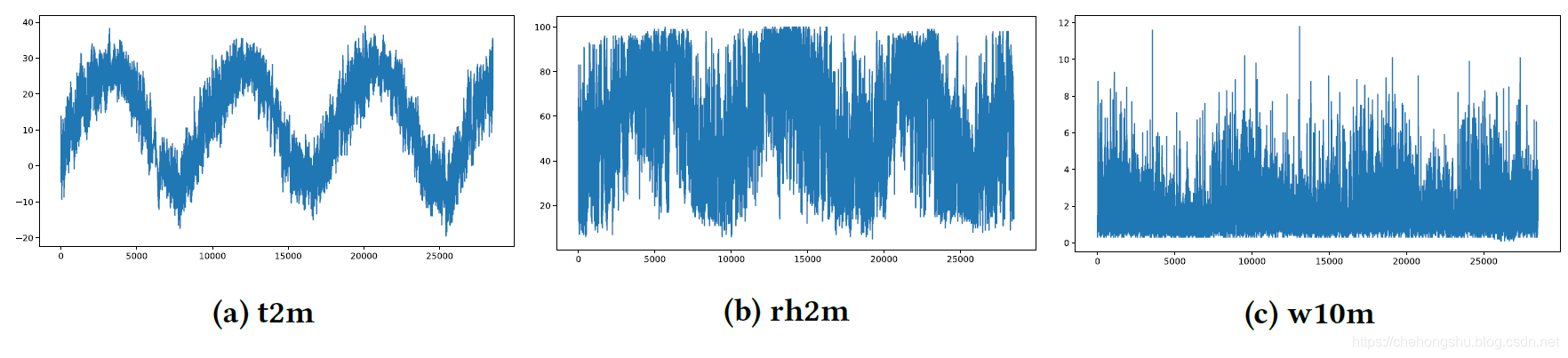
过去三年的target values,明显的可以看出t2m有季节性,二rh2m和w10m noise太多不予判断。
E用来建模近来的气候流体力学。

把NWP 加入到D中,这样可以很正确的吸取NWP中的重要的信息
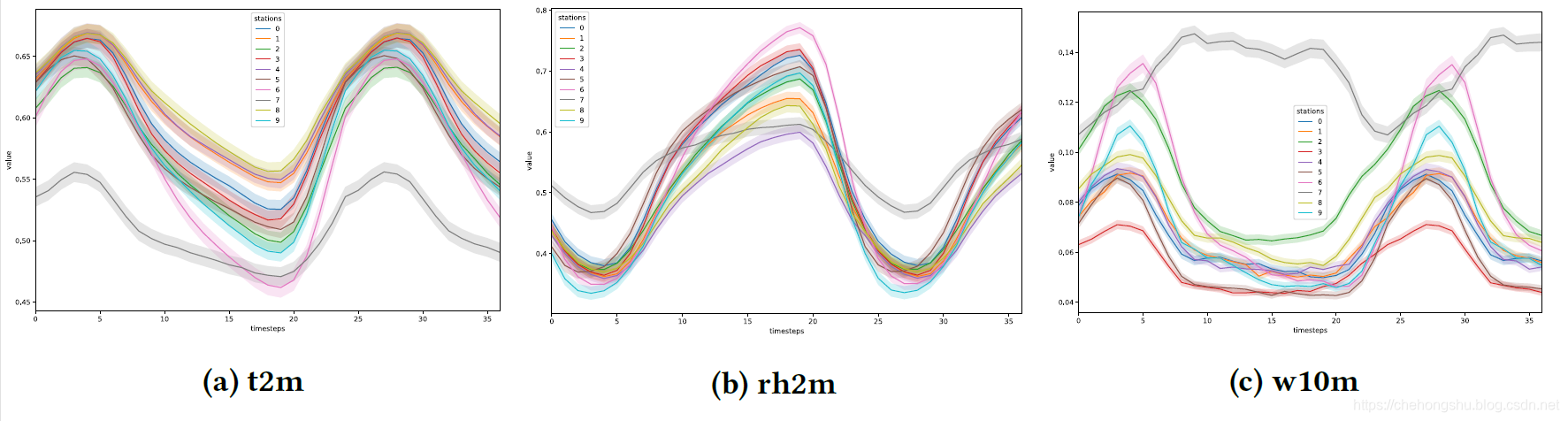
求出凌晨3点到第二天15点,时长为37个小时的每个时刻的该target值求得对应的mean值。
可以从图中明显存在 mean值和方差的统计不同,所谓方差也就是图像斜率,这里我个人理解为图形的变换趋势。
并且可以明显发现id为7的station和其他站点有明显的不同。
对应于每一个station的图形的每一个时刻的mean和方差也不同
最终解决方案,将station ID和time ID带入D中
3.3 Data Preprocessing
3.3.1 Missing values
有两种缺失值的情况
- 缺失一天(删除这一天的对应values)
- 缺失一天中的连续时间(用线性差值办法来解决)
3.3.2 Normalization of Continuous Variables
输入数据进行 normalization
输出的结果进行 denormalization
3.3.3 Category Variables
two category variables
- time ID
- station ID
Rather than hard-coding, such as onehot or sin-cosine coding.
3.3.4 Input/Output Tensors
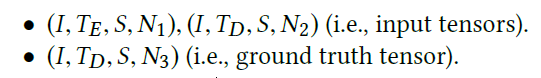
设定tensor每个dimension的类型数据。
- I day index
- T为time index
- S station index
- N为features
I is the date index and S is the station index.
这样的优点是 更好的扩展性和在实验中好检查。
3.4 Model Architecture
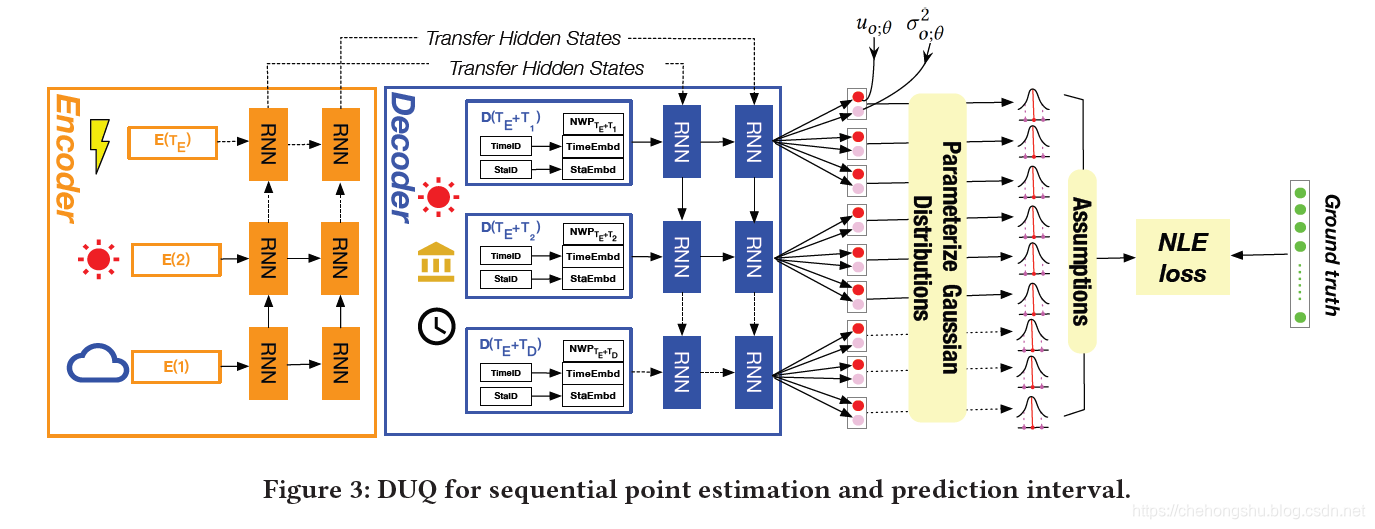
主要应用于seq2seq model framework(seq2seq tensorflow学习笔记)
encoder:

意思为通过输入E,extract representation c,这里的c ,paper中的解释是得到了从历史真实数据中提取出的气候动力学系数,并把这个值当做decoder的输入initial state
decoder:
decoder输入有timeID , stationID,以及UWP

并且在timeID和stationID后加了两个embedding层,来获得embedding representation,如下图所示
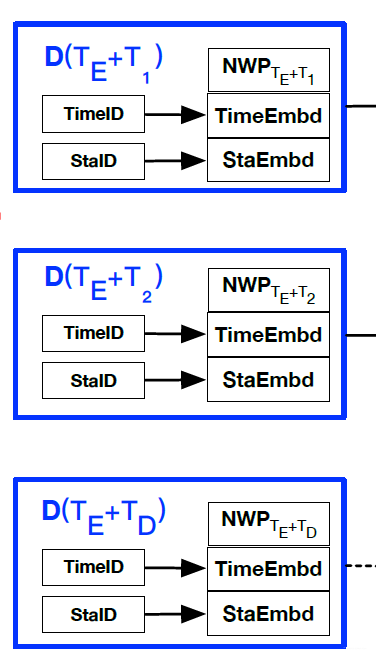
之后他这里稍微说了一下model的结构并且把encoder和decoder的输入当做一个输入为X,之后输出为一个点估计
这里需要读到后面才能知道,输出为每个target value的两个值一个是方差一个是平均值,所以文章中也提到可以估计出一个区间。

3.5 Learning Phase
DUQ 在每个timestamp预测的两个值为 mean和variance



- y0(t) 为第i天,第s个station,在timestep t的目标变量o的真实值。
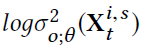 为方差
为方差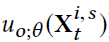 为mean
为mean
整个训练过程如图所示,这里比较easy,不做说明

3.6 Inference Phase
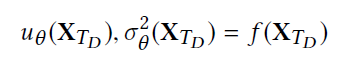
我个人感觉这篇论文看到这里才算是真的融会贯通了,输出就是mean和方差。

这里把上下界说的很清楚了,就是把方差当成偏差,之后用mean加减方差。
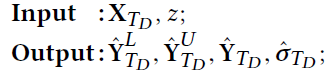
输出从左到右分别是,估计的下届,估计的上届,估计的target value, 方差
输出算出来的上下界需要进行denormalization
3.7 Inference Phase
3.8 Evaluation Metrics
3.8.1 Point Estimation Measurement.
利用RMSE来进行判断。
以下是每个station、每个时刻的一个target value的RMSE
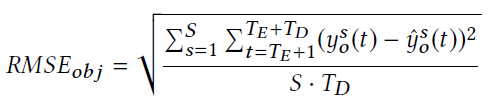
这里定义每一天的RMSE
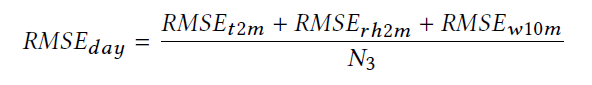
又定义了一个评分,SSobj越高,说明ML方法比NWP方法更好。
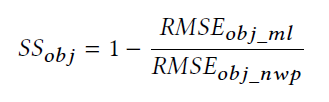
定义一天的
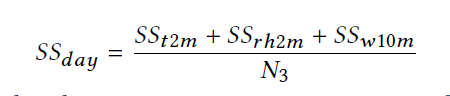
Savg为所有天的SSday的平均值
3.8.2 Prediction Interval Measurement.
为什么要有 预测空隙测量方法呢?因为本篇文章的亮点在于预测出一个上下界的范围。
接下来就是如何来计算出多少点在这个范围之内。
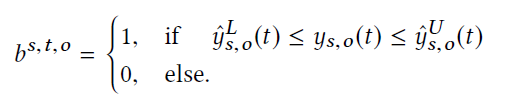
定义的这个小系数的主要作用就是在于,如果这个值在预测的估计上下限范围之内则为1.否则为0,可以把这个系数当做用来计算是否覆盖的一个中间计算变量。
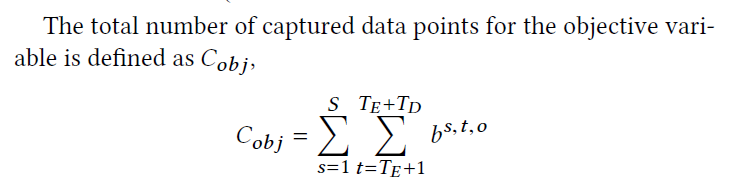
计算出所有的数量,即在每一个时刻,每一个站点的目标值是否在估计的范围之内。
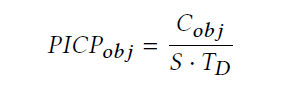
prediction interval coverage probability (PICP)即每一个站点和时刻的覆盖数,即预测间隔覆盖率
四. EXPERIMENTS AND PERFORMANCE ANALYSIS
4.1 Baselines

4.2 Experimental Environments
GPU+Keras
4.3 Parameter Settings for Reproducibility
paper说了一堆参数的问题,说了epoch不用太在意,因为使用了early-stopping。

- 1148 是训练集的天数 87是验证集的天数
- 28为之前可知的28个小时
- 37为预测的将来37个小时
- Encoder的9为观测数据特征值
- Decoder inputs的31为NWP的29个特征值+stationID+timeID
- Decoder outpus的3为三个target value的真实观测数据。
4.4 Performance analysis
4.4.1 Effect of information fusion
对于有无obs和有无NWP最后得出结论
单独的obs或者NWP都是效果不好的
obs可以建模出一定的气象流体力学的系数
4.4.2 Effect of deep learning
深度学习好于机器学习
比较不同层或者同一层不同网络点的问题。
4.4.3 Effect of loss function.

通过early-stopping来计算iteration的时间,发现NLE loss所需的时间最长,paper中的解释是NLE loss 考虑到mean loss+variance loss。经过两个任务的优化过程,所以收敛时间最长,并且这种优化可能会相当于一种正则化的功能。
4.4.4 Effect of ensemble.
多个DUQ model ensemble效果更好
Quality of prediction interval
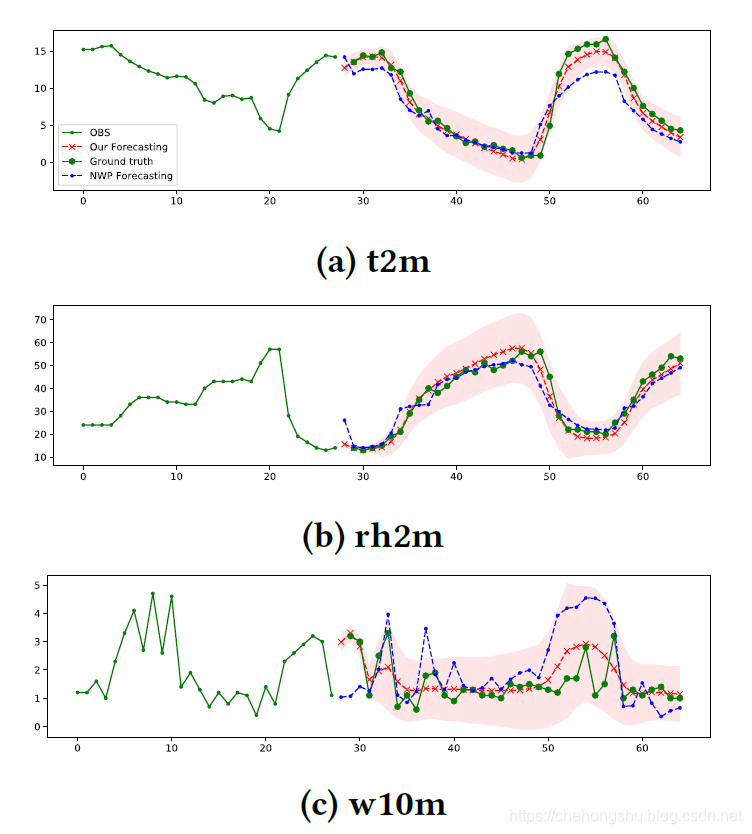
绿色为实际obs数据,右侧为UWP数据,点估计数据。还有预测区间估计。
区间估计可以给于更好的 旅游产品规划。 w10m波动较大,总体来说最难预测。
Future works
will be directed towards architecture improvement (e.g., attention
mechanism), automatic hyperparameter-tuning, and theoretical
comparison between NLE and MSE/MAE.














 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









