







spark+windows环境搭建
下载链接http://spark.apache.org/downloads.html

请先搭建scala+windows环境
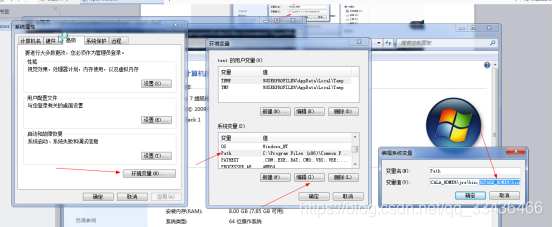
下载完后配置环境变量
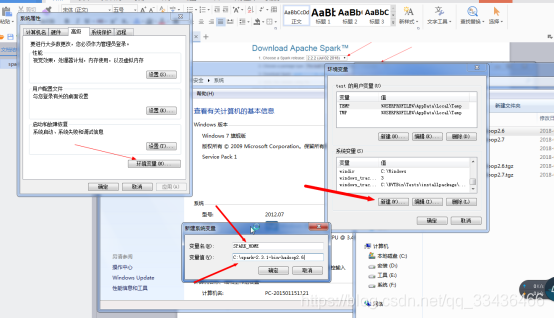
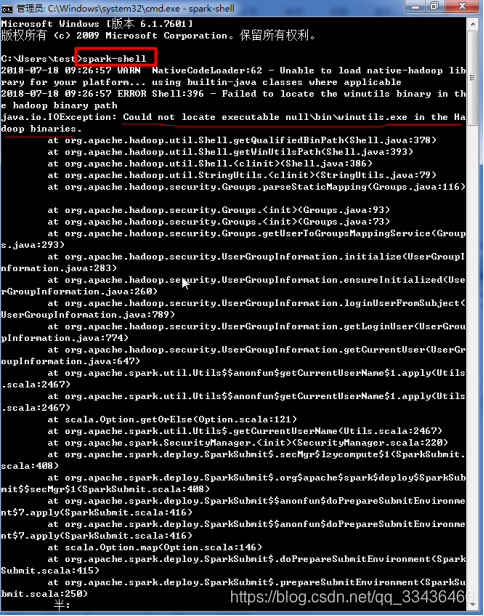
运行spark-shell报错解决办法:
hadoop各版本下载链接https://archive.apache.org/dist/hadoop/common/
配置hadoop+windows环境变量
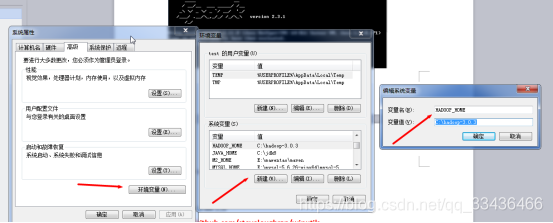
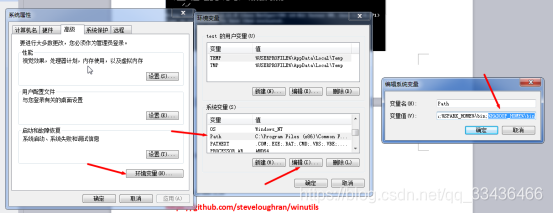
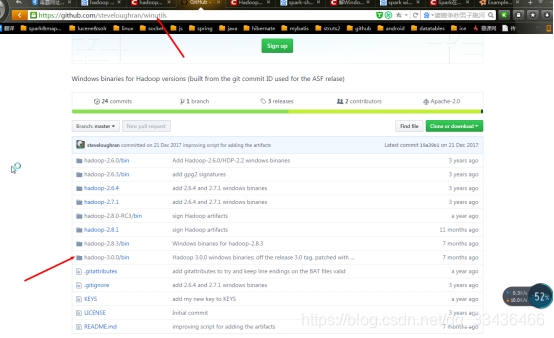
缺少winutils.exe文件,下载winutils.exe文件
https://github.com/steveloughran/winutils
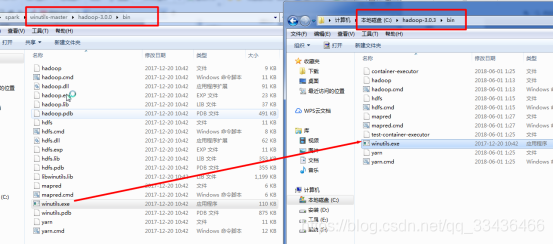
复制winutils.exe文件到hadoop的bin目录下
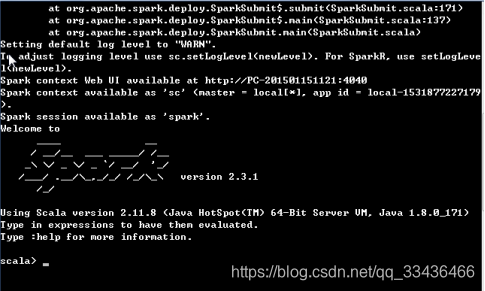
再次运行spark-shell

Spark运行模式:
local
standalone
yarn
mesos
Spark运行流程:
Spark的Application在运行时,首先在driver程序中创建sparkcontext,将其作为调度的总入口,在其初始化过程中会分别创建DAGSchedular(进行Stage调度)和TaskSchedular(进行Task调度)两个模块。DAGSchedular时基于Stage的调度模块,它为每个Spark Job计算具有依赖关系的多个Stage任务阶段,然后将每个Stage划分为具体的一组任务以TaskSet的形式提交给底层的TaskScheduler来具体执行。TaskScheduler负责具体启动任务。
Spark内核核心术语解析:
- Application:创建SparkContext实例对象的Spark用户,也包含Driver程序。
- RDD:Spark的基本计算单元,是已被分区、被序列化的、不可变的、有容错机制的、并且能够被并行操作的数据集合。
- Job:和Spark的action相对应,每一个action都会对应一个Job实例,该Job实例包含多任务的并行计算。一个Job包含n个transformation和1个action。
- Driver Program:运行main函数并新建SparkContext实例的程序。
- 共享变量:在Spark Application运行时可能需要共享一些变量提供给Task或Driver使用。Spark提供了2种:一种是可以缓存到各个节点的广播变量,另一种是只支持加法操作,可以实现求和的累加变量。
- DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给Taskscheduler。其划分Stage的依据是RDD间的依赖关系。
- TaskScheduler:将TaskSet提交给Worker运行,每一个Executor运行什么Task就是在此分配的。
- Cluster Manager:集群资源管理的外部服务,在Spark上主要有Srandalone和Yarn和Mesos三种集群资源管理器
- Worker Node:集群中可以运行Application代码的工作节点,相当于Hadoop的slave节点。
- Executor:在一个Worker Node上为应用启动的工作进程,在进程中负责任务的运行,并且负责将数据存放在内存或磁盘上。每个应用在Worker Node上只会有一个Executor,在Executor内部通过多线程的方式并发处理应用的任务。
- Task:被Driver送到Executor上的工作单元,它是运行Application的基本单位。通常情况下一个Task会处理一个Split的数据,每一个Split一般就是一个Block快的大小。
- Stage:一个Job在执行前会被系统拆分成一组或多组任务,每一组任务称为Stage。
- Persist/Cache:通过rdd的persist方法可以将rdd的分区数据持久化在内存或硬盘中,通过cache方法会缓存到内存中。
- Checkpoint:调用rdd的checkpoint方法可以将rdd保存到外部存储中,如硬盘会hdfs。Spark引入checkpoint机制是因为持久化的rdd数据有可能丢失或被替换,checkpoint可以在这个时候发挥作用,避免重新计算。创建checkpoint是在当前job完成后由另外一个专门的job完成:也就是说需要checkpoint的rdd会被重新计算两次。因此在使用rdd.checkpoint()的时候建议加上rdd.cache(),这样第二次运行的job就不用再去计算该rdd了。
- Shuffle:有一部分transformation或action会让rdd产生宽依赖,这个过程就像是将父rdd中所有分区的record进行了shuffle洗牌,数据被打散重组,例如属于transformation操作的join以及属于action操作的reduce等都会产生shuffle。
- Cluster Manager:在集群上获取资源的外部服务,目前有三种类型:
- Standalone:Spark原生的资源管理器,由Master负责资源的分配。
- Apache Mesos:与Hadoop MapReduce兼容性良好的一种资源调度框架。
- Hadoop Yarn:主要是指Yarn中的ResourceManager。
Spark快速原因:
- 统一的RDD抽象和操作
- 基于内存的迭代式计算
- DAG
- 出色的容错机制
RDD:弹性分布式数据集Resilient Distributed Dataset。在Spark中一个RDD就是一个分布式对象集合。
创建RDD的三种方式:加载外部数据集
在驱动程序中平行化集合
通过一个RDD创建新的RDD
RDD两种类型的操作:
- 转换Transformation(将原来的RDD构建成新的RDD,(惰性,lineage血统))
- 动作Action(通过RDD来计算结果,并将结果返回给驱动程序或保存到外部存储系统(如hdfs))
注意:Spark的RDD在默认情况下每次运行它们都要重新进行计算,如果需要重用在多个动作中,可以使用它的持久化方法RDD.persist(),计算它的第一次后,Spark将RDD内容存储在内存中。
惰性:转换RDD的方式是惰性的,只有在动作中使用他们,才会通过lineage去计算它们
lineage:RDD转换成新的RDD时,Spark跟踪记录且设定不同的RDD之间的依赖关系,这种关系就是血统图。它使用这个信息来按照需求计算每个RDD以及恢复持续化的RDD丢失的那一部分数据。注意:每次我们调用一个新的动作,整个RDD必须从头开始计算,为了提高效率,用户可以将这些中间结果持久化。
Spark Streaming实时流处理框架
计算流程:Spark Streaming是将流式计算分解成一系列短小的批处理作业,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(DStream),每一段数据都转成RDD,然后将Spark Streaming中队DStream的Transformation操作变为Spark中对RDD的Transformation操作。
一个RDD可以有多个分区,每个分区就是一个dataset片段。
窄依赖Narrow Dependency:父RDD的每个分区最多只能被一子RDD的一个分区使用
宽依赖Wide Dependency:父RDD的每个分区可以被被子RDD的多个分区使用。
在eclipse上以本地模式进行Spark API实战
// 遍历一个RDD中的内容创建一个新的RDD
private static void map() {
// 本地模式运行spark
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
// 使用java7的try-with-resources可以用于用于自动关闭javasparkcontext
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
// 创建RDD的方式一:加载外部数据集
// JavaRDD<String> javaRDD = sc.textFile("src/com/wf/main/map.txt");
// 创建RDD的方式二:平行化对象
JavaRDD<String> javaRDD = sc.parallelize(Arrays.asList(new String[] { "1", "2", "22", "2" }));
// Function<String, Integer>:String对应javaRDD中数据类型, Integer为用户想要得到的类型
JavaRDD<Integer> map = javaRDD.map(new Function<String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(String arg0) throws Exception {
return Integer.parseInt(arg0) + 1;
}
});
// 打印map结果为:2->3->23->3->
map.foreach(new VoidFunction<Integer>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Integer arg0) throws Exception {
System.out.print(arg0 + "->");
}
});
}
}
//将一个RDD中的内容规约成一个结果:比如计算他们的和
private static void reduce() {
SparkConf conf = new SparkConf().setMaster("local").setAppName("reduce");
// 使用java7的try-with-resources用于自动关闭javasparkcontext
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5));
// Function2<Integer, Integer, Integer> Integer为javaRDD的数据类型
Integer reduce = javaRDD.reduce(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer arg0, Integer arg1) throws Exception {
return arg0 + arg1;
}
});
System.out.println(reduce);
}
}
// 对RDD中的数据执行过滤操作,返回true则保留,返回false则去掉,得到一个新的RDD
private static void filter() {
SparkConf conf = new SparkConf().setAppName("filter").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 3, 2, 1, 4), 2);
JavaRDD<Integer> filterRDD = javaRDD.filter(new Function<Integer, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Integer arg0) throws Exception {
return arg0 % 2 == 0;
}
});
filterRDD.collect().forEach(new Consumer<Integer>() {
@Override
public void accept(Integer t) {
System.out.println(t);
}
});
}
}
//将RDD分组后统计其数量,返回一个map
private static void countByValue() {
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 3, 2, 1, 4));
Map<Integer, Long> countByValue = javaRDD.countByValue();
/**
* 5 - 1
* 1 - 2
* 2 - 1
* 3 - 1
* 4 - 1
*
*/
for (Map.Entry<Integer, Long> entry : countByValue.entrySet()) {
System.out.println(entry.getKey() + " - " + entry.getValue());
}
}
}
// 相比于map,它对每行数据操作后都会生成多行数据,而map只会生成一行
private static void flatMap() {
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 3, 2, 1, 4), 2);
JavaRDD<String> flatMapRDD = javaRDD.flatMap(new FlatMapFunction<Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(Integer arg0) throws Exception {
List<String> list = new ArrayList<String>();
list.add(arg0 + 1 + " abc");
return list.iterator();
}
});
//[6 abc, 2 abc, 4 abc, 3 abc, 2 abc, 5 abc]
System.out.println(flatMapRDD.collect());
sc.close();
}
private static void flatMapToDouble() {
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 3, 2, 1, 4), 2);
JavaDoubleRDD flatMapToDoubleRDD = javaRDD.flatMapToDouble(new DoubleFlatMapFunction<Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<Double> call(Integer arg0) throws Exception {
Set<Double> set = new HashSet<Double>();
set.add(Double.parseDouble(String.valueOf(arg0 + 5)));
return set.iterator();
}
});
//[10.0, 6.0, 8.0, 7.0, 6.0, 9.0]
System.out.println(flatMapToDoubleRDD.collect());
sc.close();
}
private static void groupBy() {
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 3, 2, 1, 4), 2);
JavaPairRDD<String, Iterable<Integer>> groupByPairRDD = javaRDD.groupBy(new Function<Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public String call(Integer arg0) throws Exception {
return arg0 + 1 + "";
}
});
List<Tuple2<String, Iterable<Integer>>> collect = groupByPairRDD.collect();
/*
* 4 : 3
* 6 : 5
* 2 : 1 1
* 5 : 4
* 3 : 2
*/
for (Tuple2<String, Iterable<Integer>> tuple2 : collect) {
System.out.print(tuple2._1 + " : ");
Iterable<Integer> iterable = tuple2._2;
for (Integer integer : iterable) {
System.out.print(integer + " ");
}
System.out.println();
}
sc.close();
}
private static void flatMapToPair() {
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 3, 2, 1, 4), 2);
JavaPairRDD<Float, String> flatMapToPairRDD = javaRDD.flatMapToPair(new PairFlatMapFunction<Integer, Float, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<Tuple2<Float, String>> call(Integer arg0) throws Exception {
Set<Tuple2<Float, String>> set = new HashSet<Tuple2<Float, String>>();
Tuple2<Float, String> tuple2 = new Tuple2<Float, String>(Float.parseFloat(arg0 + 1 + ""), arg0 + 2 + "");
set.add(tuple2);
return set.iterator();
}
});
/*
* 6.0 7
* 2.0 3
* 4.0 5
* 3.0 4
* 2.0 3
* 5.0 6
*/
flatMapToPairRDD.collect().forEach(new Consumer<Tuple2<Float, String>>() {
@Override
public void accept(Tuple2<Float, String> t) {
System.out.println(t._1 + " " + t._2);
}
});
sc.close();
}
//两个RDD的交集产生一个新的RDD
private static void intersection() {
System.out.println("intersection:");
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> javaRDD1 = sc.parallelize(Arrays.asList(5, 1, 3, 5, 1, 4), 2);
JavaRDD<Integer> javaRDD2 = sc.parallelize(Arrays.asList(5, 2, 3, 1, 5, 5, 6), 4);
JavaRDD<Integer> intersectionRDD = javaRDD1.intersection(javaRDD2); // 交集
//[1, 5, 3]
System.out.println(intersectionRDD.collect());
sc.close();
}
//一个RDD去重后产生一个新的RDD
private static void distinct() {
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 3, 5, 1, 4), 2);
JavaRDD<Integer> distinct = javaRDD.distinct();
distinct.foreach(new VoidFunction<Integer>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Integer arg0) throws Exception {
System.out.print(arg0 + " ");
}
});
sc.close();
}
private static void takeOrdered() {
SparkConf conf = new SparkConf().setAppName("takeOrdered").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 3, 5, 1, 4), 2);
//takeOrdered 参数1:取出前几个数, 参数2:排序规则
List<Integer> takeOrderedList = javaRDD.takeOrdered(2, new TakeOrderedComparator());
takeOrderedList.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer t) {
System.out.print(t + " ");
}
});
sc.close();
}
private static class TakeOrderedComparator implements Comparator<Integer>,
Serializable {
private static final long serialVersionUID = 1L;
@Override
public int compare(Integer o1, Integer o2) {
return o1.compareTo(o2);
}
}
private static void sortBy() {
SparkConf conf = new SparkConf().setAppName("sortBy").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 1, 4, 4, 2, 2), 3);
final Random r = new Random(100);
JavaRDD<String> mapRDD = javaRDD.map(new Function<Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public String call(Integer arg0) throws Exception {
return arg0.toString() + "_" + r.nextInt(100);
}
});
//sortBy 参数一:定义按照什么排序 参数二: ascending排序方式,默认true升序 参数三: numPartitions分区个数,默认与之前保持一致
JavaRDD<String> sortByRDD = mapRDD.sortBy(new Function<String, Object>() {
private static final long serialVersionUID = 1L;
@Override
public Object call(String arg0) throws Exception {
return arg0.split("_")[1];
}
}, false, 3);
System.out.println(sortByRDD.collect());
sc.close();
}
// 将两个RDD合并,与sql中的union一致
private static void union() {
System.out.println("union:");
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 1, 4, 4, 2, 2), 3);
JavaRDD<Integer> unionRDD = javaRDD.union(javaRDD);// 将两个rdd简单合并在一起,不改变partition里的数据
System.out.println(unionRDD.collect());
sc.close();
}
private static void zipWithIndex() {
System.out.println("zipWithIndex:");
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 1, 4, 4, 2, 2), 3);
JavaPairRDD<Integer, Long> zipWithIndexPairRDD = javaRDD.zipWithIndex();
// [(5,0),(1,1),(1,2),(4,3),(4,4),(2,5),(8,6)]
System.out.println(zipWithIndexPairRDD.collect());
}
}
private static void zipWithUniqueId() {
System.out.println("zipWithUniqueId:");
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
//javaRDD的分区如下:
//分区1:5 1
//分区2:1 4
//分区3:4 2 3
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(5, 1, 1, 4, 4, 2, 2), 3);
//zipWithUniqueIdPairRDD的key就是原来RDD的内容,而value = 该分区的索引 + 分区数 * 该元素在该分区中的索引
JavaPairRDD<Integer, Long> zipWithUniqueIdPairRDD = javaRDD.zipWithUniqueId();
// [(5,0),(1,3),(1,1),(4,4),(4,2),(2,5),(2,8)]
//计算如下:
// 0 + 3 * 0 = 0
// 0 + 3 * 1 = 3
// 1 + 3 * 0 = 1
// 1 + 3 * 1 = 4
// 2 + 3 * 0 = 2
// 2 + 3 * 1 = 5
// 2 + 3 * 2 = 8
System.out.println(zipWithUniqueIdPairRDD.collect());
}
}
private static void mapToPair() {
System.out.println("mapToPair:");
SparkConf conf = new SparkConf().setAppName("mapToPair").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(1, 2, 4, 3, 5, 6, 7, 1, 2));
//PairFunction<Integer, Integer, String>
//第一个参数Integer:就是原来RDD中数据类型
//第二个参数Integer:你想要的JavaPairRDD的key类型
//第三个参数String:你想要的JavaPairRDD的value类型
JavaPairRDD<Integer, String> mapToPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, String> call(Integer arg0) throws Exception {
return new Tuple2<Integer, String>(arg0, "1");
}
});
// [(1,1), (2,1), (4,1), (3,1), (5,1), (6,1), (7,1), (1,1), (2,1)]
System.out.println(mapToPairRDD.collect());
}
}
// 对pair中的key进行group By操作
private static void groupByKey() {
System.out.println("groupByKey:");
SparkConf conf = new SparkConf().setAppName("groupByKey").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(1, 2, 4, 1, 3, 6, 3));
JavaPairRDD<Integer, Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Integer, Integer> call(Integer a)
throws Exception {
return new Tuple2<Integer, Integer>(a, 1);
}
});
int numPartitions = 2;
JavaPairRDD<Integer, Iterable<Integer>> groupByKeyRDD = javaPairRDD.groupByKey(numPartitions);
// [(4,[1]), (6,[1]), (2,[1]), (1,[1, 1]), (3,[1, 1])]
System.out.println(groupByKeyRDD.collect());
// 自定义partitioner
JavaPairRDD<Integer, Iterable<Integer>> groupByKeyRDD2 = javaPairRDD.groupByKey(new Partitioner() {
private static final long serialVersionUID = 1L;
// partition个数
@Override
public int numPartitions() {
return 10;
}
// partition方式
@Override
public int getPartition(Object o) {
return o.toString().hashCode() % numPartitions();
}
});
//[(2,[1]), (3,[1, 1]), (4,[1]), (6,[1]), (1,[1, 1])]
System.out.println(groupByKeyRDD2.collect());
}
}
private static void coalesce() {// 合并
System.out.println("coalesce:");
SparkConf conf = new SparkConf().setAppName("coalesce").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(1, 2, 4, 3, 5, 6, 7));
int numPartitions = 2;
JavaRDD<Integer> coalesceRDD = javaRDD.coalesce(numPartitions); // shuffle默认为false
System.out.println(coalesceRDD.collect());// [1, 2, 4, 3, 5, 6, 7]
JavaRDD<Integer> coalesceRDD2 = javaRDD.coalesce(numPartitions, true);
System.out.println(coalesceRDD2.collect());// [1, 4, 5, 7, 2, 3, 6]
}
}
private static void repartition() {// 重新分区
SparkConf conf = new SparkConf().setAppName("repartition").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<Integer> javaRDD = sc.parallelize(Arrays.asList(1, 2, 4, 3, 5, 6, 7));
// 等价coalesce(numPartitions,shuffle=true)
int numPartitions = 2;
JavaRDD<Integer> coalesceRDD = javaRDD.repartition(numPartitions); // shuffle默认为false
System.out.println(coalesceRDD.collect());// [1, 2, 4, 3, 5, 6, 7]
}
}
private static void mapPartitionsWithIndex() {
SparkConf conf = new SparkConf().setAppName("mapPartitionsWithIndex").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<String> javaRDD = sc.parallelize(Arrays.asList("5", "1", "1", "3", "6", "2", "2"), 3);
boolean preservesPartitioning = false;
JavaRDD<String> mapPartitionsWithIndexRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(Integer v1, Iterator<String> v2) throws Exception {
//v1为分区索引 v2为该分区中数据集合
LinkedList<String> linkedList = new LinkedList<String>();
while (v2.hasNext()) {
linkedList.add(v1 + "=" + v2.next());
}
return linkedList.iterator();
}
}, preservesPartitioning);
// [0=5, 0=1, 1=1, 1=3, 2=6, 2=2, 2=2]
System.out.println(mapPartitionsWithIndexRDD.collect());
}
}
private static void countByKey() {
System.out.println("countByKey:");
SparkConf conf = new SparkConf().setAppName("countByKey").setMaster("local");
try (JavaSparkContext sc = new JavaSparkContext(conf)) {
JavaRDD<String> javaRDD = sc.parallelize(Arrays.asList("5", "1", "1", "3", "6", "2", "2"), 5);
boolean preservesPartitioning = false;
JavaRDD<String> mapPartitionsWithIndexRDD = javaRDD.mapPartitionsWithIndex(new Function2<Integer, Iterator<String>, Iterator<String>>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(Integer v1, Iterator<String> v2) throws Exception {
//v1为分区索引 v2为该分区中数据集合
LinkedList<String> linkedList = new LinkedList<String>();
while (v2.hasNext()) {
linkedList.add(v1 + "=" + v2.next());
}
return linkedList.iterator();
}
}, preservesPartitioning);
// [0=5, 1=1, 2=1, 2=3, 3=6, 4=2, 4=2]
System.out.println(mapPartitionsWithIndexRDD.collect());
JavaPairRDD<String, String> mapToPairRDD = javaRDD.mapToPair(new PairFunction<String, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String s) throws Exception {
return new Tuple2<String, String>(s, s);
}
});
// [(5,5), (1,1), (1,1),(3,3), (6,6), (2,2), (2,2)]
System.out.println(mapToPairRDD.collect());
// {5=1, 6=1, 1=2, 2=2, 3=1}
System.out.println(mapToPairRDD.countByKey());
}
}
// 对pair中的value部分执行函数里面的操作
private static void mapValues() {
System.out.println("mapValues:");
try (JavaSparkContext sc = new JavaSparkContext("local", "mapValues")) {
List<Tuple2<Integer, String>> list = new ArrayList<Tuple2<Integer, String>>();
list.add(new Tuple2<Integer, String>(1, "once"));
list.add(new Tuple2<Integer, String>(3, "third"));
list.add(new Tuple2<Integer, String>(2, "twice"));
JavaPairRDD<Integer, String> rdd = sc.parallelizePairs(list);
JavaPairRDD<Integer, Object> mapValuesPairRDD = rdd.mapValues(new Function<String, Object>() {
private static final long serialVersionUID = 1L;
@Override
public Object call(String arg0) throws Exception {
return arg0 + "..V";
}
});
// [(1,once..V), (3,third..V), (2,twice..V)]
System.out.println(mapValuesPairRDD.collect());
}
}
// 与sql中join一致,将两个RDD中key一致的进行join连接操作
private static void join() {
System.out.println("join:");
try (JavaSparkContext sc = new JavaSparkContext("local", "join")) {
List<Tuple2<String, String>> list1 = new ArrayList<Tuple2<String, String>>();
list1.add(new Tuple2<String, String>("a", "11"));
list1.add(new Tuple2<String, String>("b", "22"));
list1.add(new Tuple2<String, String>("a", "13"));
list1.add(new Tuple2<String, String>("c", "4"));
JavaPairRDD<String, String> rdd1 = sc.parallelizePairs(list1);
List<Tuple2<String, Object>> list2 = new ArrayList<Tuple2<String, Object>>();
list2.add(new Tuple2<String, Object>("a", "11"));
list2.add(new Tuple2<String, Object>("b", "22"));
list2.add(new Tuple2<String, Object>("a", "13"));
list2.add(new Tuple2<String, Object>("c", "4"));
JavaPairRDD<String, Object> rdd2 = sc.parallelizePairs(list2);
JavaPairRDD<String, Tuple2<String, Object>> joinPairRDD = rdd1.join(rdd2);
// [(a,(11,11)), (a,(11,13)), (a,(13,11)), (a,(13,13)), (b,(22,22)), (c,(4,4))]
System.out.println(joinPairRDD.collect());
}
}
// 对两个RDD按key进行groupBy,并对每个RDD的value进行单独groupBy
private static void cogroup() {
try (JavaSparkContext sc = new JavaSparkContext("local", "cogroup")) {
List<Tuple2<String, String>> list1 = new ArrayList<Tuple2<String, String>>();
list1.add(new Tuple2<String, String>("a", "11"));
list1.add(new Tuple2<String, String>("b", "22"));
list1.add(new Tuple2<String, String>("a", "13"));
list1.add(new Tuple2<String, String>("d", "4"));
JavaPairRDD<String, String> rdd1 = sc.parallelizePairs(list1);
List<Tuple2<String, Object>> list2 = new ArrayList<Tuple2<String, Object>>();
list2.add(new Tuple2<String, Object>("a", "11"));
list2.add(new Tuple2<String, Object>("b", "22"));
list2.add(new Tuple2<String, Object>("a", "13"));
list2.add(new Tuple2<String, Object>("c", "4"));
list2.add(new Tuple2<String, Object>("e", "4"));
JavaPairRDD<String, Object> rdd2 = sc.parallelizePairs(list2);
JavaPairRDD<String, Tuple2<Iterable<String>, Iterable<Object>>> cogroupPairRDD = rdd1.cogroup((rdd2));
// [(d,([4],[])), (e,([],[4])), (a,([11, 13],[11, 13])), (b,([22],[22])), (c,([],[4]))]
System.out.println(cogroupPairRDD.collect());
}
}
// 对pair中的key先进行group By操作,然后根据函数对聚合数据后的数据操作
private static void reduceByKey() {
System.out.println("cogroup:");
try (JavaSparkContext sc = new JavaSparkContext("local", "cogroup")) {
List<Tuple2<String, String>> list = new ArrayList<Tuple2<String, String>>();
list.add(new Tuple2<String, String>("a", "11"));
list.add(new Tuple2<String, String>("b", "22"));
list.add(new Tuple2<String, String>("a", "13"));
list.add(new Tuple2<String, String>("d", "4"));
JavaPairRDD<String, String> rdd = sc.parallelizePairs(list);
JavaPairRDD<String, String> reduceByKeyPairRDD = rdd.reduceByKey(new Function2<String, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public String call(String arg0, String arg1) throws Exception {
return arg0 + "|" + arg1;
}
});
// [(d,4), (a,11|13), (b,22)]
System.out.println(reduceByKeyPairRDD.collect());
}
}
private static void accumulator() {
System.out.println("accumulator:");
try (JavaSparkContext sc = new JavaSparkContext("local", "accumulator")) {
JavaRDD<String> rdd = sc.parallelize(Arrays.asList("5", "1", "1", "3", "6", "2", "2"), 5);
Accumulator<Integer> blankLines = sc.accumulator(1);
JavaRDD<String> flatMap = rdd.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(String line)
throws Exception {
if (line.equals("")) {
blankLines.add(1);
}
return Arrays.asList(line.split(" ")).iterator();
}
});
System.out.println(flatMap.collect());
System.out.println(blankLines.value());
}
}














 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









