







Redis是一个基于内存的数据库,所有的数据都存储在内存中,所以如何优化存储,减少内存空间占用对成本控制来说是非常重要的。精简键名和键值是最直观的减少内存占用的方式,而Redis则是通过内部编码规则来节省更多的内存空间。
Redis为每种数据类型都提供了两三种内部编码方式,以散列类型为例,散列类型是通过散列表实现的,这样就可以实现0(1)时间复杂度的查找、赋值操作,然而当键中元素很少的时候,0(1)的操作并不会比0(n)有明显的性能提高,所以这种情况下Redis会采用一种更为紧凑但性能稍差(获取元素的时间复杂度为0(n))的内部编码方式。内部编码方式的选择对于开发者来说是透明的,Redis会根据实际情况自动调整。当键中元素变多时Redis会自动将该键的内部编码方式转换成散列表。
一、Redis DB数据结构
Redis中是有16个redisDB库,默认是使用第一个。我们先来看下redisDB的数据结构: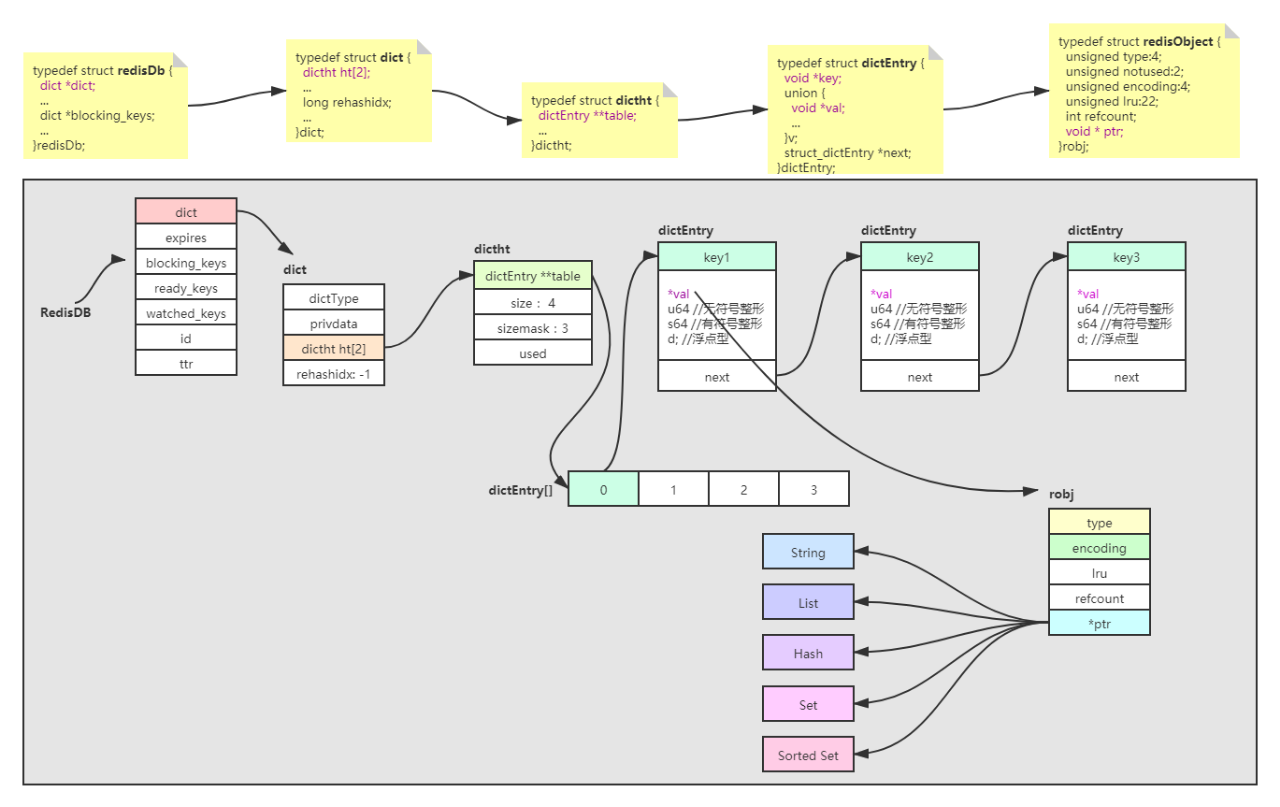
- dict:字典
- dictht:就是一个hashtable,以o(1)时间复杂度获取size,used当前数组里面用掉了多少空间
- dictEntry:数组里面的元素,**table指针指向数组,redis中所有的key都是存在dictEntry中
- *var:存储key的值,也是一个指针,指向redisObject结构进行数据存储,这个指针指向真实的数据存储
- next:当key发生hash冲突时(比如都是数组0),通过next指针建立一个单向的链表解决hash冲突
robj字段介绍:
- type:对外的数据类型,string,list,hash,set,zset等
- encoding:内部编码,raw,int,ziplist等,对内存利用率极致追求
- LRU_BITS:内存淘汰策略
- refcount:redis内存管理需要
- *ptr:指向真实的数据存储结构,ziplist等,最终指向数据编码的对象
二、内部编码方式
下面是Redis数据结构与内部编码的关系: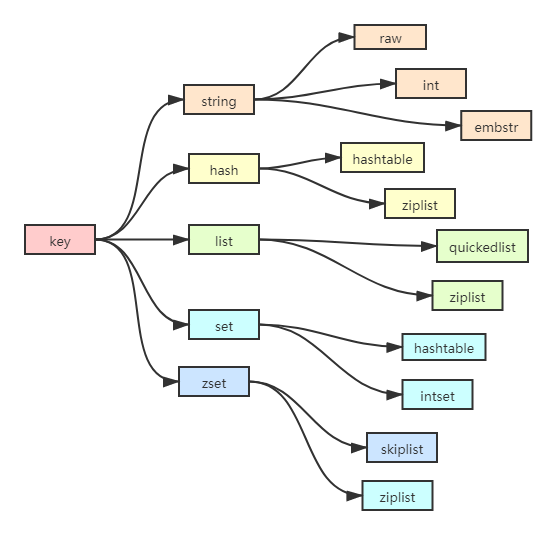
查看一个键的内部编码方式:
127.0.0.1:6379> set foo bar
OK
127.0.0.1:6379> object encoding foo
"raw"Redis的每个键值都是使用一个redisObject结构体保存的,在redis.h中声明的redisObj定义的如下:
typedef struct redisObject {
unsigned type:4; /** 4 bit */
unsigned encoding:4; /** 4 bit */
unsigned lru:LRU_BITS; /** 24 bit */
int refcount; /** 4 byte */
void * ptr; /** 8 byte */
}robj;其中type字段表示的是键值的数据类型,取值可以是如下内容:
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4encoding字段表示的就是Redis键值的内部编码方式,取值可以是:
#define REDIS_ENCODING_RAW 0 /** Raw representation */
#define REDIS_ENCODING_INT 1 /** ed as integer */
#define REDIS_ENCODING_EMBSTR 2 /** cpu cache line */
#define REDIS_ENCODING_HT 3 /** Encoded as hash table */
#define REDIS_ENCODING_ZIPMAP 4 /** Encoded as zipmap */
#define REDIS_ENCODING_QUICKEDLIST 5 /** Encoded as regular quicked list */
#define REDIS_ENCODING_ZIPLIST 6 /** Encoded as ziplist */
#define REDIS_ENCODING_INTSET 7 /** Encoded as intset */
#define REDIS_ENCODING_SKIPLIST 8 /** Encoded as skiplist */各个数据类型可能采用的内部编码方式以及相应的OBJECT ENCODING命令执行结果如下:
下面针对每种数据类型分别介绍其内部编码规则及优化方式。
二、字符串类型优化方式
127.0.0.1:6379> set a_string a
OK
127.0.0.1:6379> set a_int 1
OK
127.0.0.1:6379> set a_long_string aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
OK
127.0.0.1:6379> type a_string
string
127.0.0.1:6379> type a_int
string
127.0.0.1:6379> type a_long_string
string
127.0.0.1:6379> object encoding a_string
"embstr"
127.0.0.1:6379> object encoding a_int
"int"
127.0.0.1:6379> object encoding a_long_string
"raw"
127.0.0.1:6379>Redis使用一个sdshdr类型的变量来存储字符串,而redisObject的ptr字段指向的是该变量的地址。sdshdr的定义如下:
// redis3.2之前版本
struct sdshdr {
int len; /* 表示的是字符串的长度 */
int free; /* 表示buf中的剩余空间 */
char buf[]; /* 字符串的内容 */
};
// redis3.2之后版本
typedef char *sds;
struct sdshdr5 {
unsigned char flags; /*3 lsb of type, and 5 msb of string length*/
char buf[];
};
struct sdshdr8 {
uint8_t_len; /*used*/
uint8_t_alloc; /*excluding the header and null terminator*/
unsigned char flags; /*3 lsb of type, 5 unused bits */
char buf[];
};
struct sdshdr16 {
uint16_t_len; /*used*/
uint16_t_alloc; /*excluding the header and null terminator*/
unsigned char flags; /*3 lsb of type, 5 unused bits */
char buf[];
};
struct sdshdr32 {
...
};
struct sdshdr64 {
...
};redis根据字符串大小选择合适的数据存储结构:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
static inline char sdsReqType(size_t_string_size) {
if (string_size < 32)
return SDS_TYPE_5;
if (string_size < 0xff) // 2^8 - 1
return SDS_TYPE_8;
if (string_size < 0xffff) // 2^16 - 1
return SDS_TYPE_16;
if (string_size < 0xffffffff) // 2^32 - 1
return SDS_TYPE_32;
return SDS_TYPE_64;
}3.2之前:
- 可以动态扩容的数据结构
- free代表可用空间,分配空间可以分配稍微大一点的空间,下次进行数据修改的时候就不用每次都分配内存,提升整体性能
3.2之后: - 变得丰富多样
- 节省存储空间,比如就存一个字符串【i】,使用sdshdr数据结构需要len+free=4+4=8字节
- sdshdr5只会使用一个字节flags,表示数据特性。如下:
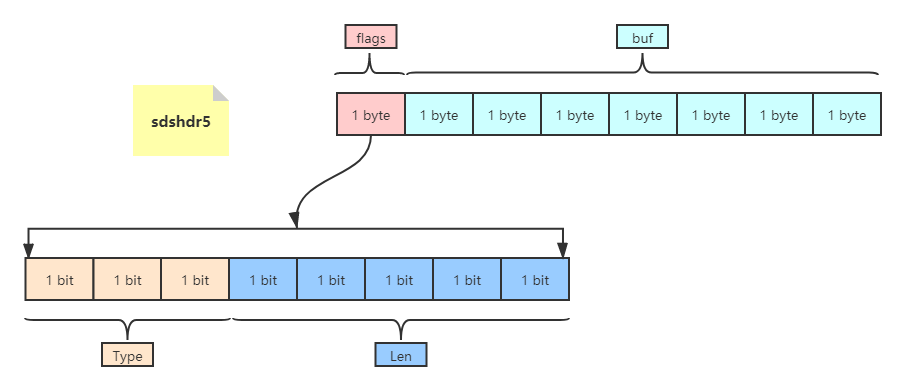
- flags+buf,一个flags字节的低3位表示类型type,len表示数据长度(2^5-1 < 32)
- buf表示真实数据
缺点是无法动态扩容,没有free字段,所以redis也没有使用sdshdr5这种数据结构,never used,所以通常情况下,使用下面sdshdr8: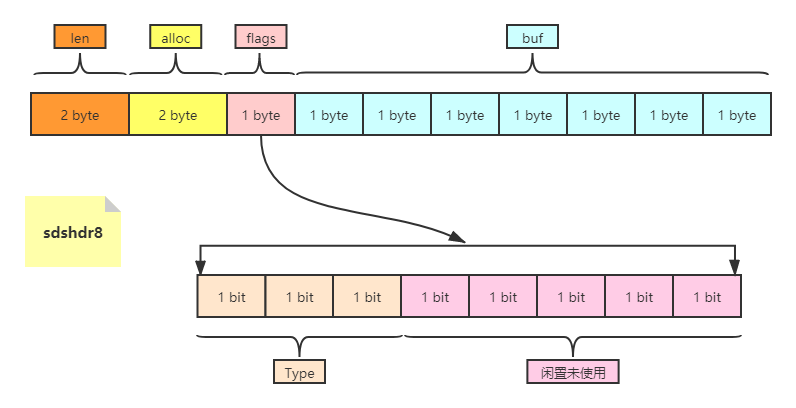
- type定义的0,1,2表示type占用的bit位,可以减少空间占用
接下来我们分别介绍下string类型的raw、int和embstr。
embstr
比如当执行SET key foobar时,在64位linux系统下,存储键值需要占用的空间是 sizeof(redisObject)+sizeof(sdshdr8)+strlen("foobar")=16字节+4字节+6字节=26字节。存储结构如下: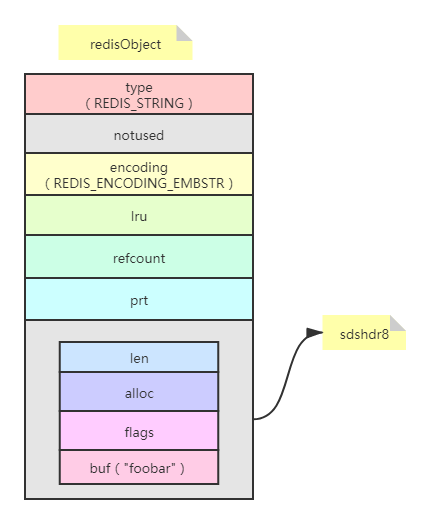
在linux操作系统,cpu缓存行大小占64byte,而redisObject和sdshdr8正好占用20个字节,所以当业务数据大小在64-20=44字节之内的话,可以利用cpu缓存行特性:linux分配内存的时候,就会挨着redisObject进行分配,开辟一块连续的空间存储,利用cpu的缓存行一次读取到数据,减少内存IO,这样数据整合就在cpu缓存行范围内,这样在进行数据读取的时候,cpu第一次寻址到var,通过var找到redisObject,通过redisObject我们可以直接拿到值,而不用通过指针再一次寻址去拿数据,这就是embstr做的事情。
raw类型是和redisObject不在一块连续的内存空间,如下:
我们可以对embstr进行验证:
127.0.0.1:6379> set a_string_short aaaaaaaaaa-aaaaaaaaaa-aaaaaaaaaa-aaaaaaaaaa-
OK
127.0.0.1:6379> STRLEN a_string_short
(integer) 44
127.0.0.1:6379> object encoding a_string_short
"embstr"
127.0.0.1:6379> set b_string_short aaaaaaaaaa-aaaaaaaaaa-aaaaaaaaaa-aaaaaaaaaa-a
OK
127.0.0.1:6379> STRLEN b_string_short
(integer) 45
127.0.0.1:6379> object encoding b_string_short
"raw"
127.0.0.1:6379> - 当字符串长度大于44时就变成了raw
使用append追加字符串方式说明:
127.0.0.1:6379> set a a
OK
127.0.0.1:6379> object encoding a
"embstr"
127.0.0.1:6379> APPEND a b
(integer) 2
127.0.0.1:6379> object encoding a
"raw"
127.0.0.1:6379> - 使用append等命令会修改redis内部编码,就不适用cpu缓存行优化的方式了
int
当键值内容可以用一个64位有符号整数表示时,Redis会将键值转换成long类型来存储。如SET key 123456,实际占用的空间是sizeof(redisObject)=16字节,比存储"foobar"节省了 一半的存储空间,如下所示: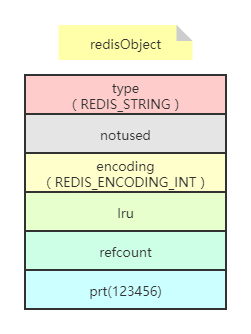
redisObject中的refcount字段存储的是该键值被引用数量,即一个键值可以被多个键引用。Redis启动后会预先建立10000个分别存储从0到9999这些数字的redisObject类型变量作为共享 对象,如果要设置的字符串键值在这10000个数字内(如SET key1 123)则可以直接引用共享对象而不用再建立一个redisObject了,也就是说存储键值占用的空间是0字节,如下所示:
由此可见,使用字符串类型键存储对象ID这种小数字是非常节省存储空间的,Redis只需存储键名和一个对共享对象的引用即可。 虽然整形底层存储encoding是int类型,但是在获取长度计算时会转换为字符串计算长度。
注意:当通过配置文件参数maxmemory设置了Redis可用的最大空间大小时,Redis不会使用共享对象,因为对于每一个键值都需要使用一个redisObject来记录其LRU信息。
字符串扩容的原理:
- 当字符串大小小于1M时,每次扩容一倍
- 大于1M时,每次增加1M,比如现在5M,扩容后就是6M
三、散列类型优化方式
散列类型的内部编码方式可能是REDIS_ENCODING_HT或REDIS_ENCODING_ZIPLIST。当数据量比较小或者单个元素比较小时,底层用ziplist存储。可以在配置文件中可以定义使用REDIS_ENCODING_ZIPLIST方式编码散列类型的时机:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64当散列类型键的字段个数少于hash-max-ziplist-entries参数值且每个字段名和字段值的长度都小于hash-max-ziplist-value参数值(单位为字节)时,Redis就会使用REDIS_ ENCODING_ZIPLIST来存储该键,否则就会使用REDIS_ENCODING_HT。转换过程是透明的,每当键值变更后Redis都会自动判断是否满足条件来完成转换。如下演示:
127.0.0.1:6379> hset user name duan age 27 f1 v1 f2 v2 f3 v3
(integer) 5
127.0.0.1:6379> HGETALL user
1) "name"
2) "duan"
3) "age"
4) "27"
5) "f1"
6) "v1"
7) "f2"
8) "v2"
9) "f3"
10) "v3"
127.0.0.1:6379> hset user f4 vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv
(integer) 1
127.0.0.1:6379> HGETALL user
1) "f3"
2) "v3"
3) "name"
4) "duan"
5) "f4"
6) "vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv"
7) "f1"
8) "v1"
9) "f2"
10) "v2"
11) "age"
12) "27"
127.0.0.1:6379> 超过64个字节变成hash,hash是无序的。
REDIS_ENCODING_HT编码即散列表,可以实现O(1)时间复杂度的赋值取值等操作,其字段和字段值都是使用redisObject存储的,所以前面讲到的字符串类型键值的优化方法同样适用于散列类型键的字段和字段值。
注意:Redis的键值对存储也是通过散列表实现的,与REDIS_ENCODING_HT编码方式类似,但键名并非使用redisObject存储,所以键名"123456"并不会比"abcdef"占用更少的空间。之所以不对键名进行优化是因为绝大多数情况下键名都不会是纯数字。
Redis支持多数据库,每个数据库中的数据都是通过结构体redisDb存储的。redisDb的定义如下:
typedef struct redisDb {
dict * dict; /** The keyspace for this DB */
dict * expires; /** Timeout of keys with a timeout set */
dict * blocking_keys; /** Keys with clients waiting for data (BLPOP) */
dict * ready_keys; /** Blocked keys that received a PUSH */
dict * watched_keys; /** WATCHED keys for MULTI/EXEC CAS */
int id;
} redisDb;- dict类型就是散列表结构
- expires存储的是数据的过期时间
当Redis启动时会根据配置文件中databases参数指定的数量创建若干个redisDb类型变量存储不同数据库中的数据。
REDIS_ENCODING_ZIPLIST编码类型是一种紧凑的编码格式,它牺牲了部分读取性能以换取极高的空间利用率,适合在元素较少时使用。该编码类型同样还在列表类型和有序集合类型中使用。REDIS_ENCODING_ZIPLIST编码结构如下所示: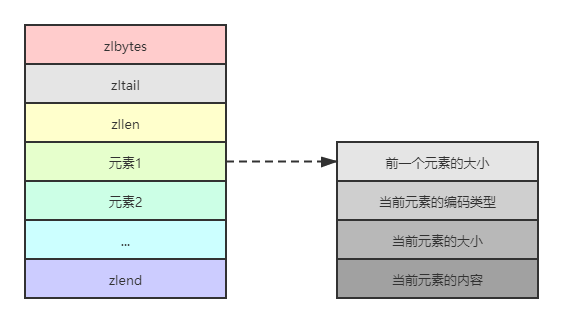
- zlbytes是uint32_t类型, 表示整个结构占用的空间
- zltail也是uint32_t类型,表示到最后一个元素的偏移,记录zltail使得程序可以直接定位到尾部元素而无需遍历整个结构,执行从尾部弹出(对列表类型而言)等操作时速度更快
- zllen是uint16_t类型,存储的是元素的数量
- zlend是一个单字节标识,标记结构的末尾,值永远是255
散列类型的ziplist数据结构如下图所示: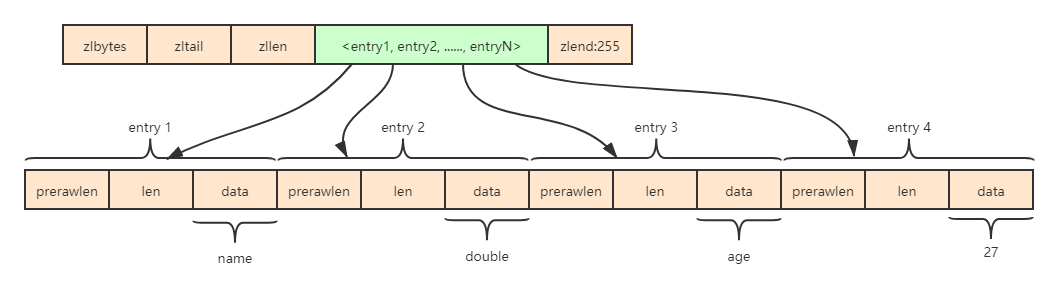
在REDIS_ENCODING_ZIPLIST中每个元素由4个部分组成:
- 第一个部分用来存储前一个元素的大小以实现倒序查找,当前一个元素的大小小于254字节时第一个部分占用1个字节,否则会占用5个字节
- 第二、三个部分分别是元素的编码类型和元素的大小,当元素的大小小于或等于63个字 节时,元素的编码类型是ZIP_STR_06B(即0<<6),同时第三个部分用6个二进制位来记录元素的长度,所以第二、三个部分总占用空间是1字节。当元素的大小大于63且小于或等于16383字节时,第二、三个部分总占用空间是2字节。当元素的大小大于16383字节时,第二、三个部 分总占用空间是5字节
- 第四个部分是元素的实际内容,如果元素可以转换成数字的话Redis会使用相应的数字类型来存储以节省空间,并用第二、三个部分来表示数字的类型(int16_t、int32_t等)
使用REDIS_ENCODING_ZIPLIST编码存储散列类型时元素的排列方式是:元素1存储字段1,元素2存储字段值2,依次类推,如下所示: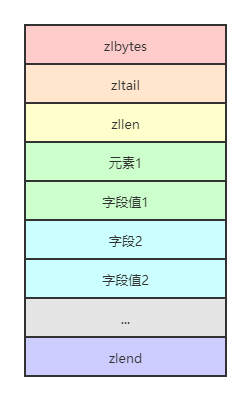
例如,当执行命令HSET hkey foo bar命令后,hkey键值的内存结构如下所示: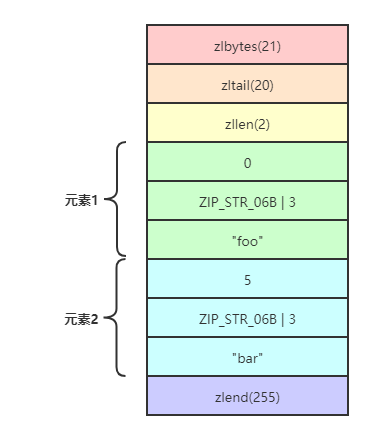
下次需要执行HSET hkey foo anothervalue时Redis需要从头开始找到值为foo的元素(查找 时每次都会跳过一个元素以保证只查找字段名),找到后删除其下一个元素,并将新值 anothervalue插入。删除和插入都需要移动后面的内存数据,而且查找操作也需要遍历才能完 成,可想而知当散列键中数据多时性能将很低,所以不宜将hash-max-ziplist-entries和hash-max- ziplist-value两个参数设置得很大。
四、列表类型优化方式
列表类型内部编码方式是REDIS_ENCODING_QUICKLIST或REDIS ENCODINGZIPLIST。
127.0.0.1:6379> lpush queue-task a b c
(integer) 3
127.0.0.1:6379> type queue-task
list
127.0.0.1:6379> object encoding queue-task
"quicklist"
127.0.0.1:6379> 同样在配置文件中可以设置每个ziplist的最大容量和quickList的数据压缩范围,提升数据存取效率。
list-max-ziplist-size -2
list-compress-depth 0- 0默认不压缩
- list不关注中间数据,1表示不压缩头尾节点,压缩中间数据
- 2表示头尾节点和头尾相邻的一个节点不压缩,压缩初次之外中间的
注意:列表类型实现阻塞队列使用的是redisDb结构中的字段blocking_keys,维护的是key与客户端的关系,不会阻塞redis进程。如下:
typedef struct redisDb {
dict *dict;
...
dict *blocking_keys;
...
}redisDbZIPLIST数据结构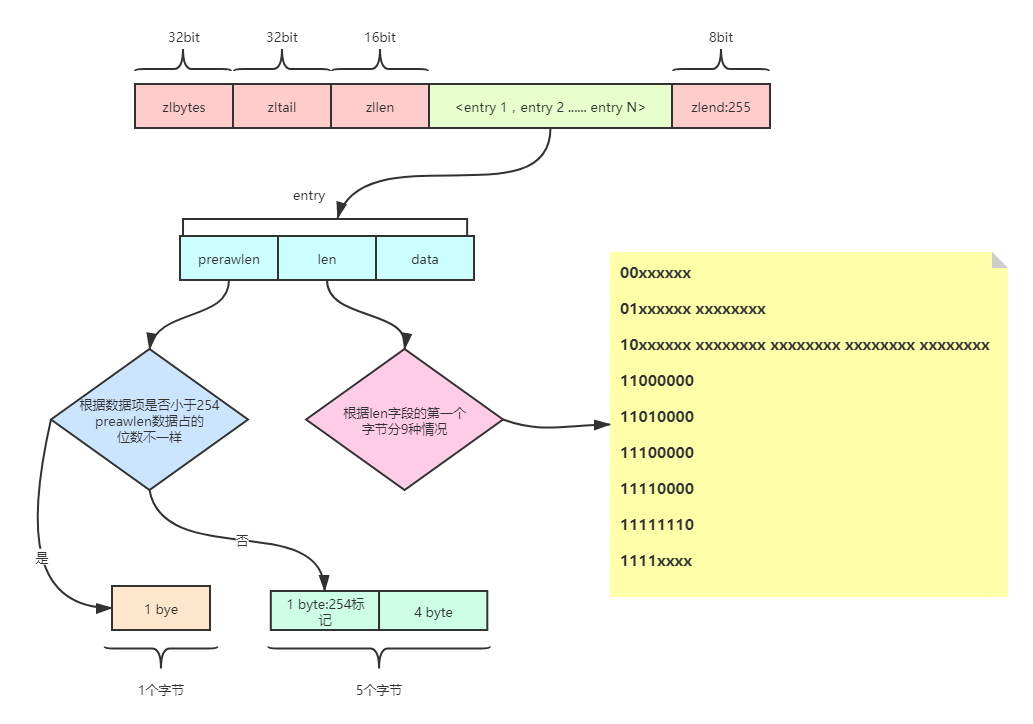
- ziplist数据结构说明:
- zlbytes:32bit表示ziplist占用的字节总数
- zltail:32bit表示ziplist表中最后一项entry在ziplist中的偏移字节数。通过zltail我们可以很方便地找到最后一项,从而可以在ziplist尾端快速地执行push或pop操作
- entry:表示真正存放数据的数据项,长度不定
- zlend:ziplist最后一个字节,是一个结束标记,值固定等于255
- prerawlen:前一个entry的数据长度
- len:entry中数据的长度
- data:真实数据存储
根据len字段的第一个字节分的9种情况: - 00xxxxxx:len字段前2个高位 bit为0,剩余的6个bit用来表示长度,即最大长度可以到2^6 - 1
- 01xxxxxx xxxxxxxx:len字段的前2个高位是01,则len字段占2个byte,共有14个bit表示,数据长度最多2^14 - 1
- 10xxxxxx xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx:len字段前2个高位bit是10,则len字段占5个byte,共有32个bit表示,数据长度最多2^32 - 1,第一个字节的剩余6个bit舍弃不用
- 11000000:len字段前2个高位bit是11,值为OXC0,则len字段占1个byte,后面的data为2字节的int16_t类型
- 11010000:len字段前4个高位bit是1101,值为OXD0,则len字段占1个byte,后面的data为4字节的int32_t类型
- 11100000:len字段前4个高位bit是1110,值为OXE0,则len字段占1个byte,后面的data为8字节的int64_t类型
- 11110000:len字段前4个高位bit是1111,值为OXF0,则len字段占1个byte,后面的data为3字节的整数
- 11111110:len字段前7个高位bit是1111111,值为OXFE,则len字段占1个byte,后面的data为1字节的整数
- 1111xxxx:len字段前4个字节是1111,后4个bit的范围是(0001-1101),这时xxxx从1到13,一共13个值,这时就用这13个值来表示data的数据,真正的数值大小为对应的bit位数值-1,代表真实的业务数据
ziplist是非常紧凑的一种数据类型,为了节省内存空间。而非常紧凑的数据结构的缺点是:
- 空间必须是连续的
- 数据量非常大的时候往里面加元素,数据迁移很麻烦
- 频繁的内存分配与释放是不划算的,所以redis针对这个问题进行了优化,quicklist
QUICKLIST数据结构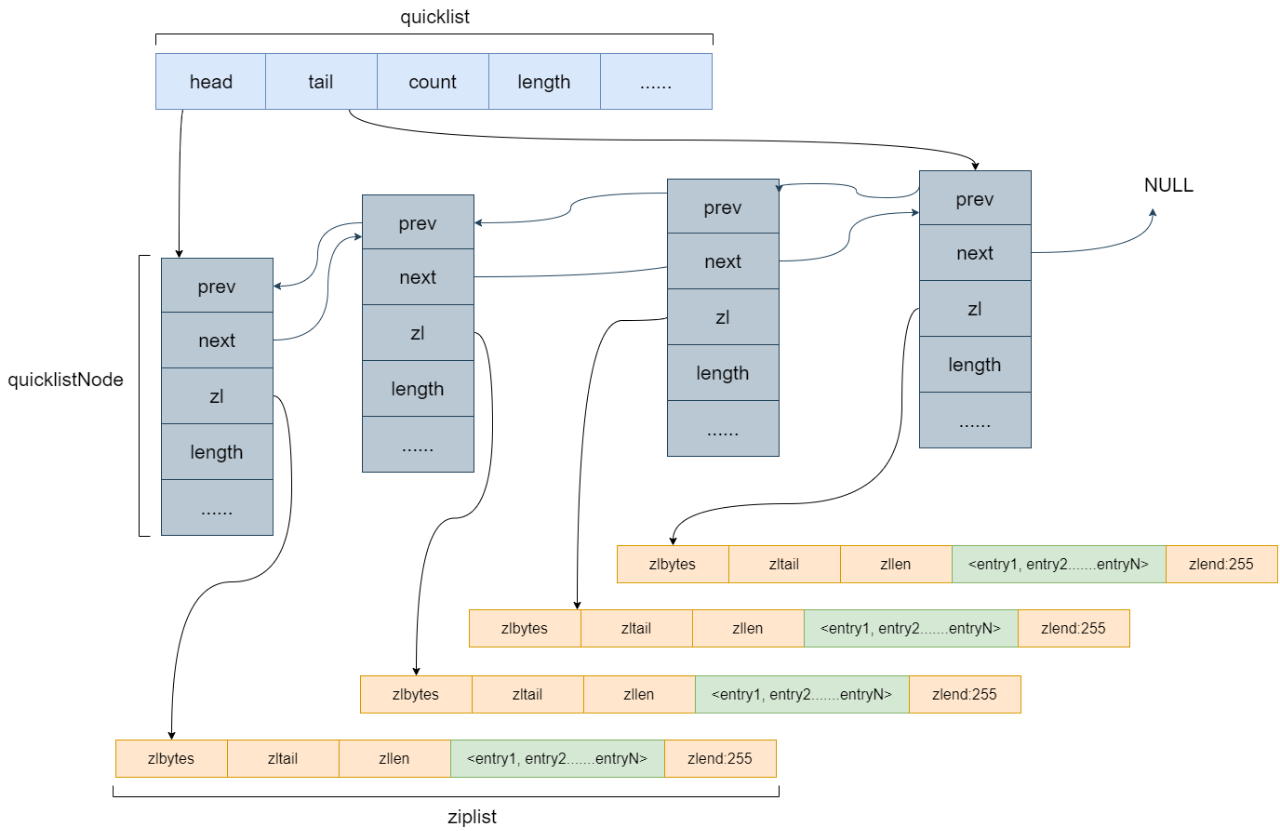
quicklist的优化是后续有数据修改,都是在一个小的ziplist中。
五、集合类型优化方式
集合类型的内部编码方式可能是REDIS_ENCODING_HT或REDIS_ENCODING_INTSET。
127.0.0.1:6379> sadd aset a b c d e f
(integer) 6
127.0.0.1:6379> sadd bset 1 2 3 4 5 6
(integer) 6
127.0.0.1:6379> object encoding aset
"hashtable"
127.0.0.1:6379> object encoding bset
"intset"
127.0.0.1:6379> sadd bset a
(integer) 1
127.0.0.1:6379> SMEMBERS bset
1) "a"
2) "5"
3) "3"
4) "1"
5) "6"
6) "4"
7) "2"
127.0.0.1:6379> 当集合中的所有元素都是整数且元素的个数小于配置文件中的set-max-intset-entries参数指定值(默认是512)时Redis会使用REDIS_ENCODING_INTSET编码存储该集合,否则会使用 REDIS_ENCODING_HT来存储。 REDIS_ENCODING_INTSET编码存储结构体intset的定义是:
typedef struct intset {
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;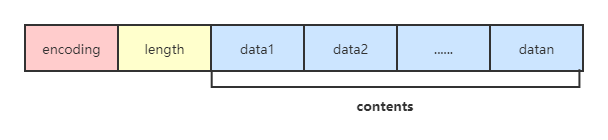
其中contents存储的就是集合中的元素值,根据encoding的不同,每个元素占用的字节大小 不同。默认的encoding是INTSET_ENC_INT16(即2个字节),当新增加的整数元素无法使用2个字节表示时,Redis会将该集合的encoding升级为INTSET_ENC_INT32(即4个字节)并调整之前所有元素的位置和长度,同样集合的encoding还可升级为INTSET_ENC_INT64(即8个字节)。 并且contents[]内存储的整数元素是顺序存储的。
REDIS_ENCODING_INTSET编码以有序的方式存储元素(所以使用SMEMBERS命令获得的结果是有序的),使得可以使用二分算法查找元素。但是无论是添加还是删除元素,Redis都需要调整后面元素的内存位置,所以当集合中的元素太多时性能较差。当新增加的元素不是整数或集合中的元素数量超过了set-max-intset-entries参数指定值时,Redis会自动将该集合的存储结构转换成REDIS_ENCODING_HT。
注意 :当集合的存储结构转換成REDIS_ENCODING_HT后,即使将集合中的所有非整数元素删除,Redis也不会自动将存储结构转換回REDIS_ENCODING_INTSET。因为如果要支持自动回转,就意味着Redis在每次删除元素时都需要遍历集合中的键来判断是否可以转換回原来的编码,这会使得删除元素变成了时间复杂度为0(n)的操作。
六、有序集合类型优化方式
有序集合类型编码方式可能是REDIS_ENCODING_SKIPLIST或REDIS_ENCODING_ZIPLIST。
当数据比较少时采用ziplist编码结构存储,同样在配置文件中可以定义使用REDIS_ENCODING_ZIPLIST方式编码的时机:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64 有序集合的ziplist数据结构如下图:

当数据大小超过128字节,使用跳表存储,单个元素大小超多64个字节也是跳表结构。有序集合的跳表结构如下图:
- *forward:前进指针
- span:跨越元素,比如rank操作就是通过span跨越元素来计算的
- 头结点不存储数据,起到索引的作用,中间和尾结点存储数据
- L2找到了120,如果找150,下降一层,找到了200,则数据就在150就在120~200之间
具体规则和散列类型及列表类型一样。当编码方式是REDIS_ENCODING_SKIPLIST时,Redis使用散列表和跳跃列表(skiplist)两种数据结构来存储有序集合类型键值,其中散列表用来存储元素值与元素分数的映射关系以实现0(1)时间复杂度的ZSCORE等命令。跳跃列表用来存储元素的分数及其到元素值的映射以实现排序的功能。
Redis对跳跃列表的实现进行了几点修改,其中包括允许跳跃列表中的元素(即分数)相同,还有为跳跃链表每个节点增加了指向前一个元素的指针以实现倒序查找。 采用此种编码方式时,元素值是使用redisObject存储的,所以可以使用字符串类型键值的优化方式优化元素值,而元素的分数是使用double类型存储的。 使用REDIS_ENCODING_ZIPLIST编码时有序集合存储的方式按照"元素1的值,元素1的分数,元素2的值,元素2的分数"这样的顺序排列,并且分数是有序的。















 154
154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









