







正则表达式(英文:Regular Expression)
简介:在计算机科学中,是指编写某个正则规则语法字符串来操作(获取,替换,校验)另一个字符串。
备注:通常来说,正则的规则语法通用于各个不同的平台或者编程语言,但具体到某种编程语言又有具体对于正则语法的实现,此处列举的语法具体使用时可根据软件的不同稍作改动,但这种情况毕竟属于极少数。本文以实用性为主,以NotePad++ 为验证平台,供工作中复制使用。
常用正则
| 序号 | 描述 | 正则语法 | 备注 |
|---|---|---|---|
| 1 | 匹配空白行 | \n\s*\r | 可以用来删除空白行 |
| 2 | 匹配中文字符 | [\u4e00-\u9fa5] | 可以在英文中寻找中文符号 |
| 3 | 电子邮箱 | /^([a-z0-9_.-]+)@([\da-z.-]+).([a-z.]{2,6})$/ | 程序中校验 |
| 4 | 匹配中文字符 | [\u4e00-\u9fa5] | 可以在英文中寻找中文符号 |
| 5 | 双字节字符(包括汉字在内) | [^\x00-\xff] | 一个双字节字符长度计2,ASCII字符计1 |
| 6 | 匹配中文字符 | [\u4e00-\u9fa5] | 可以在英文中寻找中文符号 |
| 7 | Email地址 | \w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)* | 表单验证时很实用 |
| 8 | 国内电话号码 | \d{3}-\d{8}|\d{4}-\d{7} | 匹配形式如 0511-4405222 |
| 9 | 身份证 | \d{15}|\d{18} | 中国大陆的身份证为15位或18位 |
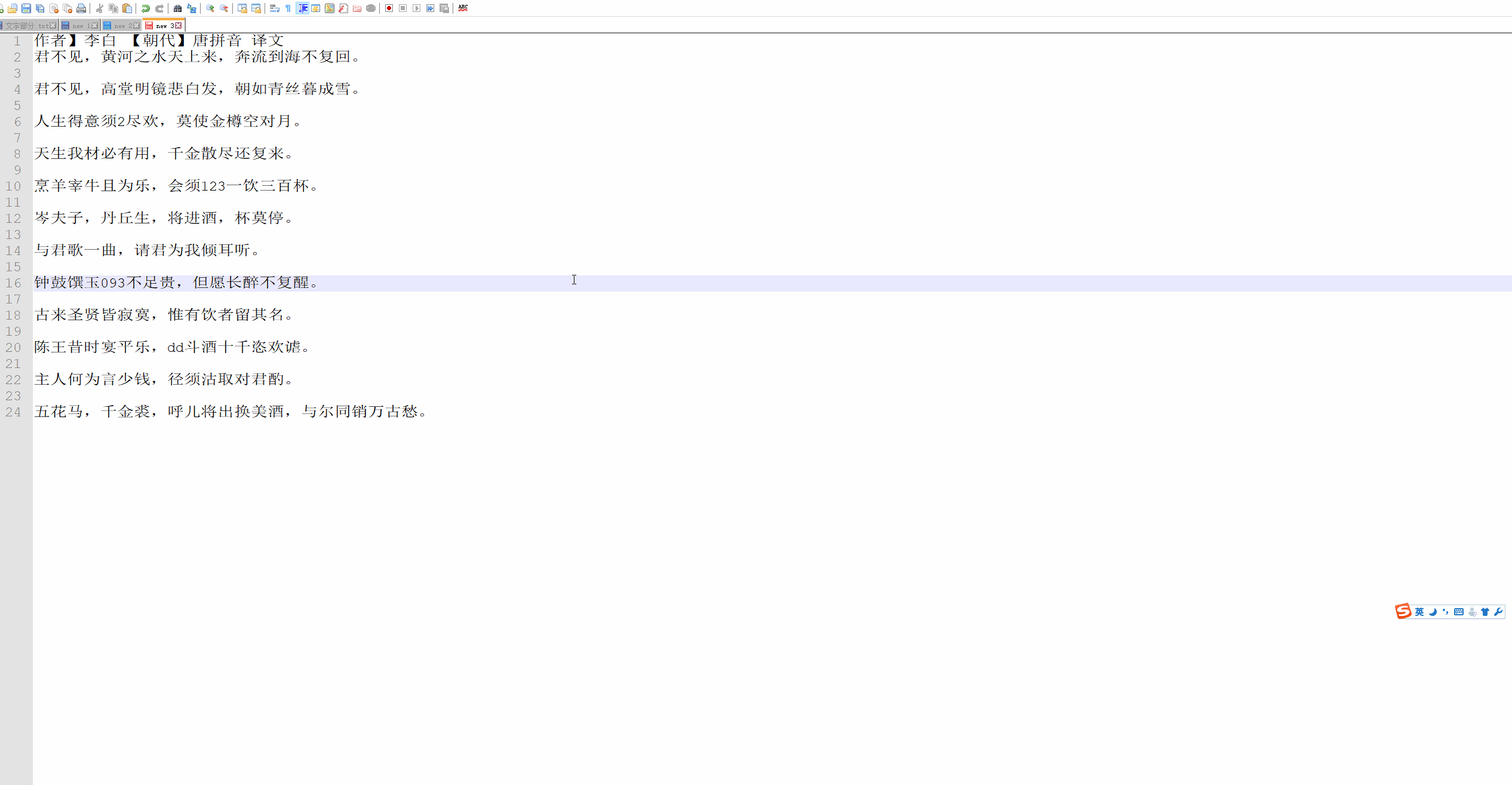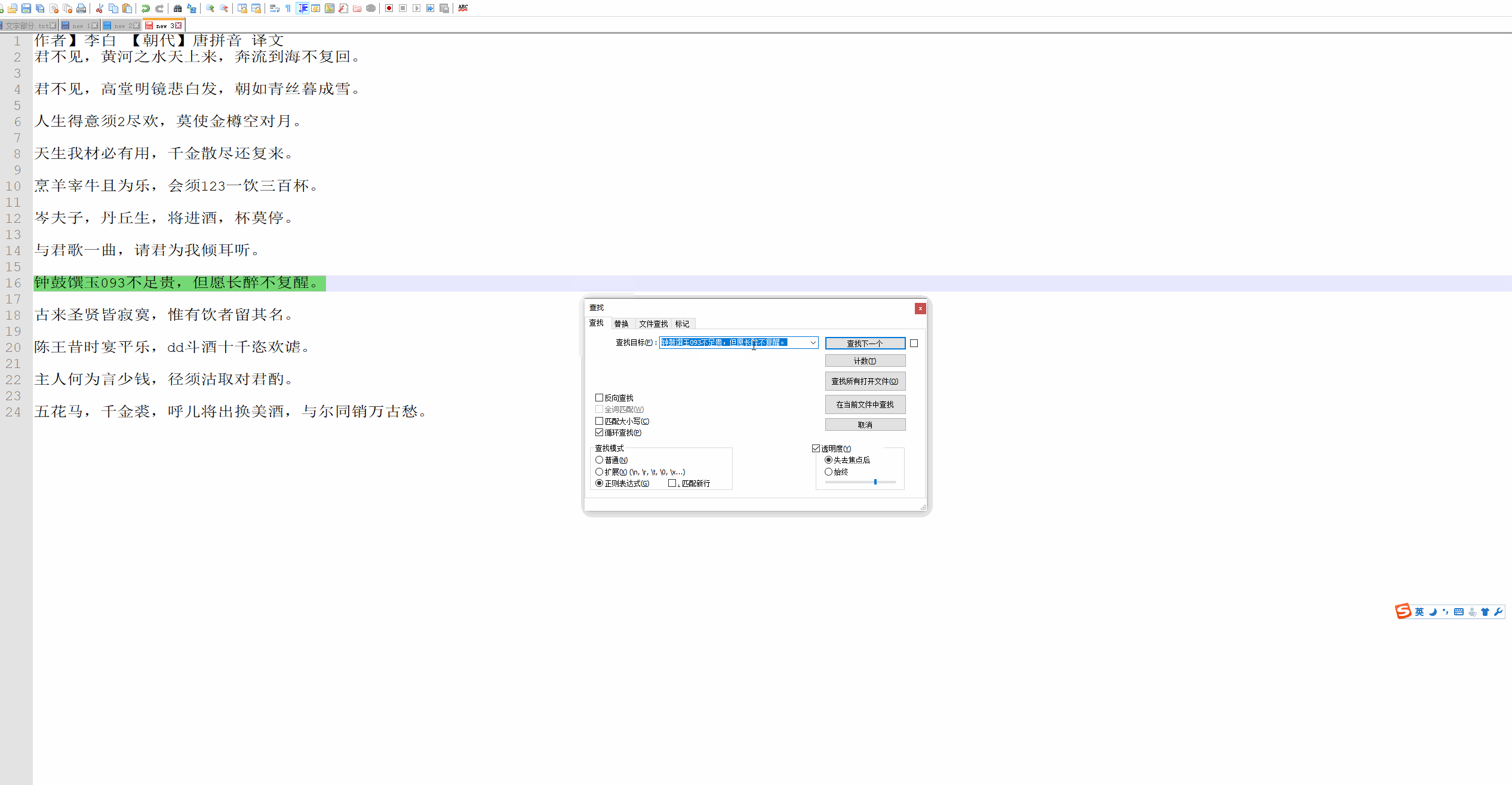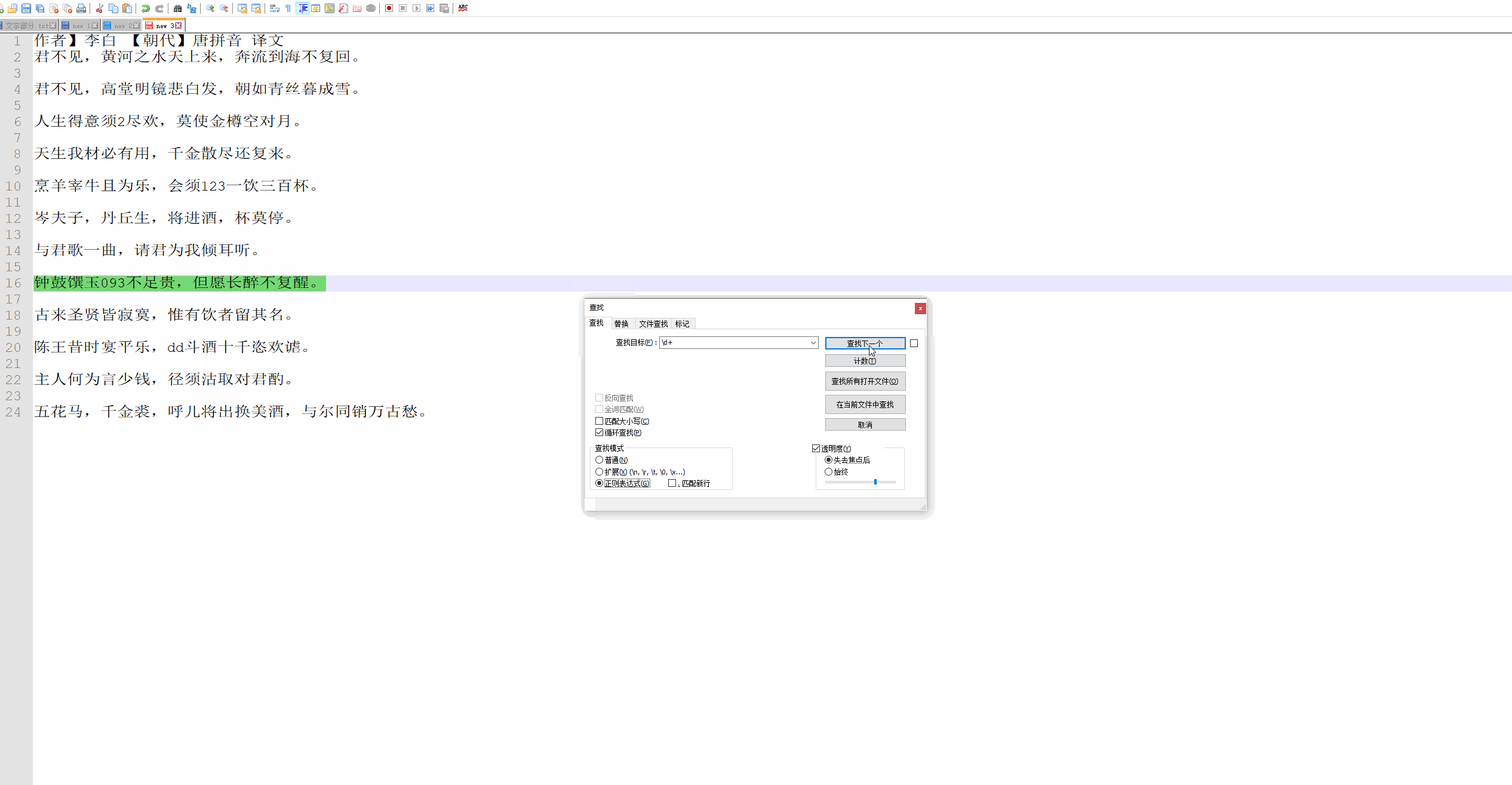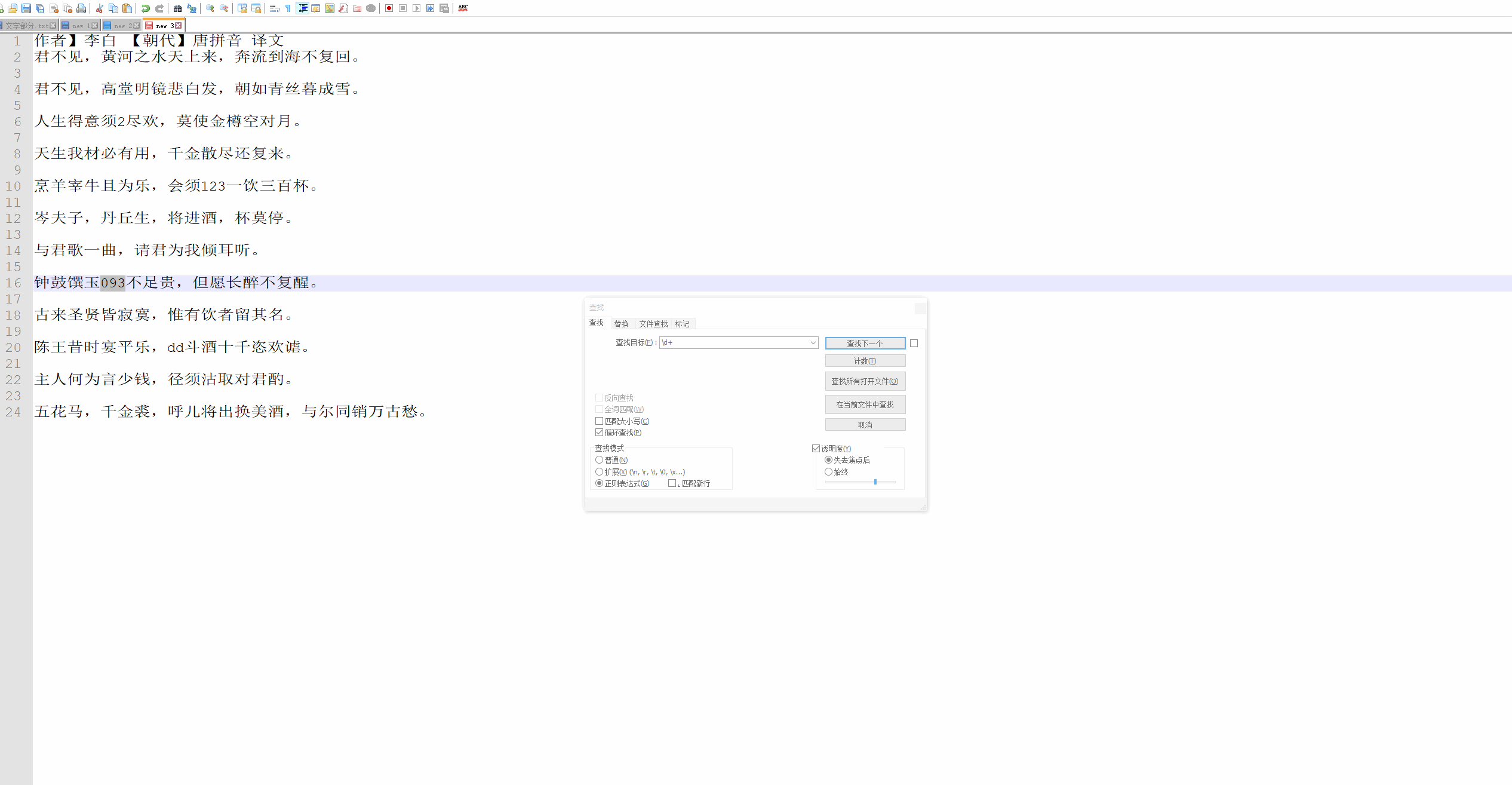
| 10 | Ip地址 | \d+.\d+.\d+.\d+ | 提取Ip地址时候有用 |
| 11 | 身份证 | \d{15}|\d{18} | 中国大陆的身份证为15位或18位 |
| 12 | 字符规则 | ^\w+$ | 英文字母或者下划线组成的字符串 |
| 13 | HTML标记 | <(\S*?)[^>]>.?</\1>|<.*? /> | 粗略匹配,具体根据业务可细分 |
| 14 | 日期 | ^\d{4}-\d{2}-\d{2}$ | (YYYY-MM-DD) |
正则表达式的语法规则
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。序列“\”匹配“\”而“(”则匹配“(”。 |
| ^ | 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
| . | 匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“[.\n]”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“”。 |
| (?:pattern) | 匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“( |
| (?=pattern) | 正向预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95 |
| (?!pattern) | 负向预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如“Windows(?!95 |
| x|y | 匹配x或y。例如,“z |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“p”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。 |
| \D | 匹配一个非数字字符。等价于[^0-9]。 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于[^\f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。. |
| \num | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
| \nml | 如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(?)。 |
平台使用实例
Excel VBA 中使用
正则表达式对象创建方式 :1: 前期绑定
添加引用库:工具 > 引用 >勾选 ’Microsoft VBScript Regular Expressions 5.5‘
'直接声明reg对象就可以使用
Dim reg As New RegExp
正则表达式对象创建方式 :2: 后期绑定
使用 CreateObject 方法来创建VBScript.RegExp对象,便可使用
' 先声明再创建Reg对象
Dim reg As Object
Set reg = CreateObject("VBScript.RegExp")
有了以上对象后,直接使用相关方法【Replace Execute Test 】结合使用两个对象【Match 对象和MatchCollection 对象】可以处理大多数业务场景。
Sub ExtractNonNum()
Dim reg As Object
Dim matches As Object, match As Object
Dim inputText As String
Dim result As String
Dim cell As Range
' 创建正则表达式对象(后期绑定)
Set reg = CreateObject("VBScript.RegExp")
' 示例被处理的字符串
inputText = "what 983 is function 1230"
' 排除匹配示例:找到不包含数字的部分
With reg
.Global = True
.Pattern = "[^0-9]+"
.MultiLine = True
' 执行匹配
Set matches = .Execute(inputText)
End With
' 把找到的字符串连接起来
result = "排除包含数字的部分: "
For Each match In matches
result = result & match.Value & " "
Next match
' 显示结果
MsgBox result
End Sub
python 中使用
python 语言的强大功能和简单易上手特性使得其正则功能也倍加受宠,直接使用其中的 re 模块便捷方便。
原文链接:https://blog.csdn.net/sloan13/article/details/141865496
re.match
import re
pattern = r'^\d{4}-\d{2}-\d{2}$'
string = '2023-10-01'
match = re.match(pattern, string)
if match:
print("Match found!")
else:
print("No match.")
re.search
import re
pattern = r'\d{4}-\d{2}-\d{2}'
string = 'The date is 2023-10-01.'
search = re.search(pattern, string)
if search:
print("Search found!")
else:
print("No search.")
re.findall
import re
pattern = r'\d{4}-\d{2}-\d{2}'
string = 'Dates: 2023-10-01, 2024-01-15.'
findall = re.findall(pattern, string)
print(findall) # Output: ['2023-10-01', '2024-01-15']
re.sub
import re
pattern = r'\d{4}-\d{2}-\d{2}'
string = 'The date is 2023-10-01.'
result = re.sub(pattern, 'YYYY-MM-DD', string)
print(result) # Output: 'The date is YYYY-MM-DD.'

















 4296
4296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









