




Observer不参与选举,,Follower参与选举
搜索技巧,在百度的搜索框中输入:
paxos site:douban.com(做一个豆瓣的定向搜索)
Paxos全解析:https://www.douban.com/note/208430424/
“ Paxos,它是一个基于消息传递的一致性算法”, Paxos还被认为是到目前为止唯一的分布式一致性算法,其它的算法都是Paxos的改进或简化。
Paxos有一个前提:没有拜占庭将军问题(网络中节点与节点之间是不可信的)。就是说Paxos只有在一个可信的计算环境中才能成立,这个环境是不会被入侵所破坏的。
“ Paxos描述了这样一个场景,有一个叫做Paxos的小岛(Island)上面住了一批居民,岛上面所有的事情由一些特殊的人决定,他们叫做议员(Senator)。议员的总数(Senator Count)是确定的,不能更改。岛上每次环境事务的变更都需要通过一个提议(Proposal),每个提议都有一个编号(PID),这个编号是一直增长的,不能倒退。每个提议都需要超过半数((Senator Count)/2 +1)的议员同意才能生效。每个议员只会同意大于当前编号的提议,包括已生效的和未生效的。如果议员收到小于等于当前编号的提议,他会拒绝,并告知对方:你的提议已经有人提过了。这里的当前编号是每个议员在自己记事本上面记录的编号,他不断更新这个编号。整个议会不能保证所有议员记事本上的编号总是相同的。现在议会有一个目标:保证所有的议员对于提议都能达成一致的看法。”
“ 好,现在议会开始运作,所有议员一开始记事本上面记录的编号都是0。有一个议员发了一个提议:将电费设定为1元/度。他首先看了一下记事本,嗯,当前提议编号是0,那么我的这个提议的编号就是1,于是他给所有议员发消息:1号提议,设定电费1元/度。其他议员收到消息以后查了一下记事本,哦,当前提议编号是0,这个提议可接受,于是他记录下这个提议并回复:我接受你的1号提议,同时他在记事本上记录:当前提议编号为1。发起提议的议员收到了超过半数的回复,立即给所有人发通知:1号提议生效!收到的议员会修改他的记事本,将1好提议由记录改成正式的法令,当有人问他电费为多少时,他会查看法令并告诉对方:1元/度。”(过半通过,两阶段提交)
“ 现在看冲突的解决:假设总共有三个议员S1-S3,S1和S2同时发起了一个提议:1号提议,设定电费。S1想设为1元/度, S2想设为2元/度。结果S3先收到了S1的提议,于是他做了和前面同样的操作。紧接着他又收到了S2的提议,结果他一查记事本,咦,这个提议的编号小于等于我的当前编号1,于是他拒绝了这个提议:对不起,这个提议先前提过了。于是S2的提议被拒绝,S1正式发布了提议: 1号提议生效。S2向S1或者S3打听并更新了1号法令的内容,然后他可以选择继续发起2号提议。”
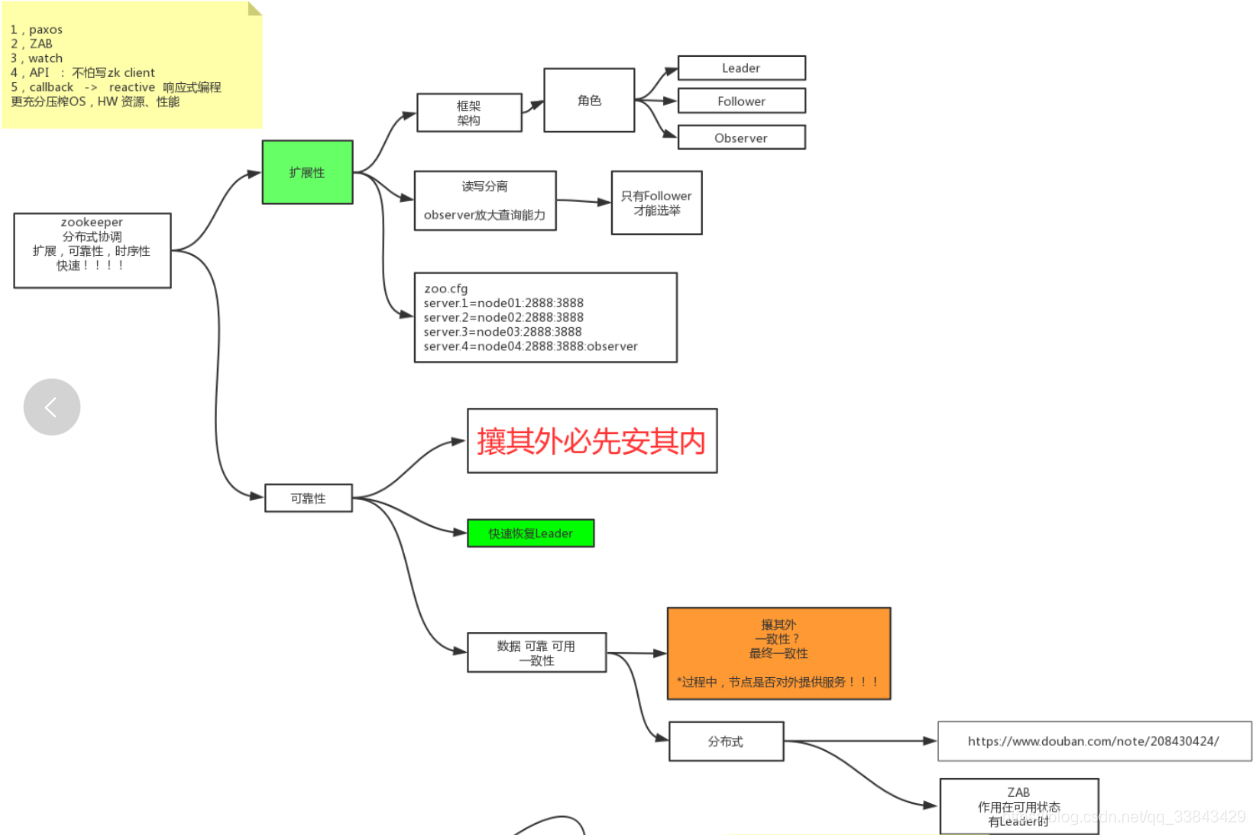
ZAB协议:Zookeeper 原子 广播,zookeeper的协议,是Paxos协议的缩减版,更容易实现数据在可用状态(有leader时 )下的同步。
zookeeperZAB协议流程图如下,核心点是队列(广播到每个follower的队列)和2PC(两个阶段提交:第一阶段写磁盘日志,第二阶段write到内存,更新内存状态,最终能对外提供内存的查询),主从模型,主是单点,单点处理顺序性的事情,主负责维护队列,维护所有事务的两阶段提交,维护过半通过。
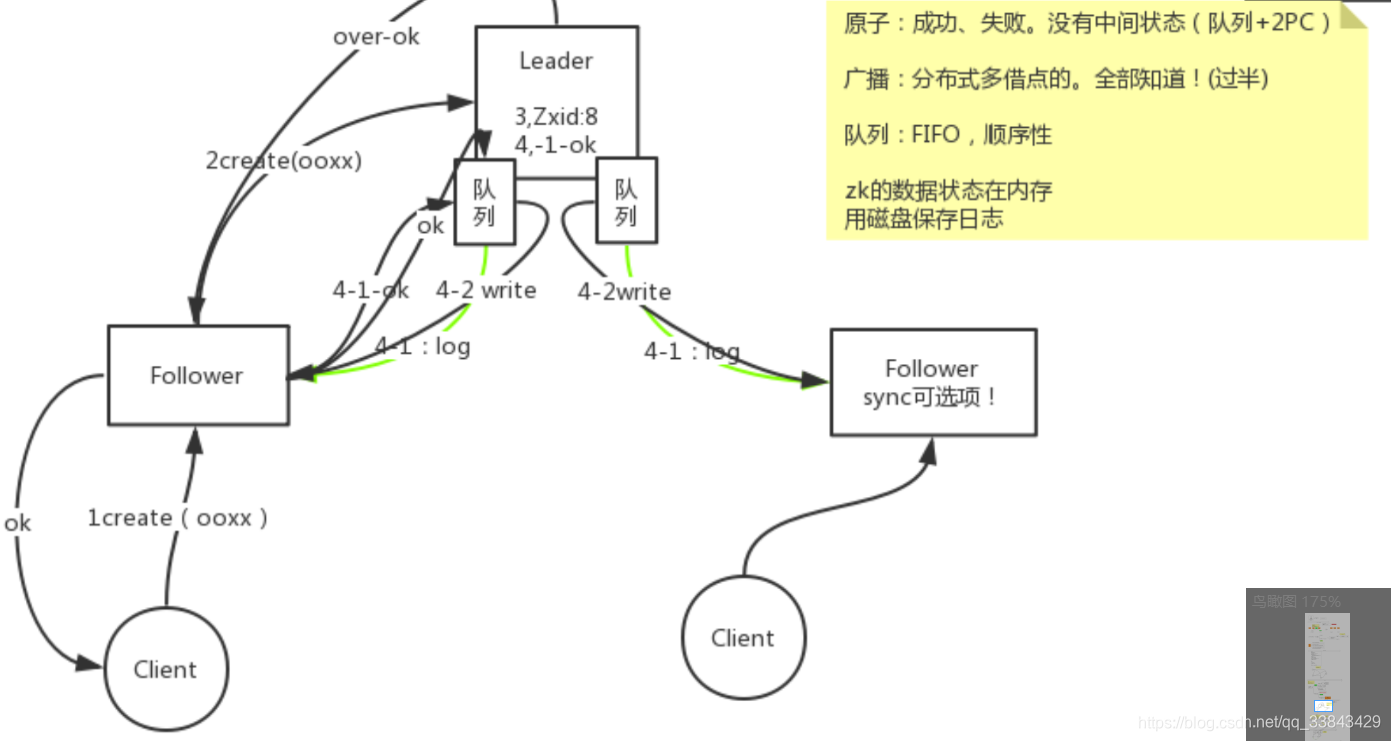
zookeeper一挂,所有人都对外停止提供服务,开始选leader,建立连接,同步完数据,才开始对外提供服务,做到最终一致性。
过程中,节点是否对外提供服务,取决于节点的状态,有些状态是可以提供服务的,有些状态不能对外提供服务(例如,从连不上主),一个client连接上掉线的follower,可以调用该follower的回调callback服务,等待follower连接上leader,sync同步完以后,拿到数据,回调服务就可以返回数据。
zookeeper选举:采用谦让制,要使用到server自己的id和事务的Zxid。
M:myid server.id, Z:Zxid事务id
leader选举时,达到过半开始选举,先看事务id,大的选谁,事务id一样的情况下,选myid大的。
zookeeper详细投票过程(zookeeper可以200ms内选出leader):
假设存在如下情况,node04是leader,node03还没同步完,事务id是7,比node01和02的事务id低一些。此时leader node04挂了,1s一次心跳,其他的node会发现leader挂了,如果恰巧不幸的是,node03(事务id低的)先发现leader挂了,node03会拿着server.id和Zxid通过socket发送给node01和02,node03此时投票自己+1,node01和node02(收票者)收到node03(投票者)的票,与比较的事务id相比,淘汰此票(因为自己的事务id更高),收票者如果否定对方,要给对方纠正,所以node01和ndoe02都会把自己的server.id和Zxid发给node03。重要的是,收票者会被动触发自己给自己投票,并把自己的票广播出去。node02自己给自己投票,node02票+1,node01和03收到02的票,对比过以后发现比自己大,又把node02的票返回来,node02票+2=3票。所以最后,所有的投票者和收票者都会拿到所有其他的投票者的票对比,自己与是leader那个node比较(自己认可,给leader那个node投一票),其他node的认可(给leader那个node投node总数-1(当前node)这么多票),所以最后每个node都会给那个node02节点投三票,因为node02的server.id和Zxid都是最高的。

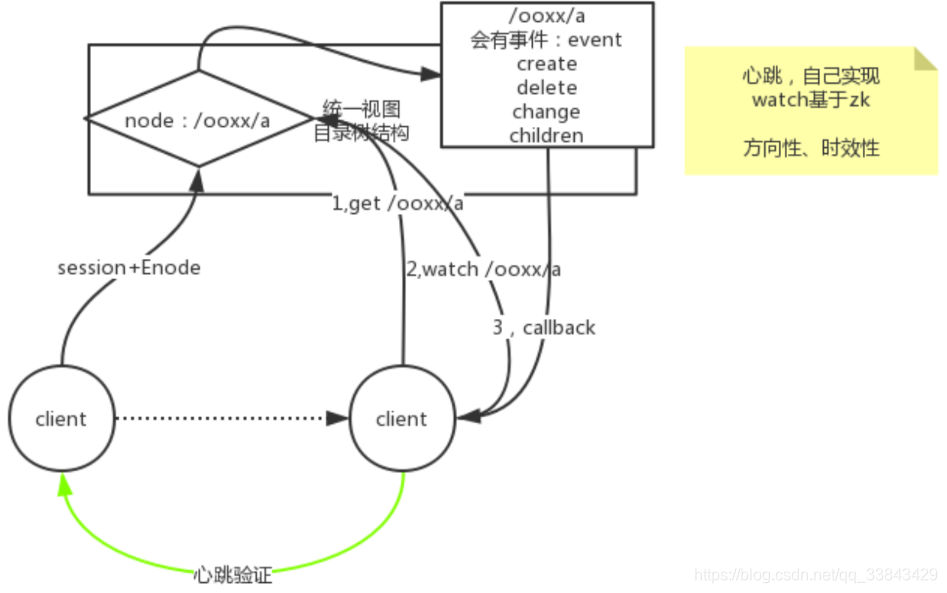
zookeeper内部的watch监控机制基于callback回调,比两个client之间自己写个对别人的心跳检测速度要快得多,zookeeper的时效性。
Netty含金量很高,决定了服务器发挥50%能力还是发挥80%的能力。
zookeeperAPI实操,详见IDEA项目:zookeeper:
强调:zookeeper集群用的哪个版本,客户端就要相应用import哪个版本的maven依赖。
zookeeper都是跟session绑定在一起的,zk没有连接池的概念。
创建一个maven项目:
在App.class中,
public class App
{
public static void main(String[] args ) throws IOException, InterruptedException, KeeperException {
System.out.println("Hello World!");
//param1:zk集群连接的字符串,用逗号隔开; param2:session的超时时间, 这个session断开后,那个临时节点就存活3秒; param3 watch
//watch 分两类,第一类:new zk时传入的watch,这个watch是session级别的,跟path,node没有关系
final CountDownLatch countDownLatch = new CountDownLatch(1);
final ZooKeeper zk = new ZooKeeper("", 3000, new Watcher() {
//watch的回调方法
@Override
public void process(WatchedEvent event) {
Event.KeeperState state = event.getState();
Event.EventType type = event.getType();
String path = event.getPath();
System.out.println("zk watch:"+event.toString());
switch (state) {
case Unknown:
break;
case Disconnected:
break;
case NoSyncConnected:
break;
case SyncConnected:
System.out.println("connected");
countDownLatch.countDown();
break;
case AuthFailed:
break;
case ConnectedReadOnly:
break;
case SaslAuthenticated:
break;
case Expired:
break;
}
switch (type) {
case None:
break;
case NodeCreated:
break;
case NodeDeleted:
break;
case NodeDataChanged:
break;
case NodeChildrenChanged:
break;
}
}
});
countDownLatch.await();
ZooKeeper.States states = zk.getState();
switch (states) {
case CONNECTING:
System.out.println("connecting!");
break;
case ASSOCIATING:
break;
case CONNECTED:
System.out.println("connected!");
break;
case CONNECTEDREADONLY:
break;
case CLOSED:
break;
case AUTH_FAILED:
break;
case NOT_CONNECTED:
break;
}
String pathName = zk.create("/ooxx", "olddata".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
final Stat stat = new Stat();
byte[] data = zk.getData("/ooxx", new Watcher() {
//在取数据的同时注册一个观察Watch,未来这个节点发生变化以后会回调这个方法。
@Override
public void process(WatchedEvent event) {
System.out.println("getData watch: " + event.toString());
//以下代码让zk重新注册这个watch
try {
zk.getData("/ooxx",this, stat);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, stat);
System.out.println(new String(data));
//以下这个stat是有没有设置成功,原数据会返回
//同时以下会产生/ooxx这个节点变化的event,触发getData注册的回调事件
Stat stat1 = zk.setData("/ooxx", "newdata01".getBytes(), 0);
//还会不会回调getData的方法,不会,是一次性的
Stat stat2 = zk.setData("/ooxx", "newData02".getBytes(), stat1.getVersion());
Thread.sleep(222222222);
System.out.println("--------------async start--------------");
zk.getData("/ooxx", false, new AsyncCallback.DataCallback() {
//getdata自己的callback函数
//getData没有返回值也不会阻塞,rc返回状态码,path路径,data取到的数据,stat元数据,ctx是可以传任何东西进去、传参
@Override
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
System.out.println("--------------async call back--------------");
System.out.println(new String(data));
System.out.println(ctx.toString());
}
},"abc");
System.out.println("--------------async over--------------");
}
}

















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









