







创建Hadoop用户
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop
可为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:
sudo adduser hadoop sudo
最后注销当前用户(点击屏幕右上角的齿轮,选择注销),在登陆界面使用刚创建的 hadoop 用户进行登陆。
更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
sudo apt-get update
然鹅很讨人厌的是,终端提示:
hadoop 不在 sudoers 文件中。此事将被报告。
一通儿百度之后,解释为:sudo命令可以让你以root身份执行命令,来完成一些我们这个帐号完成不了的任务。
其实并非所有用户都能够执行sudo,因为有权限的用户都在/etc/sudoers中。
解决方法为:
首先,su - 进入root权限
然后,我们可以通过编辑器来打开/etc/sudoers,或者直接使用命令visudo来搞定这件事情。
打开sudoers后,像如下那样加上自己的帐号保存后就可以了。
User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL #此行为添加行
然鹅又整出幺蛾子了,在hadoop用户中一旦输入任何与sudo有关的需要root权限的命令,就开始提示我:
hadoop 不在 sudoers 文件中。此事将被报告。
!!这不就变成死循环了么,解决该问题的过程中又出现了该问题。但是其实是我傻,只需要切换到原来的用户中,通过vim编辑器修改sudoers只读文件,再切回到hadoop用户即可。
在原用户中:
$ sudo su
# cd /etc
# cat sudoers //打开文件,发现只有一行root ALL=(ALL:ALL) ALL 于是安装了一下vim
# vim sudoers //修改成上面那样子
vim 中的操作:
hadoop ALL=(ALL:ALL) ALL //此行为添加行,因为是只读文件,不能通过gedit编辑器来直接修改,还需要root权限才能搞动它。同时会各种提示“确定要修改只读文件么?”哎呀忽略它就好。
按ESC+:wq! //注意这里要+!才能强制修改只读文件的内容,到这里文件就修改好啦!不放心的话可以再cat sudoers查看一下文件权限是否已经修改成功
现在我们切回hadoop用户,输入
$ sudo su
发现没有问题啦!
继续输入:
# sudo apt-get update
完成apt的更新。
安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
$ sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
终端询问:are u sure u want to continue connecting ,输入yes
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
$ exit # 退出刚才的 ssh localhost,提示注销
# Connection to localhost closed.
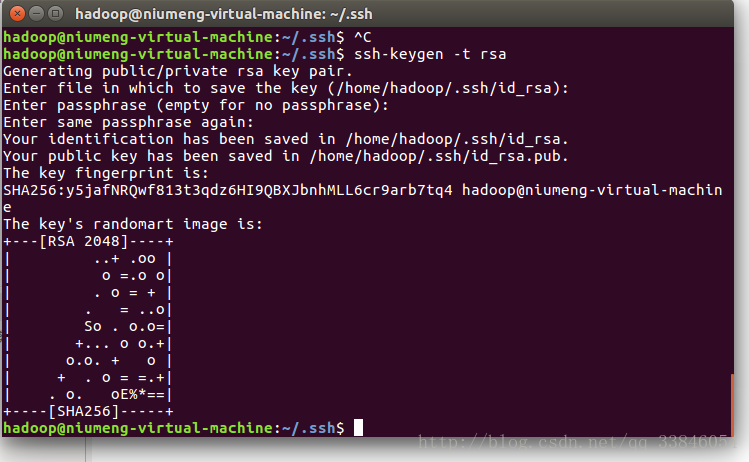
$ cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
$ ssh-keygen -t rsa # 会有提示,都按回车就可以
~的含义
在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/”。 此外,命令中的 # 后面的文字是注释。
显示:
最后:
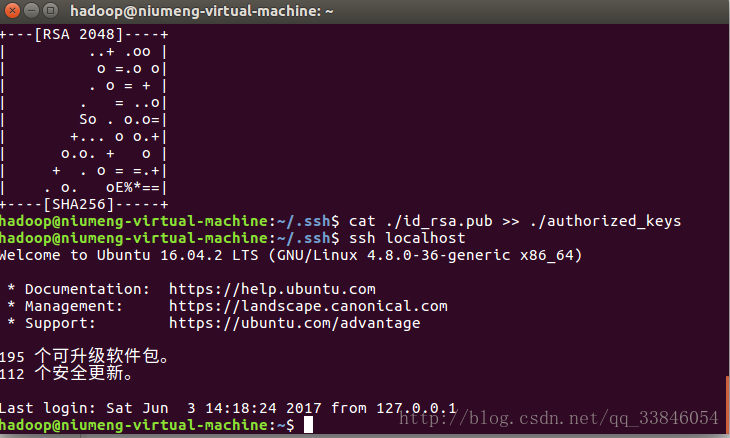
$ cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再输入:
ssh localhost
便无需输入密码了:
安装Java环境
安装JDK的过程看似非常简单,但是没有考虑到我是在当前hadoop用户下安装,结果这个用户又跟在上一步骤一样给我整出了若干幺蛾子。。还好最后成功解决了问题,谢天谢地。。
1、解压源码包
通过终端在/usr/lib 目录下新建jdk文件夹,命令行:
sudo mkdir /usr/lib/jdk
然后将下载到压缩包拷贝到Java文件夹中,命令行:
进入jdk源码包所在目录
cp jdk-8u131-linux-x64.tar.gz /usr/lib/jdk
然后进入java目录,命令行:
cd /usr/lib/jdk
解压压缩包,命令行:
sudo tar xvf jdk-8u131-linux-x64.tar.gz
然后可以把压缩包删除,命令行:
sudo rm jdk-8u131-linux-x64.tar.gz
2、设置jdk环境变量
这里采用全局设置方法,它是是所有用户的共用的环境变量。用vim编辑器或者是gedit都可以。
$sudo gedit ~/.bashrc
打开之后在末尾添加
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_131 #此为jdk在步骤1中安装的路径
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
请记住,在上述添加过程中,等号两侧不要加入空格,不然会出现“不是有效的标识符”,因为source /etc/profile 时不能识别多余到空格,会理解为是路径一部分。点击保存,关闭gedit。
3.配置默认JDK版本
步骤三须知:如果是在原来的root用户下,不需要这一步直接就出来步骤四的安装结果了。但是我的hadoop用户选手2号实在是不给力,偏偏给出这样子的提示:
程序 'java' 已包含在下列软件包中:
* default-jre
* gcj-4.9-jre-headless
* gcj-5-jre-headless
* openjdk-8-jre-headless
* gcj-4.8-jre-headless
* openjdk-9-jre-headless
这让我白白浪费了一两个小时去解决这个问题呀。因为看到有的博客通过如下命令:
$ sudo apt-get install openjdk-9-jre openjdk-9-jdk
安装openjdk,而不是oracle家的jdk。这里请自行百度两者区别,对我来说安装openjdk的命令貌似更简洁,于是我便开始apt-get install openjdk,但很遗憾的是报出乱七八糟的E:无法解析域名错误,于是我就找到了相关解决方法:http://www.linuxdiyf.com/linux/504.html。但是朋友们,这错误是越搞越多啊!
就在我准备放弃这一阶段时,转机出现了,感谢下面的博客:
http://blog.csdn.net/vicky__rain/article/details/53539437
于是我便转移到了root用户,离开我们的hadoop选手二号,在niumeng用户选手一号中没有任何问题,我便照着博客中写的如下的四行代码:
sudo update-alternatives --install /usr/bin/java java /usr/lib/jdk/jdk1.8.0_131/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jdk/jdk1.8.0_131/bin/javac 300
sudo update-alternatives --install /usr/bin/jar jar /usr/lib/jdk/jdk1.8.0_131/bin/jar 300
sudo update-alternatives --config java
检查:
sudo update-alternatives --config java
终于!成功了!!!这件事情告诉我们一个道理:一条死胡同走不通的时候,不妨试一试下一条死胡同。
4、检验是否安装成功
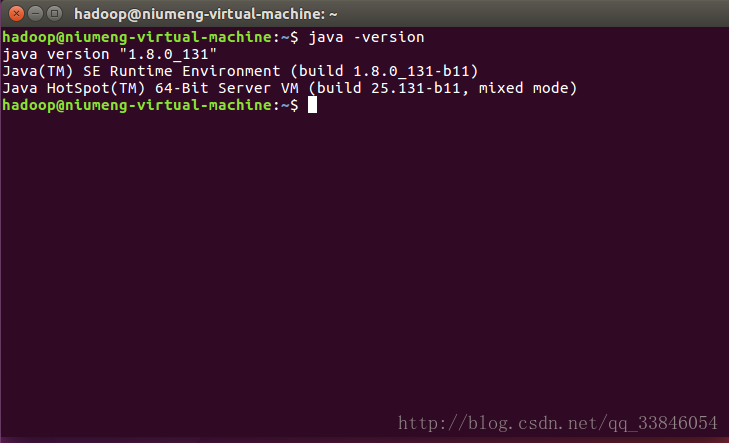
在终端输入如下命令
java -version
看看是否安装成功
安装hadoop3.0.0-alpha3
将压缩包(hadoop-3.0.0-alpha3.tar.gz)放在"下载"目录下,然后输入命令:
cd ~/下载
进入下载目录,然后输入命令:
sudo tar -zxf hadoop-3.0.0-alpha3.tar.gz -C /usr/local
这样就将文件解压到"/usr/local"路径下,进入该路径:
cd /usr/local/
然后将文件夹名改名为"hadoop":
sudo mv ./hadoop-3.0.0/ ./hadoop
最后修改文件权限:
sudo chown -R hadoop:hadoop ./hadoop
输入命令查看hadoop是否可用:
/hadoop/bin/hadoop version
如果配置正确此时应该出现hadoop 的版本信息,但是很气人地是提示:
Error:JAVA_HOME is not set and could not be found
那好吧,我深吸一口气,既然如此,那就继续搞吧。
百度了一下解决方案:
http://www.cnblogs.com/codeOfLife/p/5940642.html
庆幸地发现输入export的时候我的JAVA_HOME环境变量貌似是我第一遍配置时的信息,果然通过:
gedit ~/.bashrc
发现我的环境变量莫名其妙地不好了,吓得我赶紧重新配置了一小下下。再次输入
$ cd /usr/local/hadoop
$ ./bin/hadoop version
注意这里因为已经进到了/usr/local/hadoop文件级中, ./bin/hadoop version便是指的相对路径,它的绝对路径是:
/usr/local/hadoop /bin/hadoop version
终于成功啦!
因为hadoop3的网上教程比较少,所以我们决定安装hadoop2.7.3,故要先删除原来的hadoop文件夹,然后如法炮制地安装即可。
$ cd /usr/local
$ sudo rm -rf hadoop
$ ls
即成功删除。
补充知识:
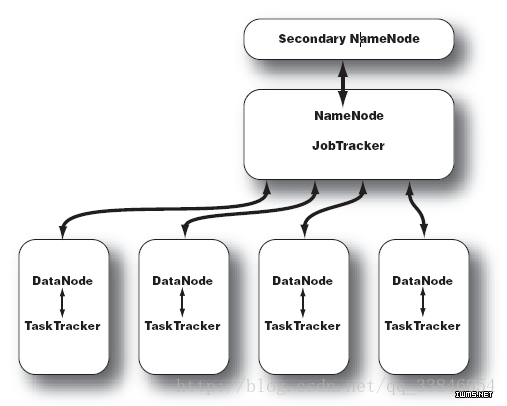
Hadoop的集群主要由 NameNode,DataNode,Secondary NameNode,JobTracker,TaskTracker组成.如下图所示:
NameNode中记录了文件是如何被拆分成block以及这些block都存储到了那些DateNode节点.NameNode同时保存了文件系统运行的状态信息. DataNode中存储的是被拆分的blocks.Secondary NameNode帮助NameNode收集文件系统运行的状态信息.JobTracker当有任务提交到Hadoop集群的时候负责Job的运行,负责调度多个TaskTracker.TaskTracker负责某一个map或者reduce任务.
创建目录
hadoop dfs -mkdir /home
上传文件或目录到hdfs
hadoop dfs -put hello /
hadoop dfs -put hellodir/ /
查看目录
hadoop dfs -ls /
创建一个空文件
hadoop dfs -touchz /361way
删除一个文件
hadoop dfs -rm /361way
删除一个目录
hadoop dfs -rmr /home
重命名
hadoop dfs -mv /hello1 /hello2
查看文件
hadoop dfs -cat /hello
将制定目录下的所有内容merge成一个文件,下载到本地
hadoop dfs -getmerge /hellodir wa
使用du文件和目录大小
hadoop dfs -du /
将目录拷贝到本地
hadoop dfs -copyToLocal /home localdir
查看dfs的情况
hadoop dfsadmin -report
查看正在跑的Java程序
jps
上面就是Linux使用hadoop dfs命令的方法介绍了,hadoop dfs命令组合各种参数能够实现多种操作,你可以选择一条命令只需看看。
到此,单机集群安装已经完成,经过单机实例测试和伪分布式的实例测试之后(在此省略,请看 http://www.powerxing.com/install-hadoop/),我们要尝试着搭建集群了。
硬件环境:
五台机器,连接电源线,连接网线到交换机,一台显示器,一个kvm。通过启动盘安装Ubuntu-16.04.02,删除硬盘内所有内容安装。
tips:(学长教的!)
安装时如若想节约安装时间,不至于浪费一个下午来安装。可以制作两个启动盘,流水式操作安装。安装一个的时候,点击完所有需要点击的步骤之后,拔掉显示器接头,同时插到另一台机器上,插另一个U盘。过一会回来检查一下刚才那台机器是否安装成功。
注意:
在安装时有两个需要特别注意,用户名和机器名,这里统一:
用户名:hadoop
机器名:依次为master0 ,master1, slave0, slave1, slave2
密码:hadoop
如果手速太快搞错了,没关系,安装成功之后通过
vim /etc/hostsname
也可以修改主机名
通过创建新用户可以修改用户名。
我们的脚本工作步骤
因为这里有五台机器,一台一台手动配置总是不太显示的哈。所以这个时候便需要脚本来替我们干活啦!
脚本是什么?
linux shell 编程是什么:
shell是一个命令处理器(command processor)——是一个读入并解释你输入的命令的程序。除了是一个命令中断器以外,shell还是一个程序设计语言。你可以编写shell可以解释的程序(被称为源程序),这些源程序可以包含shell程序设计命令等等。shell除了解释命令以外,还有其他工作,它也可以配置和编程。shell拥有自己的语言允许用户编写程序并以一种复杂方式运行。shell编程语言具有许多常用的编程语言的特征,例如:循环和控制结构等。用户可以生成像其他应用程序一样复杂的shell程序。
补充说明:简单的说 : shell 是一个交互性命令解释器。shell独立于操作系统,这种设计让用户可以灵活选择适合自己的shell。shell让你在命令行键入命令,经过shell解释后传送给操作系统(内核)执行。
脚本学习阶段
视频信息:
https://ke.qq.com/teacher/407021204
中的linux下shell编程从入门到精通(完整版)
下面罗列一下用得比较多的东西:
概念:
1)
shell是什么:
shell是操作系统的最外层(所以叫shell嘛),是一门用C语言编写的程序。shell可以合并编程语言以控制进程和文件,以及启动和控制其他的程序。shell通过提示您输入,向操作系统解释该输入,然后处理来自操作系统的结果。简单来说,shell就是一个用户和操作系统之间的一个命令解释器。shell是用户和linux操作系统之间沟通的桥梁。用户可以输入命令执行,又可以利用shell脚本编程去运行。
关系:
kernel (内核)- shell(夹在中间的命令解释器) - utilities (使用者-用户)
常见的shell语言:
sh bash ksh csh ,最常见的是bash(Bourne again shell),linux系统中集成了bash。
tip:
chmod +x filename.sh 改变文件的属性(读写权限)
./ filename.sh 表示当前目录下的文件
例子:
下面我们从经典的“hello world”入手,看一看最简单的Shell脚本的模样。
#!/bin/sh
#print hello world in the console window
a = "hello world" #赋值
echo $a # $为取值符号
如果出现混淆的情况,可以使用花括号来区分。
echo命令介绍:
功能说明:显示文字。
语 法:echo [-ne][字符串] / echo [–help][–version]
补充说明:echo会将输入的字符串送往标准输出。输出的字符串间以空白字符隔开, 并在最后加上换行号。
tip:
Shell Script是一种弱类型语言,使用变量的时候无需首先声明其类型。新的变量会在本地数据区分配内存进行存储,这个变量归当前的Shell所有,任何子进 程都不能访问本地变量。这些变量与环境变量不同,环境变量被存储在另一内存区,叫做用户环境区,这块内存中的变量可以被子进程访问。
- 本地数据区:变量 set :显示本地数据区和用户环境区的变量和取值 unset:删除指定变量当前取值,该值被认为NULL
- 用户环境区:环境变量 env:显示用户环境区中的变量和取值
export :用于将本地数据区中的变量转移到用户环境区
流程控制语句:
if …;then
…
elif …;then
…
else
…
fi
fi 为if语句块的结束,是一个特殊的命令,称为空命令,不做任何事。
条件判断语句:
第三行中的[]表示条件测试,常用的条件测试有下面几种:
[ -f "
f
i
l
e
"
]
判
断
file" ] 判断
file"]判断file是否是一个文件
[
a
−
l
t
3
]
判
断
a -lt 3 ] 判断
a−lt3]判断a的值是否小于3,同样-gt和-le分别表示大于或小于等于
[ -x "
f
i
l
e
"
]
判
断
file" ] 判断
file"]判断file是否存在且有可执行权限,同样-r测试文件可读性
[ -n "
a
"
]
判
断
变
量
a" ] 判断变量
a"]判断变量a是否有值,测试空串用-z
[ “
a
"
=
"
a" = "
a"="b” ] 判断
a
和
a和
a和b的取值是否相等
[ cond1 -a cond2 ] 判断cond1和cond2是否同时成立,-o表示cond1和cond2有一成立
要注意条件测试部分中的空格。在方括号的两侧都有空格,在-f、-lt、=等符号两侧同样也有空格。如果没有这些空格,Shell解释脚本的时候就会出错。
参数:
$# 表示包括$0在内的命令行参数的个数。在Shell中,脚本名称本身是$0,剩下的依次是$0、$1、$2…、${10}、${11},等等。$*表示整个参数列表,不包括$0,也就是说不包括文件名的参数列表。
here 文档:
Shell Script编程中被称为Here文档,Here文档用于将多行文本传递给某一命令
Here文档的格式是以<<开始,后跟一个字符串,在 Here文档结束的时候,这个字符串同样也要出现,表示文档结束
while 语句:
while [ cond1 ] && { || } [ cond2 ] …; do
…
done
for var in …; do
…
done
for (( cond1; cond2; cond3 )) do
…
done
until [ cond1 ] && { || } [ cond2 ] …; do
…
done
脚本实战阶段
脚本功能:
- 实现master机器ssh免密登录到其他机器
- 实现master机器的jdk+hadoop安装以及环境变量的配置
- master发送jdk+hadoop给slave机器并协助他们环境配置
- 测试hadoop是否安装成功
脚本1:auto_2.sh + slave_use.sh
实现思路:
我们的客户机通过xshell等远程登录工具来登录一台master机器,运行auto_2.sh脚本,根据相应提示输入欲远程连接的机器的IP地址和登录密码,然后master开始产生公钥并加入授权文件,至此,master可以无密码登录到本机;master节点给slave节点发送公钥以及第二个脚本文件slave_use.sh,然后ssh 到slave,手动输入“bash slave_use.sh”即可开始运行slave_use.sh,内容为如果没有.ssh文件夹则创建,然后把公钥追缴到授权文件中,输入"exit"即回到auto_2.sh脚本,继续询问:是否还需要免密登录其他机器。
#!/bin/bash
#author niumeng
#auto_2.sh
# ssh 远程服务器
#ssh hadoop@"$remote_ip"
# expect 自动输入密码登录master节点,现在客户机操作的是master
#expect <<EOF
#spawn ssh hadoop@"$remote_ip"
#expect "password:"
#send "hadoop\r"
#expect "*Last login*"
#interact
#EOF
# 如果我们有xshell,直接使用xshell模拟终端登录master,不用ssh远程登录
echo "-------------欢迎操作远程登录脚本:$0-------------"
x=1
user=hadoop
while [ ${x} -eq 1 ]
do
echo "请输入您要远程登录的服务器相关信息:)"
echo "登录服务器ip:"
read remote_ip
echo "登录服务器pwd:"
read remote_Password
# 1.master 节点创建公钥
# 如果没有该目录,创建该目录
if [ ! -d /home/$USER/.ssh ];then
mkdir ~/.ssh
fi
cd ~/.ssh
# 删除之前生成的公钥
if [ -f ./id_rsa ];then
rm -rf ./id_rsa
fi
if [ -f ./id_rsa.pub ];then
rm -rf ./id_rsa.pub
fi
ssh-keygen -t rsa
# 生成公钥
echo "master节点生成公钥成功!:)"
#----------------------------------------------
#2. master 节点无密码SSH localhost
cat ./id_rsa.pub >> ./authorized_keys
# 测试登录本机
#expect <<EOF
#set timeout -1
#spawn ssh localhost
#expect {
#"yes/no" { send "yes\r" }
#"password:" { send "hadoop\n" }
# }
#expect eof
#EOF
if [ $? -eq 0 ];then
echo "追加授权文件成功!"
else
echo "追加授权文件失败!请查找原因! "
fi
#3.将本机密钥发送给slave节点
scp ./id_rsa.pub $user@$remote_ip:/home/$user
# 可用expect省略输入密码部分
if [ $? -eq 0 ];then
echo "发送密钥成功!"
else
echo "发送密钥失败!请查找原因! "
fi
#4.把slave节点需要执行的命令文件发送到slave
scp ~/slave_use.sh $user@$remote_ip:/home/$user
if [ $? -eq 0 ];then
echo "发送slave_use.sh成功!"
else
echo "发送slave_use.sh失败!请查找原因! "
fi
#5.ssh node
# 此处可改进为expect自动登录
ssh $user@$remote_ip
#6.end
echo "本台服务器已经成功实现免密登录功能!您是否要继续登录其他机器?"
read -p "yes请输入1/no请输入0:" x
done
# 如果报错:sign_and_send_pubkey: signing failed: agent refused operation
#执行如下两条语句则可以成功运行!
eval "$(ssh-agent -s)"
ssh-add
#!/bin/bash
#author niumeng
#slave_use.sh
# 已经把id_rsa.pub公钥发送到服务器的~/
#在slave上,将公钥加入授权
user=hadoop
if [ ! -f ~/.ssh ];then
mkdir /home/$user/.ssh
echo "在slave节点上创建.ssh文件夹成功!"
fi
cat /home/$user/id_rsa.pub >> /home/$user/.ssh/authorized_keys
if [ $? -eq 0 ];then
echo "公钥加入slave节点授权文件"
else
echo "加入授权文件失败!请查找原因!"
fi
脚本2:
目的:在master和slave节点上安装JDK+hadoop,并完成环境变量的配置;以及hadoop配置文件的设置。
step1:
auto_install.sh:从客户机上向五台机器上发送JDK+HADOOP的安装包,以及在节点上运行的脚本文件slave_use_install,以及环境变量的配置内容(这个是用来cat追加的,应该可以写到脚本里)
auto_install.sh
#!/bin/bash
#author niumeng
#auto install jdk and hadoop as well as path
x=1
while [ $x -eq 1]
do
echo "----------欢迎来到远程安装JDK + hadoop 的脚本:$0----------"
echo "请输入您要远程登录的服务器相关信息:)"
echo "登录服务器ip:"
read remote_ip
echo "登录服务器pwd:"
read remote_Password
user=hadoop
#step1:进入~/下载,把本地的jdk+hadoop+enviroment.sh+slave_use_install.sh发送到远程登录机器的下载目录下
scp ~/下载/jdk-8u131-linux-x64.tar.gz $user@$remote_ip:/home/$user/下载
scp ~/下载/hadoop-2.7.3.tar.gz $user@$remote_ip:/home/$user/下载
scp ~/下载/environment.sh $user@$remote_ip:/home/$user/下载
scp ~/slave_use_install.sh $user@remote_ip:/home/$user/下载
if [ $? -eq 0 ];then
echo "发送两个压缩包成功!"
else
echo "发送失败!请查找原因!"
fi
echo "是否还要继续发送文件到其他节点?yes:1/no:0"
read x
done
完善:如何用循环直接把四个文件传送给五台机器?
environment.sh
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
slave_install_use.sh
#!/bin/bash
#author niumeng
#used in slave node to install jdk and hadoop as well as path
echo "------欢迎来到slave节点,安装jdk+hadoop:$0-----"
#1.安装jdk
if [ ! -d /usr/lib/jdk ];then
sudo mkdir /usr/lib/jdk
fi
if [ $? -eq 0];then
echo "mkdir success!"
else
echo "mkdir failure!"
fi
sudo cp ~/下载/jdk-8u131-linux-x64.tar.gz /usr/lib/jdk
cd /usr/lib/jdk
sudo tar -xvf jdk-8u131-linux-x64.tar.gz
if [ $? -eq 0 ];then
echo "解压JDK包成功!"
else
echo "解压失败!请查找原因!"
fi
#2.追加环境变量配置文件到.bashrc
cat ~/下载/environment.sh >> ~/.bashrc
if [ $? -eq 0 ];then
echo "环境变量配置成功!"
else
echo "环境变量配置失败!请查找原因!"
fi
#3.检验是否安装成功
java -version
if [ $? -eq 0 ];then
echo "java install成功!"
else
echo "java install失败!请查找原因!"
fi
#4.安装hadoop
cd ~/下载
sudo tar -zxf hadoop-2.7.3.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./hadoop-2.7.3/ ./hadoop
sudo chown -R hadoop:hadoop ./hadoop
#5.检查hadoop是否可用
cd /usr/local/hadoop/bin
hadoop version
if [ $? -eq 0 ];then
echo "hadoop install成功!"
else
echo "hadoop install失败!请查找原因!"
fi
step2:
至此,hadoop已经安装成功,我们需要对配置文件进行配置,现在首先ssh到master0节点,然后在master0节点之上进行配置文件的更改,再压缩hadoop压缩包并发送到其他四个节点机器上,在依次进入其余四台机器上运行一个shell脚本并安装该配置文件。
auto_3.sh
#!/bin/bash
#author niumeng
# hadoop 配置文件,我们xshell或者ssh到一台master上,bash该文件
echo "----------欢迎来到hadoop配置文件脚本:$0----------"
#1.slaves文件配置
#用slave.sh文件直接覆盖原文件
cat ~/slave.sh > /usr/local/hadoop/etc/hadoop/slaves
if [ $? -eq 0 ];then
echo "success!"
else
echo "failure!please check out your shell!"
fi
# 2. core-site.xml
# 删除最后两行configuration
sed 'N;$!P;$!D;$d' /usr/local/hadoop/etc/hadoop/core-site.xml
if [ $? -eq 0 ];then
echo "success!"
else
echo "failure!please check out your shell!"
fi
# 追加配置文件到末尾
# 首先取出机器名,赋值给变量machinename
while read line
do
machinename="$line"
done</etc/hostname
echo "机器名为:$machinename"
# 使用here document 来追加
cat << EOF >> core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://$machinename:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
EOF
if [ $? -eq 0 ];then
echo "cat core-site success!"
else
echo "cat core-site failure!please check out your shell!"
fi
# 3. hdfs-site.xml
# 删除最后两行configuration
sed 'N;$!P;$!D;$d' /usr/local/hadoop/etc/hadoop/hdfs-site.xml
if [ $? -eq 0 ];then
echo "success!"
else
echo "failure!please check out your shell!"
fi
# 追加配置文件到末尾
cat << EOF >> hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>$machinename:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
EOF
if [ $? -eq 0 ];then
echo "cat hdfs-site.xml success!"
else
echo "cat hdfs-site.xml failure!please check out your shell!"
fi
#4.mapred-site.xml
# 重命名 默认文件名问mapred-site.xml.template
if [ -f mapred-site.xml.template ];then
mv mapred-site.xml.template mapred-site.xml
echo "change name successfully!"
fi
# 删除最后两行configuration
sed 'N;$!P;$!D;$d' /usr/local/hadoop/etc/hadoop/mapred-site.xml
if [ $? -eq 0 ];then
echo "success!"
else
echo "failure!please check out your shell!"
fi
# 追加配置文件到末尾
cat << EOF >> mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>$machinename:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>$machinename:19888</value>
</property>
</configuration>
EOF
if [ $? -eq 0 ];then
echo "cat mapred-site.xml success!"
else
echo "cat mapred-site.xml failure!please check out your shell!"
fi
#5.yarn.site.xml
# 删除最后两行configuration
sed 'N;$!P;$!D;$d' /usr/local/hadoop/etc/hadoop/yarn-site.xml
if [ $? -eq 0 ];then
echo "success!"
else
echo "failure!please check out your shell!"
fi
# 追加配置文件到末尾
cat << EOF >> yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>$machinename</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
EOF
if [ $? -eq 0 ];then
echo "cat yarn-site.xml success!"
else
echo "cat yarn-site.xml failure!please check out your shell!"
fi
echo "until now we have already finished the configuration of hadoop files :)"
# end 将master节点上的/user/local/hadoop文件夹复制到各个节点上
# 如果跑过分布式,先删除临时文件
if [ -f /usr/local/hadoop/tmp ];then
sudo rm -rf ./tmp
sudo rm -rf ./logs/*
echo "delete successfully"
fi
tar -zcf ~/hadoop.master.tar.gz /usr/local/hadoop
cd ~
user=hadoop
x=1;
while [ $x -eq 1]
do
# 输入复制节点的信息
echo "请输入您要复制文件的slave节点ip地址:"
read remote_slave_ip
echo "请输入您要复制文件的slave节点密码:"
read remote_pwd
# 先压缩再复制,把hadoop文件夹复制到~/
scp ./hadoop.master.tar.gz $user@$remote_slave_ip:/home/hadoop
if [ $? -eq 0 ];then
echo "scp tar.gz successfully"
else
echo "scp tar.gz failure!please check out !"
fi
#把节点使用脚本放到下载中
scp ~/slave_use_3.sh $user@remote_slave_ip:/home/hadoop/下载
if [ $? -eq 0 ];then
echo "scp slave_use_3.sh successfully"
else
echo "scp slave_use_3.sh failure!please check out !"
fi
echo "是否还有下一台slave机器需要拷贝文件?yes:1/no:0"
read $x
done
echo "恭喜您已经成功配置好了所有hadoop文件并给slave节点安装成功!HAVE A NICE DAY:)"
slave.sh
注意:有几个slave节点都要添加进去
slave2
思考:如何不用这个.sh脚本,直接添加进去?
至此,master0机器上的已经配置好的hadoop文件夹已经打包好并传送给其余节点了,现在我们需要ssh每台机器上并解压该压缩包
slave_use_3.sh
#!/bin/bash
#author niumeng
# 配置hadoop文件完成之后需要把压缩包传送给各个slave节点,此脚本为在各个节点之上解压压缩包的文件
echo "------------欢迎来到slave节点配置hadoop文件的脚本:$0---------"
# 删除旧文件(如果存在)
if [ ! -d /usr/local/hadoop]
sudo rm -r /usr/local/hadoop
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop:hadoop /usr/local/hadoop
if [ $? -eq 0 ];then
echo "tar success ! "
else
echo "tar failure! "
fi














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









