最近在学习Python,顺便写一个爬取网页中图片的程序练练手。
主要分为两个过程:
第一,从给定域名的网页中爬取图片的链接
第二,读取链接对应的图片,保存到本地
第一个过程需要导入utllib包,在python2.7环境下使用 import urllib2 即可
在python3.X 之后的版本中,由于没有了urllib2模块,所以导入的是 import urllib.request
在这里,我的环境是 python 2.7
- import urllib2
- req = urllib2.urlopen('https://www.nuomi.com/?cid=002540')
- buf = req.read()
三行语句即可将网页的源代码输出到buf对象,然后可以用print buf查看网页的内容
- import re
- listurl = re.findall(r'http:.+\.jpg',buf)
- print listurl
之后就是利用正则表达式匹配图片格式的链接,将链接存到list中
最后就是将list中的链接读取出来,将图片保存到本地即可。
源代码:
- import urllib2
- req = urllib2.urlopen('https://www.nuomi.com/?cid=002540')
- buf = req.read()
-
- import re
- listurl = re.findall(r'http:.+\.jpg',buf)
- print listurl
-
- i = 0
- for url in listurl:
- f = open(str(i)+'.jpg',"wb")
- req = urllib2.urlopen(url)
- buf = req.read()
- f.write(buf)
- i = i + 1
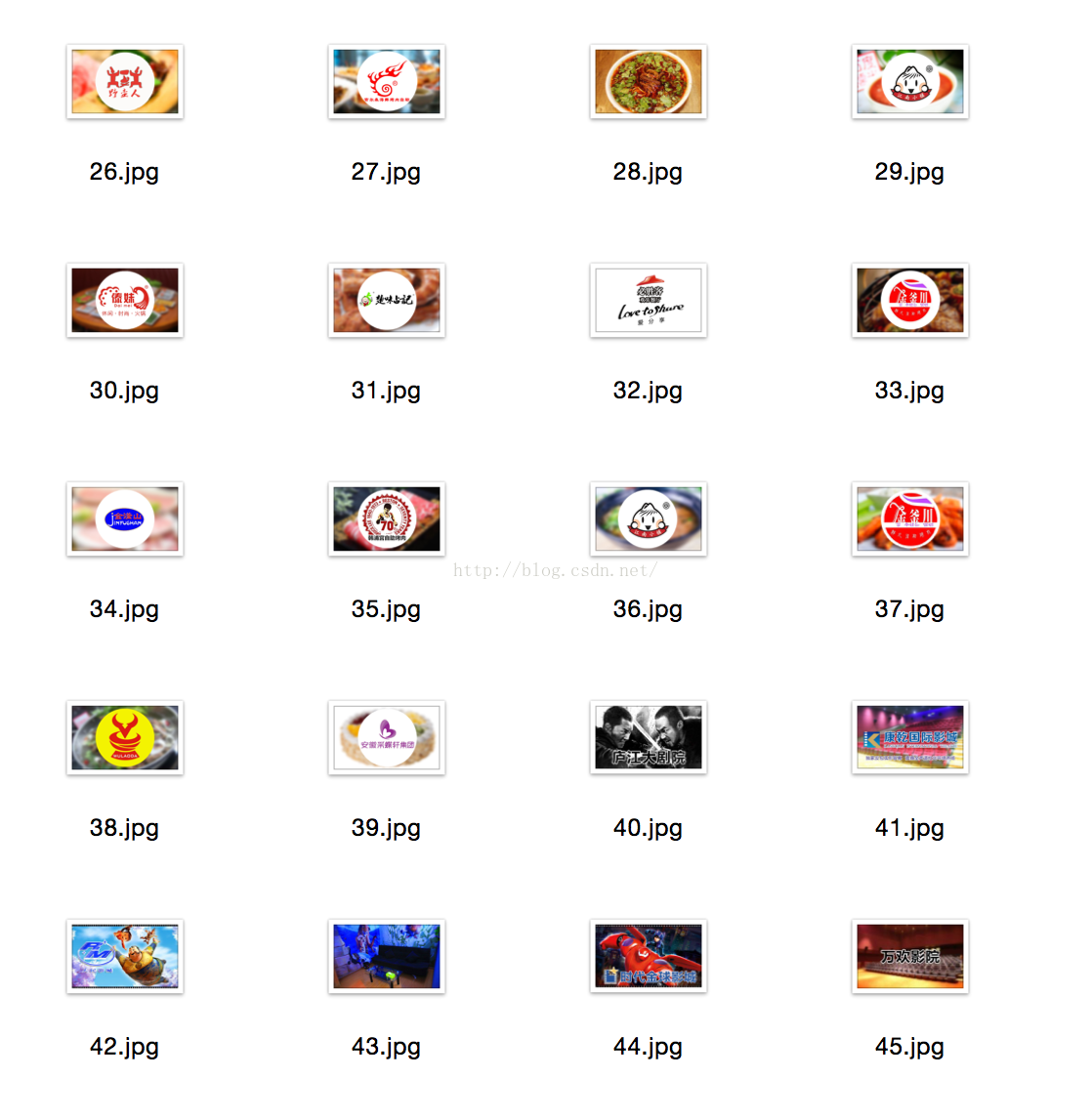
在这里,我爬取的是 百度糯米网上的图片,成功保存到当前目录。























 5175
5175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









