







上下文词表示和预训练
主要内容
- 词表示上的映射
- Pre-ELMo 和 ELMO
- ULMfit 和 onward
- Transformer架构
- bert
一、词表示上的映射
现在为止,我们基本上可以说我们有一个词向量的表示了:word2vec,glove,fastText
预训练词向量:
模型使用了预训练词向量之后,得分得到了提升:
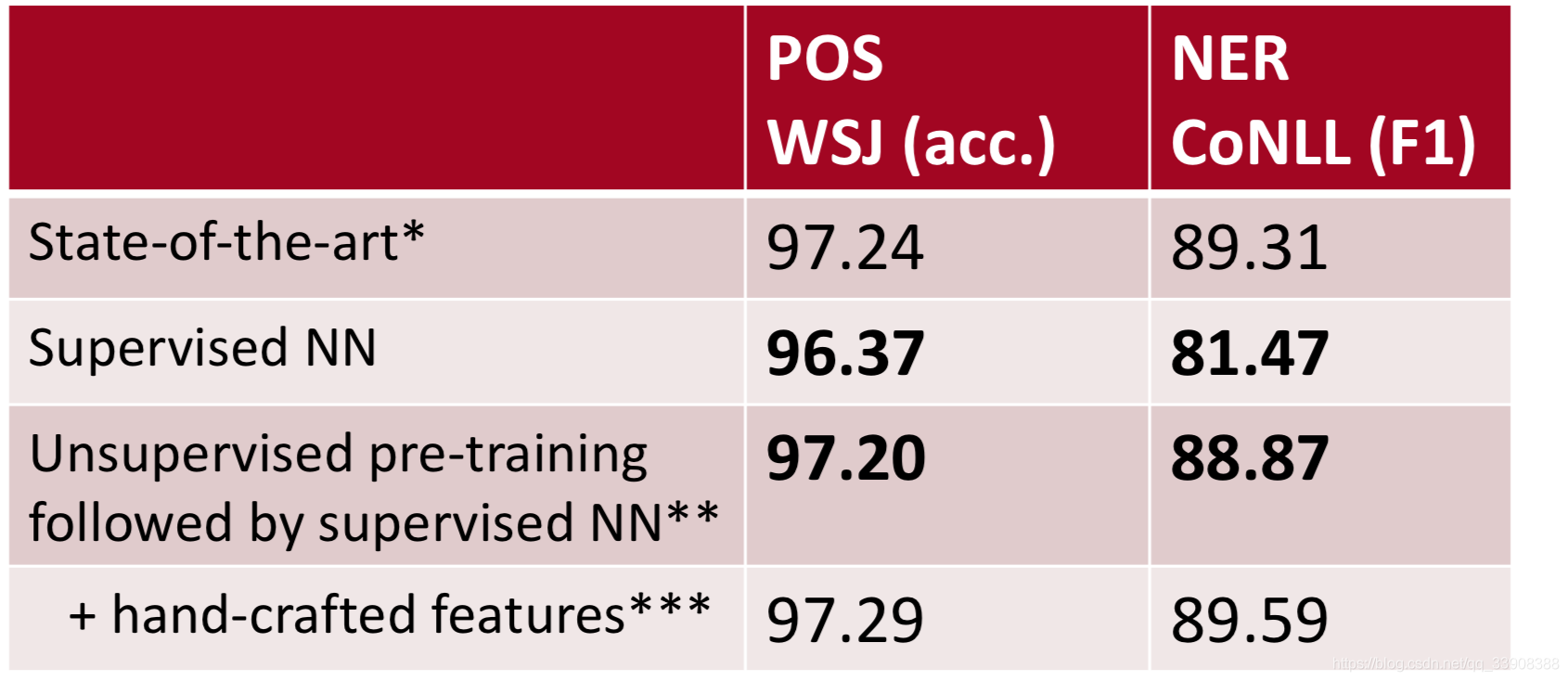
预训练词向量
可以开始的时候给单词一个随机词向量,然后再训练它们。
在大多数情况下,使用预训练的词向量是有用的,因为我们可以在更多的数据上把它们训练成更多的单词。
对于不在词汇表中的单词:
简单和普遍的解决办法:
在训练期间,词汇表是:出现次数>=5次的单词和<unk>的并集
把所有出现次数<5的单词映射到<unk>上,为它训练一个词向量
在运行时,使用<unk>标记出现在词汇表之外的单词出现时
这样的解决方案存在的问题:
没有办法区分不同的<unk>单词,不管是定义还是意思
解决方案:使用上节课学过的字符集模型,但是难度有点大
在问答系统中,让单词能正确的匹配上非常重要
两种可以尝试的办法:
1、直接使用<unk>表示没有在词汇表中出现的单词
2、给它分配一个随机向量
第2种方法更为有效些
一个单词的表示
到现在为止,我们已经有了单词的表示方法:word2vec,glove,fastText
这些方法有两个问题:
无论上下文如何变化,它们的词向量表示都是一样的
一个单词只有一个词向量表示,但是单词有不同的方面,包括语义、语法行为等
2003年开始在CoNLL上的命名实体识别
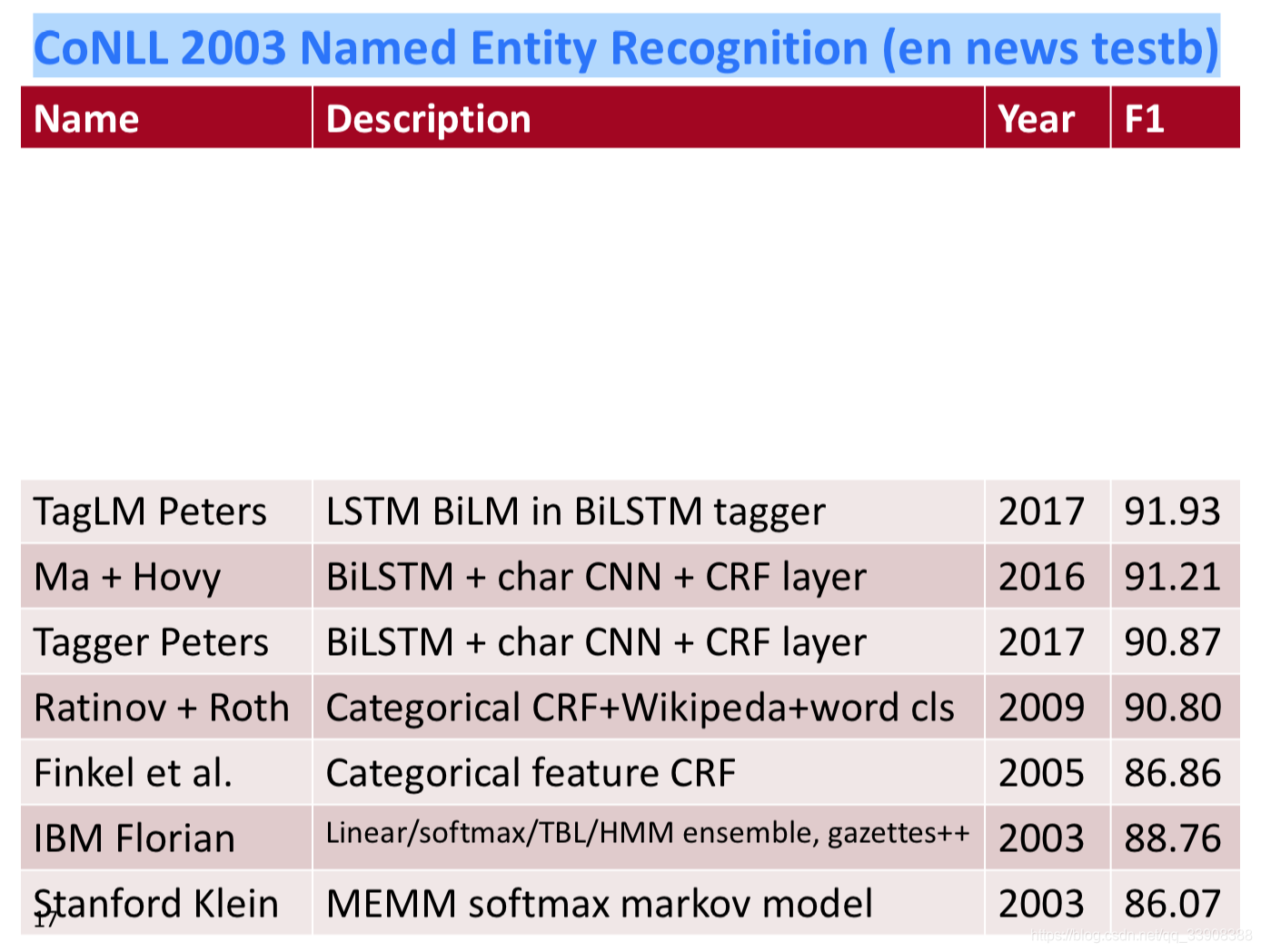
Peters et al. (2017): TagLM – “Pre-ELMo”
在80亿的训练单词上训练的语言模型
语言模型观察:
在监督数据上训练的语言模型是没有用的
一个双向的语言模型只有在前向的时候有用,大约0.2
一个巨大的语言模型设计仅仅对小模型游泳,大约0.3
双向LSTM的观察:
仅仅使用LSTM嵌入预测效果没有很好:F1得分是88.17
McCann et al. 2017: CoVe
使用一个训练序列模型来给其他NLP模型提供上下文
想法:机器翻译意味着能保存信息,可能这是一个很好的目标?
使用一个双层的的双向LSTM作为带有序列到序列+注意力机制的编码器作为一个上下文的提供者
所得到的凹矢量在各种任务中都优于glove矢量
但是,结果并不像这些幻灯片中描述的更简单的NLM训练那样强大,所以似乎被抛弃了
Peters et al. (2018): ELMo: Embeddings from Language Models
通过长的文本而不是窗口文本学习单词信息
使用一个深度的LSTM使用它在预测期间的所有层
使用了两层双向LSTM
使用CNN来构建最初的词表示
使用4096个维度的隐层层的LSTM和512维度的输出来作为下一个阶段的输入
使用一个残差网络














 831
831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









