




 本文详细介绍了支持向量机(SVM)的基本概念,包括线性可分、线性不可分和支持向量机的模型。SVM通过最大化间隔来寻找最优分类超平面,当样本线性不可分时,利用核函数转换到高维空间实现非线性分类。此外,还讨论了软间隔最大化和拉格朗日乘子法在处理线性不可分样本和约束优化问题中的应用。SVM的优势在于精确度高、泛化能力强,但也存在计算复杂度高和核函数选择的挑战。最后,简要提到了SVM的Python实现。
本文详细介绍了支持向量机(SVM)的基本概念,包括线性可分、线性不可分和支持向量机的模型。SVM通过最大化间隔来寻找最优分类超平面,当样本线性不可分时,利用核函数转换到高维空间实现非线性分类。此外,还讨论了软间隔最大化和拉格朗日乘子法在处理线性不可分样本和约束优化问题中的应用。SVM的优势在于精确度高、泛化能力强,但也存在计算复杂度高和核函数选择的挑战。最后,简要提到了SVM的Python实现。
一、简介
支持向量机(support vector machines)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。由简至繁的模型包括:
-
当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机;
-
当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机;
-
当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机;
二、线性可分支持向量机
给定训练样本集D=(x1,y1),(x2,y2),⋯,(xm,ym),其中yi∈{−1,+1}, 分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开。

图1 存在多个超平面将两类训练样本分开
直观看上去,能将训练样本分开的划分超平面有很多,但应该去找位于两类训练样本“正中间”的划分超平面,即图1中红色的那条,因为该划分超平面对训练样本局部扰动的“容忍”性最好,例如,由于训练集的局限性或者噪声的因素,训练集外的样本可能比图1中的训练样本更接近两个类的分隔界,这将使许多划分超平面出现错误。而红色超平面的影响最小,简言之,这个划分超平面所产生的结果是鲁棒性的。
那什么是线性可分呢?
如果一个线性函数能够将样本分开,称这些数据样本是线性可分的。那么什么是线性函数呢?其实很简单,在二维空间中就是一条直线,在三维空间中就是一个平面,以此类推,如果不考虑空间维数,这样的线性函数统称为超平面。我们看一个简单的二维空间的例子,O代表正类,X代表负类,样本是线性可分的,但是很显然不只有这一条直线可以将样本分开,而是有无数条,我们所说的线性可分支持向量机就对应着能将数据正确划分并且间隔最大的直线。
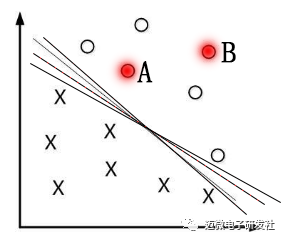
图2 划分并且间隔最大的直线
那么我们考虑第一个问题,为什么要间隔最大呢?一般来说,一个点距离分离超平面的远近可以表示分类预测的确信度,如图中的A B两个样本点,B点被预测为正类的确信度要大于A点,所以SVM的目标是寻找一个超平面,使得离超平面较近的异类点之间能有更大的间隔,即不必考虑所有样本点,只需让求得的超平面使得离它近的点间隔最大。
接下来考虑第二个问题,怎么计算间隔?只有计算出了间隔,才能使得间隔最大化。在样本空间中,划分超平面可通过如下线性方程来描述:

其中w为法向量,决定了超平面的方向,b为位移量,决定了超平面与原点的距离。假设超平面能将训练样本正确地分类,即对于训练样本(xi,yi)(xi,yi),满足以下公式:
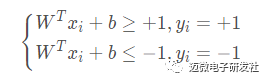
该公式被称为最大间隔假设,yi=+1 表示样本为正样本,yi=−1 表示样本为负样本,式子前面选择大于等于+1,小于等于-1只是为了计算方便,原则上可以是任意常数,但无论是多少,都可以通过对 w 的变换使其为 +1 和 -1 。实际上该公式等价于:
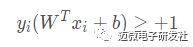
如图3所示,距离超平面最近的这几个样本点满足yi(W^Txi+b)=1,它们被称为“支持向量” 。虚线称为边界,两条虚线间的距离称为间隔(margin)。
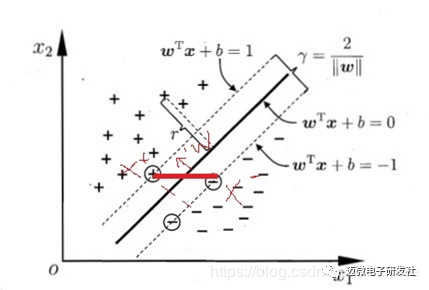
图3 支持向量与间隔
关于间隔的计算:它就等于两个异类支持向量的差在 W方向上的投影 ,W方向是指图3所示实线的法线方向。
即:
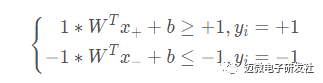
进而可以推出:
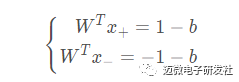
故有:
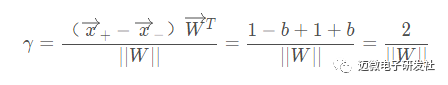
至此,我们求得了间隔,SVM的思想是使得间隔最大化,也就是:
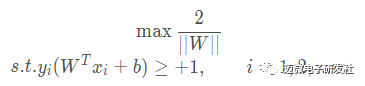
显然,最大化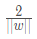 相当于最小化 ||W||,为了计算方便,将公式转化成如下公式,它即为支持向量机的基本型:
相当于最小化 ||W||,为了计算方便,将公式转化成如下公式,它即为支持向量机的基本型:
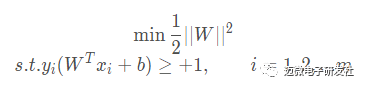
这里解释一下为什么用 ||W||^2
由约束条件可知将不会存在错误分类的样本,即不存在欠拟合的问题;那么,上式的优化目标可进一步解释为“最小化1/2*||W||^2 ”,则相当于寻找“最不可能过拟合的分类超平面”,为了防止过拟合引入了正则化,即在最小化目标函数中加入分类器的所有参数的模值的平方(不含位移项b)。
https://blog.csdn.net/Charmve/article/details/103950571
该基本型是一个凸二次规划问题,可以采用拉格朗日乘子法对其对偶问题求解求解,拉格朗日函数:
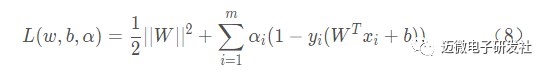
对W,b求导可得:
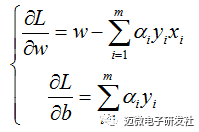
令其分别为0,可得:

将其带入拉格朗日函数(8)中,可得:

原问题就转换为如下关于α的问题:

解出α之后,根据公式(9)可以求得w, 进而求得b,可以得到模型:

该过程的KTT条件为;
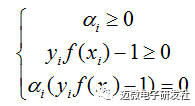
我们分析一下,对于任意的训练样本 (xi,yi),
-
若 αi=0αi=0,则其不会在公式(13)中的求和项中出现,也就是说,它不影响模型的训练;
-
若 αi>0αi>0,则yif(xi)−1=0yif(xi)−1=0,也就是 yif(xi)=1yif(xi)=1,即该样本一定在边界上,是一个支持向量。
这里显示出了支持向量机的重要特征:当训练完成后,大部分样本都不需要保留,最终模型只与支持向量有关。
三、非线性支持向量机和核函数
对于非线性问题,线性可分支持向量机并不能有效解决,要使用非线性模型才能很好地分类。先看一个例子,如下图,很显然使用直线并不能将两类样本分开,但是可以使用一条椭圆曲线(非线性模型)将它们分开。非线性问题往往不好求解,所以希望能用解线性分类问题的方法求解,因此可以采用非线性变换,将非线性问题变换成线性问题。
对于这样的问题,可以将训练样本从原始空间映射到一个更高维的空间,使得样本在这个空间中线性可分,如果原始空间维数是有限的,即属性是有限的,那么一定存在一个高维特征空间使样本可分。令ϕ(x)表示将 x 映射后的特征向量,于是在特征空间中,划分超平面所对应的的模型可表示为:

于是有最小化函数:

其对偶问题为:
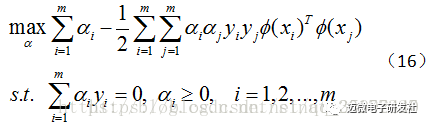
若要对公式(16)求解,会涉及到计算ϕ(xi)Tϕ(xj,这是样本 xi 和 xj映射到特征空间之后的内积,由于特征空间的维数可能很高,甚至是无穷维,因此直接计算ϕ(xi)Tϕ(xj)通常是困难的,于是想到这样一个函数:
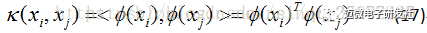
即 xi和 xj在特征空间中的内积等于他们在原始样本空间中通过函数 κ(xi,xj)计算的函数值,于是公式(16)写成如下:

求解后得到:
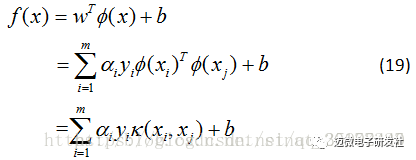
这里的函数 κ(xi,xj)就是核函数,在实际应用中,通常人们会从一些常用的核函数里选择(根据样本数据的不同,选择不同的参数,实际上就得到了不同的核函数)

四、线性支持向量机(软间隔支持向量机)与松弛变量
4.1 线性支持向量机
在前面的讨论中,我们假设训练样本在样本空间或者特征空间中是线性可分的,但在现实任务中往往很难确定合适的核函数使训练集在特征空间中线性可分,退一步说,即使找到了这样的核函数使得样本在特征空间中线性可分,也很难判断是不是由于过拟合造成。
线性不可分意味着某些样本点 (xi,yi) 不能满足间隔大于等于1的条件,样本点落在超平面与边界之间。为解决这一问题,可以对每个样本点引入一个松弛变量 ξi≥0,使得间隔加上松弛变量大于等于1,这样约束条件变为:
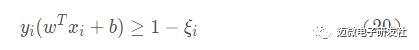
同时,对于每一个松弛变量ξi≥0,支付一个代价 ξi≥0,目标函数变为:

其中 C>0为惩罚参数,C值大时对误分类的惩罚增大, C值小时对误分类的惩罚减小,公式(21)包含两层含义:使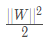 尽量小即间隔尽量大,同时使误分类点的个数尽量小,C是调和两者的系数。有了公式(21),可以和线性可分支持向量机一样考虑线性支持向量机的学习过程,此时,线性支持向量机的学习问题变成如下凸二次规划问题的求解(原始问题):
尽量小即间隔尽量大,同时使误分类点的个数尽量小,C是调和两者的系数。有了公式(21),可以和线性可分支持向量机一样考虑线性支持向量机的学习过程,此时,线性支持向量机的学习问题变成如下凸二次规划问题的求解(原始问题):
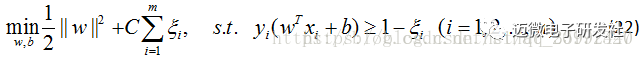
4.2 对偶问题
其对偶问题,与线性可分支持向量机的对偶问题解法一致,公式(22)的拉格朗日函数为:
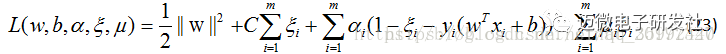
其中 αi≥0,μi≥0是拉格朗日乘子。
令L(w,b,α,ξ,μ)对w,b,ξ的偏导数为0可得如下:
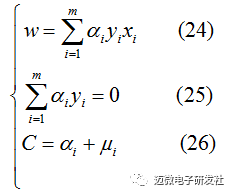
将公式(24)(25)(26)代入公式(23)得对偶问题:
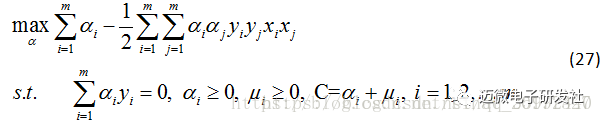
上述过程的KTT条件如下:
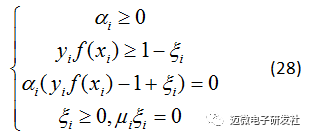
我们分析一下,对于任意的训练样本 (xi,yi),总有αi=0或者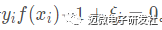 。
。
-
(1)若 αi=0 ,则该样本不出现在公式(13)中,不影响模型。
-
(2)若 αi>0,必有
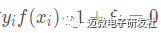 ,即
,即 ,此时该样本为支持向量。
,此时该样本为支持向量。
由于C=αi+μi(公式26)
-
(1)若 αi<C, 则必有μi>0 ,根据公式(28)知 ξi=0 ,即该样本恰好落在最大间隔的边界上;
-
(2)若 αi=C ,则 μi=0,此时若 ξi≤1 则该样本在最大间隔内部,若 ξi>1 则样本分类错误。
五、拉格朗日乘子法
在求取有约束条件的优化问题时,拉格朗日乘子法(Lagrange Multiplier) 和KKT条件是非常重要的两个求取方法,对于等式约束的优化问题,可以应用拉格朗日乘子法去求取最优值;如果含有不等式约束,可以应用KKT条件去求取。当然,这两个方法求得的结果只是必要条件,只有当是凸函数的情况下,才能保证是充分必要条件。KKT条件是拉格朗日乘子法的泛化。之前学习的时候,只知道直接应用两个方法,但是却不知道为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够起作用,为什么要这样去求取最优值呢?
首先把什么是拉格朗日乘子法(Lagrange Multiplier) 和KKT条件叙述一下;然后开始分别谈谈为什么要这样求最优值。
5.1 拉格朗日乘子法(Lagrange Multiplier) 和KKT条件
通常我们需要求解的最优化问题有如下几类:
(i) 无约束优化问题,可以写为:

(ii) 有等式约束的优化问题,可以写为:
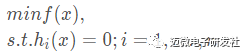
(iii) 有不等式约束的优化问题,可以写为:
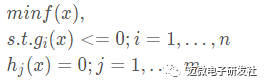
对于第(i)类的优化问题,常常使用的方法就是Fermat定理,即使用求取f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解。对于第(ii)类的优化问题,常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式约束h_i(x)用一个系数与f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。对于第(iii)类的优化问题,常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
5.1.1 拉格朗日乘子法(Lagrange Multiplier)
对于等式约束,我们可以通过一个拉格朗日系数a 把等式约束和目标函数组合成为一个式子L(a, x) = f(x) + a*h(x), 这里把a和h(x)视为向量形式,a是横向量,h(x)为列向量。然后求取最优值,可以通过对L(a,x)对各个参数求导取零,联立等式进行求取。
5.1.2 KKT条件
对于含有不等式约束的优化问题,如何求取最优值呢?常用的方法是KKT条件,同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子L(a, b, x)= f(x) + ag(x)+bh(x),KKT条件是说最优值必须满足以下条件:
-
L(a, b, x)对x求导为零;
-
h(x) =0;
-
a*g(x) = 0;
求取这三个等式之后就能得到候选最优值。其中第三个式子非常有趣,因为g(x)<=0,如果要满足这个等式,必须a=0或者g(x)=0. 这是SVM的很多重要性质的来源,如支持向量的概念。
5.2 不同问题求解
5.2.1 有不等式约束的优化问题
假设我们求解的不等式约束的优化问题如下:
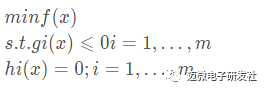
那么根据前面讲解的拉格朗日函数,我们可以得到如下的公式:
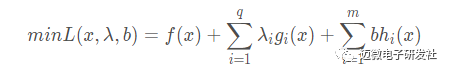
如果我们对这样的公式求最小值会出现什么问题呢?由于没有任何的限制条件,所以λg(x)的值可能为正也可能为负,这样在无形中就增加了我们的验证难度,所以这里我们可以将λiλiλi调整为最大的正值,使λg(x)的值趋近于负无穷,使由于x变化导致的f(x)的变化基本上不会影响λg(x)的变化,这样我们就可以忽略后半部分λg(x)的值,而只关注前边f(x)的部分就可以了。这样就延伸出如下的问题:
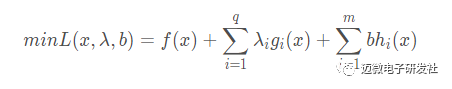
即:求解λ最大值,使λg(x)λg(x)λg(x)趋近于负无穷(这个负无穷是相对的,取决于实际的情况)的值。
这样我们的问题就转变成了如下的内容:
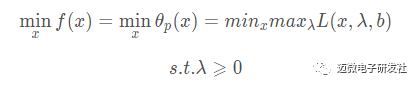
如果我们直接求解minxθp(x)minxθp(x)的话,不好求解,这里有两个参数,并且存在一个不等式约束,这个求解过程是比较复杂的。要求解这个过程话,我们需要先了解下拉格朗日对偶的问题。
首先思考一下,我们考虑这个公式的对偶面,即:先在λ固定的情况下,求解关于x的最小值,然后再针对λ求最大值。
如果我们只是简单的调换下求极值的顺序,那么会产生如下的结果:

由于我们需要的是两个等式相等,那么我们就需要寻找能够使两者相等的条件,这里呢我们就需要引入KKT条件了,KKT条件有如下几条:
-
∇L(x,λ,b)∇x的值为0,即拉格朗日函数对x求导的值为0。求极值的必须要求。
-
bi≠0。根据拉格朗日算子法,那么算子系数b的话就不能够为0(定义中的东西)。
-
λ⩾0。这个条件已经在前边讲过了,需要寻找不等式值的负无穷,使我们能够将求值过程简化。
-
λg(x)=0。
-
hi(x)=0;i=1,…,q。这个是前提条件。
-
gi(x)⩽0;i=1,…,m。这个也是前提条件。
5.2.2 拉格朗日对偶问题
如果我们求解一下不等式的优化问题:
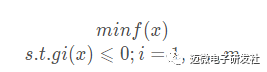
如果我们用KKT条件话会生成如下的函数:

这个函数是不是有点熟悉,这个和我们在上面讲解的拉格朗日乘子法很想像,但是不同的是限制条件——拉格朗日算子法的限制条件是λ≠0,而KKT条件的限制条件是:λ⩾0。KKT条件实际上是对拉格朗日乘子法的泛化。
接下来将为大家展示一个基于KKT条件生成的函数(满足KTT条件)产生的一个证明过程,如下所示:
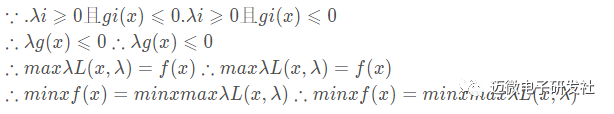
这里我们看一下另外一个等式:
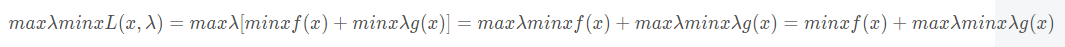
这里讲解一下上(1)式的变化过程,对于f(x)来说,变量λ对于f(x)来说是无效的,所以我们可以进行这种变换。
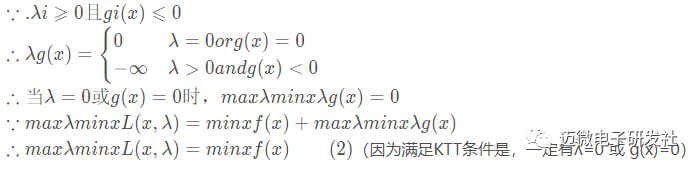
据此根据(1)(2),我们可以得到如下的公式:
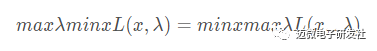
六、支持向量机的应用及Python实现
这部分 追寻的鹿 的分享很好,墙裂推荐机器学习之支持向量机(四):支持向量机的Python语言实现https://www.cnblogs.com/pursued-deer/p/7892342.html。
总结
总的来说,在集成算法和神经网络风靡之前,SVM 基本上是最好的分类算法,但即使在今天,它依然占有较高的地位。
SVM 的主要优点有:
1)引入最大间隔,分类精确度高
2)在样本量较小时,也能准确的分类,并且具有不错的泛化能力
3)引入核函数,能轻松的解决非线性问题
4)能解决高维特征的分类、回归问题,即使特征维度大于样本的数据,也能有很好的表现
SVM 的主要缺点有:
1)在样本量非常大时,核函数中內积的计算,求解拉格朗日乘子α 值的计算都是和样本个数有关的,会导致在求解模型时的计算量过大
2)核函数的选择通常没有明确的指导,有时候难以选择一个合适的核函数,而且像多项式核函数,需要调试的参数也非常多
3)SVM 对缺失数据敏感 (好像很多算法都对缺失值敏感,对于缺失值,要么在特征工程时处理好,要么使用树模型)。

















 1335
1335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









