







一、solr域的介绍
在solr中域的概念与lucene中域的概念相同,数据库的一条记录或者一个文件的信息就是一个document,数据库记录的字段或者文件的某个属性就是一个Field域,solr中对索引的检索也是对Field的操作。lucene中对域的操作是通过代码,solr对域的管理是通过一个配置文件schema.xml。
solr中域的类型是schema.xml中<fieldType>元素常用的field类型
<!--string 类型 在存储索引时不进行分词 sortMissingLast:设置为true时 没有该filed的数据将排在有该Field的数据后面,忽略请求时的排序规则,默认为false。-->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<!-- boolean 类型只有两个值 true false-->
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<!--用于直接数值搜索,该类型不分词 -->
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/>
<!--用于数值范围搜索,进行分词 通过设置precisionStep的值可以提高检索速度,8是solr的推荐值 -->
<fieldType name="tint" class="solr.TrieIntField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tfloat" class="solr.TrieFloatField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tlong" class="solr.TrieLongField" precisionStep="8" positionIncrementGap="0"/>
<fieldType name="tdouble" class="solr.TrieDoubleField" precisionStep="8" positionIncrementGap="0"/>
<!--日期类型-->
<fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="tdate" class="solr.TrieDateField" precisionStep="6" positionIncrementGap="0"/>
<!--二进制类型-->
<fieldtype name="binary" class="solr.BinaryField"/>
<!--随机数类型-->
<fieldType name="random" class="solr.RandomSortField" indexed="true" />
<!-- text_general 类型 进行分词 -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<!--创建索引时的配置 -->
<analyzer type="index">
<!-- tokenizer 创建索引使用的分词器 -->
<tokenizer class="solr.StandardTokenizerFactory"/>
<!--filter 分词时的过滤器 class="solr.StopFilterFactory" 处理停用词 words:配置停用词-->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- filter 分词时的过滤器 class="solr.LowerCaseFilterFactory" 处理大小写转换问题(将大写转小写)-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<!--查询索引时的配置 -->
<analyzer type="query">
<!-- tokenizer 对查询条件分词时使用的分词器 -->
<tokenizer class="solr.StandardTokenizerFactory"/>
<!--filter 分词时的过滤器 class="solr.StopFilterFactory" 处理停用词 words:配置停用词-->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!--filter 分词时的过滤器 class="solr.SynonymFilterFactory" 处理同义词 synonyms:配置同义词-->
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<!-- filter 分词时的过滤器 class="solr.LowerCaseFilterFactory" 处理大小写转换问题(将大写转小写)-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>solr在操作Field域时需要在schema.xml中定义(根据自己的业务需求自定义)。
<!--name域的名称 type:域的类型 indexed:是否使用该域搜索
stored:是否存储 如果不存储在查询时是查不到该域的 但可以进行搜索
multiValued:是否支持存储多值
-->
<field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/>
<field name="subject" type="text_general" indexed="true" stored="true"/>
<field name="description" type="text_general" indexed="true" stored="true"/>
<field name="comments" type="text_general" indexed="true" stored="true"/>
<field name="author" type="text_general" indexed="true" stored="true"/>
<field name="keywords" type="text_general" indexed="true" stored="true"/>
<field name="category" type="text_general" indexed="true" stored="true"/>
<field name="resourcename" type="text_general" indexed="true" stored="true"/>
<field name="url" type="text_general" indexed="true" stored="true"/>
<field name="content_type" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="last_modified" type="date" indexed="true" stored="true"/>
<field name="links" type="string" indexed="true" stored="true" multiValued="true"/>1、唯一域
<!-- id 域 也叫唯一域 每一个文档必须有唯一域 -->
<uniqueKey>id</uniqueKey><!-- 动态域 *_i:通配符 -->
<dynamicField name="*_i" type="int" indexed="true" stored="true"/>
<dynamicField name="*_is" type="int" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="string" indexed="true" stored="true" multiValued="true"/>3、复制域 copyField 可以将多个Field复制到一个Field中,一便进行统一检索。
<copyField source="title" dest="text"/>a、先创建域
<field name="title" type="text_general" indexed="true" stored="true" multiValued="true"/>
<field name="author" type="text_general" indexed="true" stored="true"/>
<field name="description" type="text_general" indexed="true" stored="true"/>
<field name="keywords" type="text_general" indexed="true" stored="false"/><!--source:源域 dest:目标域 -->
<copyField source="title" dest="keywords"/>
<copyField source="author" dest="keywords"/>
<copyField source="description" dest="keywords"/>二、配置中文分析器
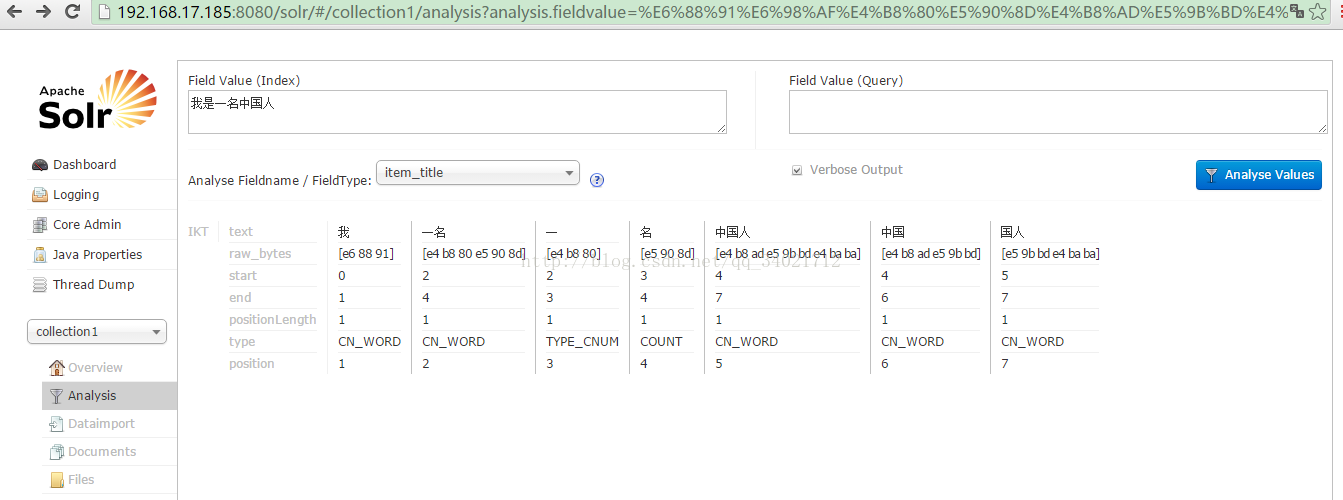
在solr中默认是中文分析器,需要手工配置。配置一个FieldType,在FieldType中指定中文分析器。
1、使用 IK-Analyzer中文分析器 将该分析器文件上传服务器
2、将需要把分析器的jar包(IKAnalyzer2012FF_u1.jar)添加到solr工程中。
[root@localhost IK Analyzer 2012FF_hf1]# cp IKAnalyzer2012FF_u1.jar /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/
3、把IKAnalyzer需要的扩展词典及停用词词典、配置文件复制到solr工程的classpath。
(1) 在usr/local/solr/tomcat/webapps/solr/WEB-INF/目录下创建classes目录 [root@localhost WEB-INF]# mkdir classes
(2)复制文件 [root@localhost IK Analyzer 2012FF_hf1]# cp IKAnalyzer.cfg.xml ext_stopword.dic mydict.dic /usr/local/solr/tomcat/webapps/solr/WEB-INF/classes
ext_stopword.dic:扩展词词典
mydict.dic:停用词词典
注意:扩展词典及停用词词典的字符集必须是utf-8。不能使用windows记事本编辑。
4、配置fieldType。需要在/usr/local/solr/solrhome/collection1/conf/schema.xml中配置。技巧:使用vi、vim跳转到文档开头gg。跳转到文档末尾:G
在文件末尾添加fieldType
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>class="solr.TextField":分词分析器
二、配置业务字段
Solr中的字段必须是先定义后使用。该配置要与我们的实际业务关联。
业务字段判断标准:
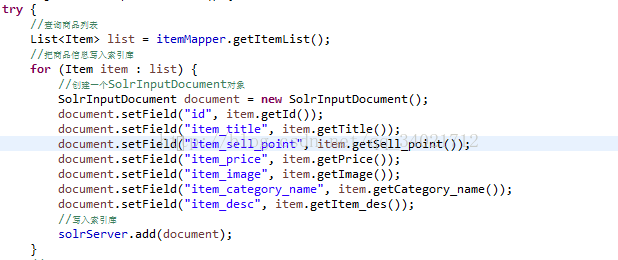
1、在搜索时是否需要在此字段上进行搜索。例如:商品名称、商品的卖点、商品的描述
2、后续的业务是否需要用到此字段。例如:商品id。
本人这次项目需要用到的字段:
1、商品id
2、商品title
3、卖点sell_point
4、价格price
5、商品图片image
6、商品分类名称category_name
7、商品描述item_des
在solrhome/collection1/conf/schema.xml 中添加 Solr中的业务字段:
id——商品id
其他的对应字段创建solr的字段。
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_sell_point" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="long" indexed="true" stored="true"/>
<field name="item_image" type="string" indexed="false" stored="true" />
<field name="item_category_name" type="string" indexed="true" stored="true" />
<field name="item_desc" type="text_ik" indexed="true" stored="false" />
<!-- 创建复制域 将其他域上的搜索关键词都复制到一个域上 是solr对搜所的优化-->
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_sell_point" dest="item_keywords"/>
<copyField source="item_category_name" dest="item_keywords"/>
<copyField source="item_desc" dest="item_keywords"/>
重启tomcat















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









