











📣读完这篇文章里你能收获到
- 为什么很多人认为MongoDB是无模式?
- 文档模型跟传统的关系模型有什么区别?
- 关于MongoDB的模型设计模式,你知道几个?
- MongoDB如何进行表关联?
- 文档模型的设计规范及设计原则
- 文档建模模型设计三部曲
- 1-1关系建模,1-N关系建模,N-N关系建模的建议
- 针对不同的场景提供丰富的设计案例分享
一、JSON 文档模型设计特点
1 为什么人们都说 MongoDB 是无模式?
-
严格来说,MongoDB 同样需要概念/逻辑建模
-
文档模型设计的物理层结构可以和逻辑层类似
-
MongoDB 无模式由来:可以省略物理建模的具体过程
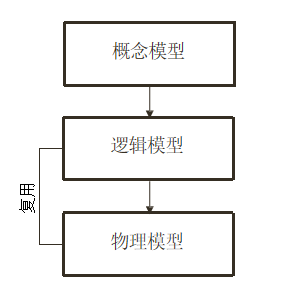
2 文档模型与关系模型有什么区别?
| 关系数据库 | JSON 文档模型 | |
|---|---|---|
| 模型设计层次 | 概念模型、逻辑模型、物理模型 | 概念模型、逻辑模型 |
| 模型实体 | 表 | 集合 |
| 模型属性 | 列 | 字段 |
| 模型关系 | 关联关系,主外键 | 内嵌数组,引用字段 |
3 MongoDB 文档模型设计的三个误区(下述说法均为错误!)
-
1: 不需要模型设计
-
2:MongoDB 应该用一个超级大文档来组织所有数据
-
3:MongoDB 不支持关联或者事务
4 JSON 文档模型的设计规范
- 文档模型设计处于是物理模型设计阶段 (
PDM) - JSON 文档模型通过
内嵌数组或引用字段来表示关系 - 文档模型设计
不遵从第三范式,允许冗余
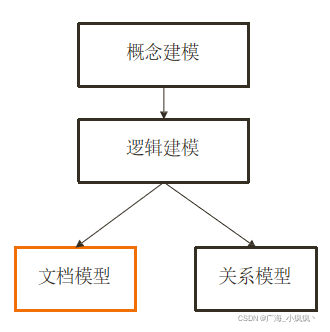
5 JSON 文档模型的设计原则
- 性能
- 易用
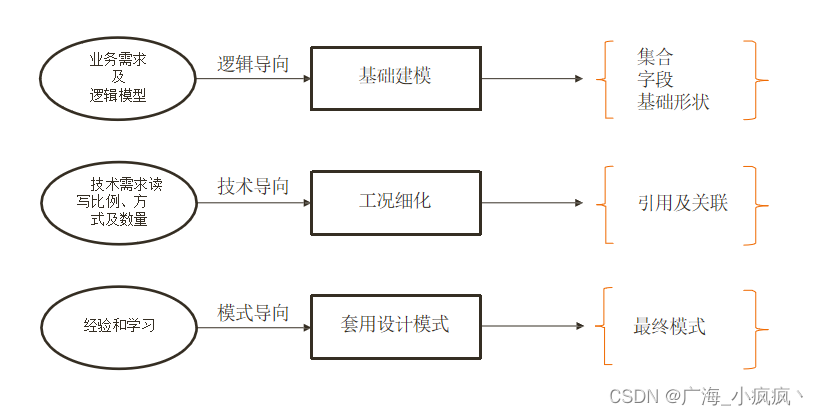
二、MongoDB 文档模型设计三步曲
三、入门!基础模型的快速设计
1 建立基础文档模型
-
根据概念模型或者业务需求推导出逻辑模型 – 找到对象
-
列出实体之间的关系(及基数) - 明确关系
-
套用逻辑设计原则来决定内嵌方式 – 进行建模
-
完成基础模型构建

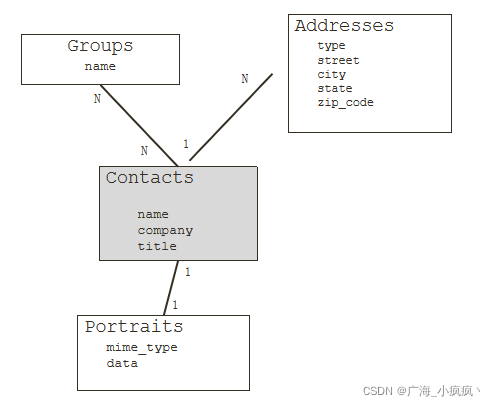
2 实例:联系人管理应用
-
找到对象
Contacts
Groups
Address
Portraits -
明确关系
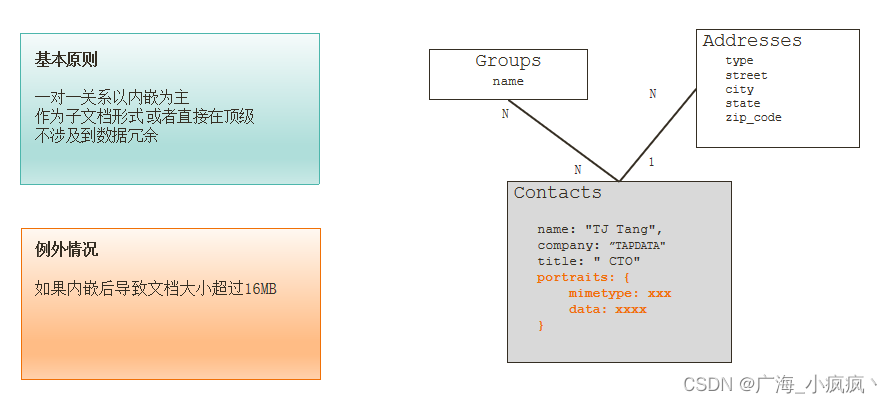
一个联系人有一个头像 (1-1)
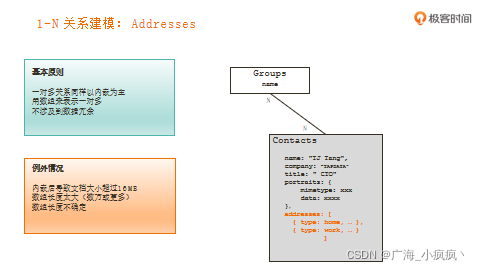
一个联系人可以有多个地址(1-N )
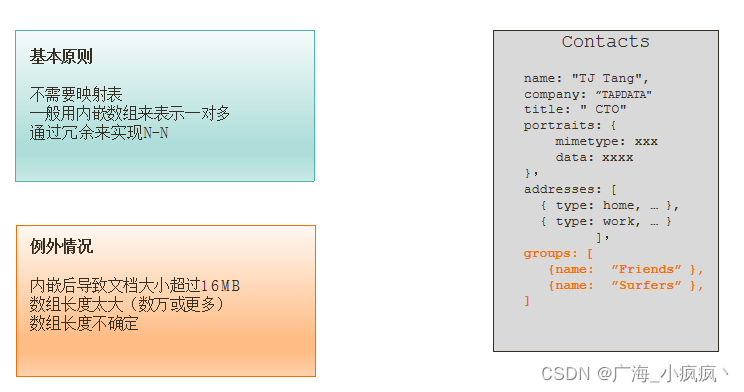
一个联系人可以属于多个组,一个组可以有多个联系人 (N – N)
1-1 关系建模
1-N 关系建模
N-N 关系建模
3 基础建模小结
-
1:9 规则: 大部分时候你会使用内嵌来表示 1-1,1-N,N-N
-
内嵌类似于预先聚合(关联)
-
内嵌后对读操作通常有优势(减少关联)
四、进阶!基础模型的需求细化
- 基于内嵌的文档模型根据业务需求,使用引用来避免性能瓶颈使用冗余来优化访问性能

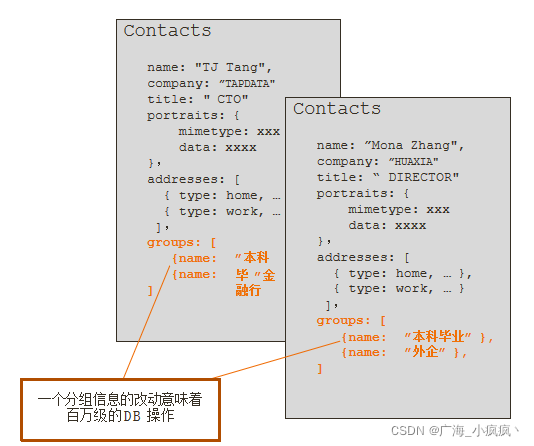
1 联系人分组需求遭遇瓶颈
- 用于客户营销
- 有千万级联系人
- 需要频繁变动分组(group)的信息,如增加分组及修改名称及描述以及营销状态
- 一个分组可以有百万级联系人
2 针对瓶颈设计解决方案
-
Group 使用单独的集合
-
类似于关系型设计
-
用 id 或者唯一键关联
-
使用 $lookup 来提供一次查询多表的能力(类似关联)

3 引用模式下的关联查询

- 查询时使用
aggregate结合$lookup进行联表查询
db.contacts.aggregate([
{
$lookup:
{
from: "groups",
localField: "group_ids",
foreignField: "group_id",
as: "groups"
}
}
])
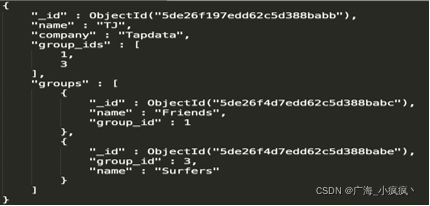
4 什么时候该使用引用方式?
-
内嵌文档太大,数 MB 或者超过 16MB
-
内嵌文档或数组元素会频繁修改
-
内嵌数组元素会持续增长并且没有封顶
5 MongoDB 引用设计的限制
-
MongoDB 对使用引用的集合之间并无主外键检查
-
MongoDB 使用聚合框架的
$lookup来模仿关联查询 -
$lookup只支持left outer join -
$lookup的关联目标(from)不能是分片表
五、成神!MongoDB设计模式案例分享
- 文档模型:无范式、无思维定式、充分发挥想象力
- 设计模式:实战过屡试不爽的设计技巧,快速套用

1 分桶模式
- 背景:数据量大,有规律的分布(如按时间),数据颗粒度小
- 场景描述
- 物联网场景下的海量数据处理 – 飞机监控数据
- 10万架飞机,1年的数据,每架飞机每分钟记录一条

分析:100000 * 365 * 24 * 60 = 52.6B数据量,数据大小大概4000GB,索引大小大概6000GB,一年下来的数据量极其庞大
- 解决方案:分桶设计

分析:由原先模型中的events的对象更改为events数组,每个文档存储60个events也就是一个小时的数据,那么数据量由52.6B降至876M,索引大小由6000GB降至100GB,数据大小由4000GB降至600GB,不管是索引还是数据量都有了质的减少
- 模式小结:分桶
| 场景 | 痛点 | 设计模式方案及优点 |
|---|---|---|
| 时序数据,物联网,智慧城市,智慧交通 | 数据点采集频繁,数据量太多 | 利用文档内嵌数组,将一个时间段的数据聚合到一个文档里。大量减少文档数量,大量减少索引占用空间 |
2 列转行模式
-
背景:大文档,很多字段,很多索引
-
场景描述
- 有很多部电影
- 需要记录每部电影各自在各个国家的最新上映时间
-
原来的数据格式及原来的索引设计

分析:由于需要根据国家去查询电影的上映日期,因此需要设计大量的国家索引
-
解决方案:列转行

-
索引:
db.movies.createIndex({“releases.country”:1, “releases.date”:1})
分析:将国家及日期提取为数组形式,只需要创建一个索引即可
- 模式小结:列转行
| 场景 | 痛点 | 设计模式方案及优点 |
|---|---|---|
| 多语言(多国家)属性、产品属性 ‘color’, ‘size’ … | 文档中有很多类似的字段,会用于组合查询搜索,需要见很多索引 | 转化为数组,一个索引解决所有查询问题 |
3 版本管理模式
- 背景:模型灵活了,如何管理文档不同版本?
- 场景描述
- 有很多个版本,每个版本的字段都有区别
- 查询某个版本或者某个版本的数据以及对这部分数据作统一处理
- 原来的数据格式

分析:由于不同的版本导致MongoDB的collection模型差异过大,容易导致数据的管理失控
- 解决方案: 增加一个版本字段

分析:增加版本字段,可以明确的知道哪部分数据是哪个版本产生的
- 模式小结:版本管理
| 场景 | 痛点 | 设计模式方案及优点 |
|---|---|---|
| 任何有版本衍变的数据库 | 文档模型格式多,无法知道其合理性,升级时候需要更新太多文档 | 增加一个版本号字段,快速过滤掉不需要升级的文档,升级时候对不同版本的文档做不同的处理 |
4 近似计算模式
- 背景:需要统计大量的不重要数据
- 场景描述
- 统计网页点击流量
- 每访问一个页面都会产生一次数据库计数更新操作
- 统计数字准确性并不十分重要
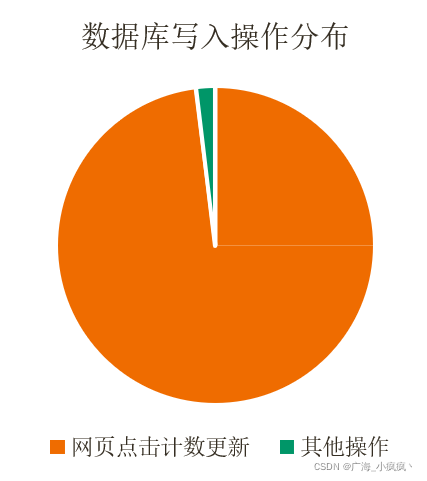
分析:由于点击所需要更新的数据过于频繁,对数据库的写操作造成较大的压力
- 解决方案: 用近似计算,每个10(X)次写一次 Increment by 10(X)
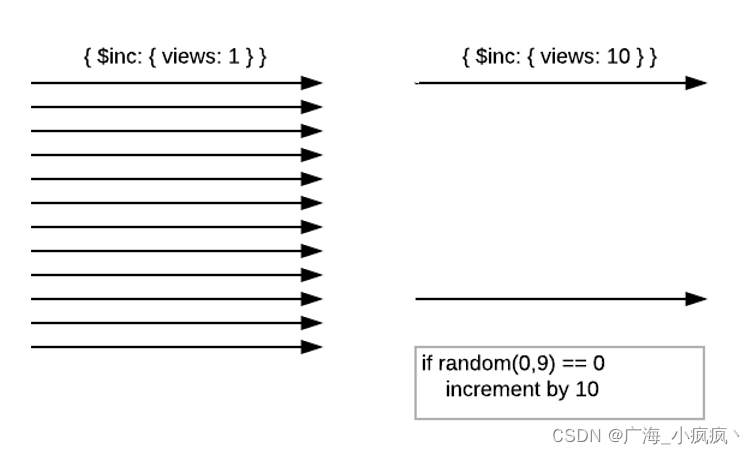
分析:数据近似,数据库的写入压力得以缓解
- 模式小结:近似计算
| 场景 | 痛点 | 设计模式方案及优点 |
|---|---|---|
| 网页计数,各种结果不需要准确的排名 | 写入太频繁,消耗系统资源 | 间隔写入,每隔10次或者100次大量减少写入需求 |
5 预聚合模式
- 背景:各种需要精确统计的场景
- 场景描述
- 热销榜:某个商品今天卖了多少,这个星期卖了多少,这个月卖了多少?
- 电影排行:观影者,场次统计传统解决方案:通过聚合计算
分析:消耗资源多,聚合计算时间长
- 解决方案: 用预聚合字段

分析:模型中直接加入聚合字段,聚合查询速度得以保障
- 模式小结:预聚合
| 场景 | 痛点 | 设计模式方案及优点 |
|---|---|---|
| 准确排名,排行榜 | 统计计算耗时,计算时间长 | 模型中直接增加统计字段,每次更新数据时候同时更新统计值 |

















 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











