







在CBIR中,图像通过其视觉内容(例如颜色,纹理,形状)来索引。
一、实现原理
首先从图像数据库中提取特征并存储它。然后我们计算与查询图像相关的特征。最后,我们检索具有最近特征的图像
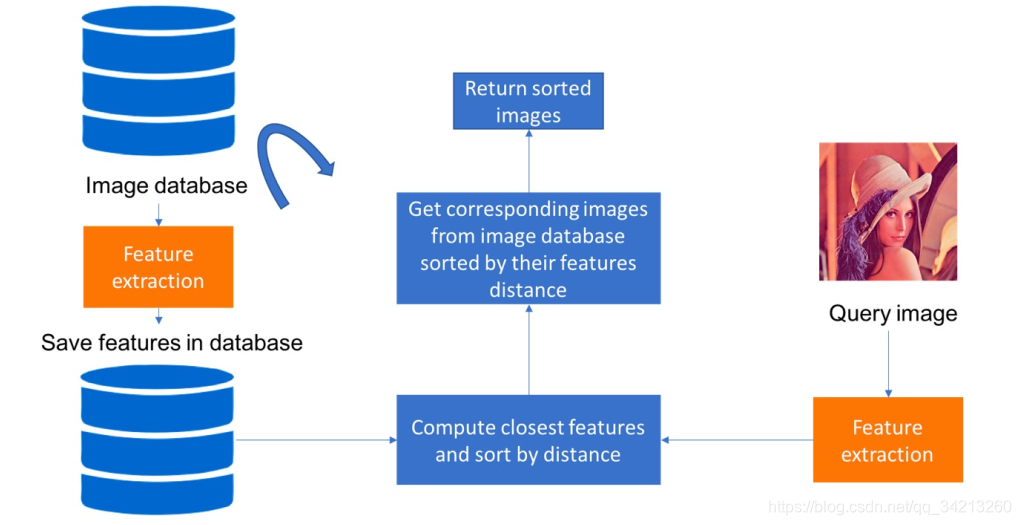
二、 基于内容的图像检索的特征提取
在这篇研究论文中(https://arxiv.org/pdf/1404.1777.pdf),作者证明了为分类目的而训练的卷积神经网络(CNN) 可用于提取图像的“神经代码”。这
些神经代码是用于描述图像的特征。研究表明这种方法在许多数据集.上的表现与最先进的方法一样。这种方法的问题是我们首先需要标记数据来训练神经网络。标签任务可能是昂贵且耗时的。为我们的图像检索任务生成这些“神经代码”的另一种方法是使用无监督的深度学习算法。这是去噪
自动编码器的来源。相关代码可以参见:https://blog.csdn.net/qq_34213260/article/details/106333947.
三、代码实现
import numpy as np
from keras.models import Model
from keras.datasets import mnist
import cv2
from keras.models import load_model
from sklearn.metrics import label_ranking_average_precision_score
import time
print('Loading mnist dataset')
t0 = time.time()
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1)) # adapt this if using `channels_first` image data format
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1)) # adapt this if using `channels_first` image data format
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
t1 = time.time()
print('mnist dataset loaded in: ', t1-t0)
print('Loading model :')
t0 = time.time()
autoencoder = load_model('autoencoder.h5')
encoder = Model(inputs=autoencoder.input, outputs=autoencoder.get_layer('encoder').output)
t1 = time.time()
print('Model loaded in: ', t1-t0)
def retrieve_closest_images(test_element, test_label, n_samples=10):
learned_codes = encoder.predict(x_train) # 提取数据库图像的特征向量
# 转换成一维向量
learned_codes = learned_codes.reshape(learned_codes.shape[0],
learned_codes.shape[1] * learned_codes.shape[2] * learned_codes.shape[3])
test_code = encoder.predict(np.array([test_element]))
test_code = test_code.reshape(test_code.shape[1] * test_code.shape[2] * test_code.shape[3])
distances = []
# 计算输入图像和数据库所有图像的距离
for code in learned_codes:
distance = np.linalg.norm(code - test_code)
distances.append(distance)
# 排序取出距离最小的图像
nb_elements = learned_codes.shape[0]
distances = np.array(distances)
learned_code_index = np.arange(nb_elements)
labels = np.copy(y_train).astype('float32')
labels[labels != test_label] = -1
labels[labels == test_label] = 1
labels[labels == -1] = 0
distance_with_labels = np.stack((distances, labels, learned_code_index), axis=-1)
sorted_distance_with_labels = distance_with_labels[distance_with_labels[:, 0].argsort()]
sorted_distances = 28 - sorted_distance_with_labels[:, 0]
sorted_labels = sorted_distance_with_labels[:, 1]
sorted_indexes = sorted_distance_with_labels[:, 2]
kept_indexes = sorted_indexes[:n_samples]
score = label_ranking_average_precision_score(np.array([sorted_labels[:n_samples]]), np.array([sorted_distances[:n_samples]]))
print("Average precision ranking score for tested element is {}".format(score))
original_image = x_test[0]
cv2.imshow('original_image', original_image)
retrieved_images = x_train[int(kept_indexes[0]), :]
for i in range(1, n_samples):
retrieved_images = np.hstack((retrieved_images, x_train[int(kept_indexes[i]), :]))
cv2.imshow('Results', retrieved_images)
cv2.waitKey(0)
cv2.imwrite('test_results/original_image.jpg', 255 * cv2.resize(original_image, (0,0), fx=3, fy=3))
cv2.imwrite('test_results/retrieved_results.jpg', 255 * cv2.resize(retrieved_images, (0,0), fx=2, fy=2))
# To retrieve closest image
retrieve_closest_images(x_test[0], y_test[0])
打赏
如果对您有帮助,就打赏一下吧O(∩_∩)O
















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









