







文章目录
最近要面阿里云弹性计算和蚂蚁金服风险技术部,也会做AIops,所以复习和学习一下之前实习公司的一些成果,本文基本都来自于公众号《智能运维前沿》,公众号由清华netman实验室和必示科技维护。
根因分析
清华FOCUS:找影响系统性能瓶颈的原因
瓶颈:30%的用户的搜索响应时间大于1秒钟

单维分析的局限性:只简单的分析单维数据很难发现系统真正的性能瓶颈
多维分析:第二列表示该条件下的 高响应延迟(HSRT)占总的高响应延迟(HSRT)的比例,可以看出页面所含的图片数量是主要的性能瓶颈

FOCUS:

- 首先FOCUS使用系统每天产生的日志数据来训练决策树,从决策树中可以分析得到引发高搜索响应时间(HSRT)的条件,由于每天的数据会训练出一棵决策树,因此多天后会有多棵决策树产生;
- 接下来在多棵决策树中挖掘出相似的会引发高搜索响应时间(HSRT)的条件,这些条件在多天中重复出现,可以判断为长期的引起高搜索响应时间(HSRT)的可能条件;
- 最后评估挖掘出的引发高搜索响应时间(HSRT)条件中每个属性的影响,从而得出优化系统性能的方案。
Adtributor:根因定位
- 异常检测:
利用ARMA模型进行预测,当预测结果和实际结果超出一定的百分比偏差时告警 - 根因查找:
Adtributor假设所有根因都是一维的
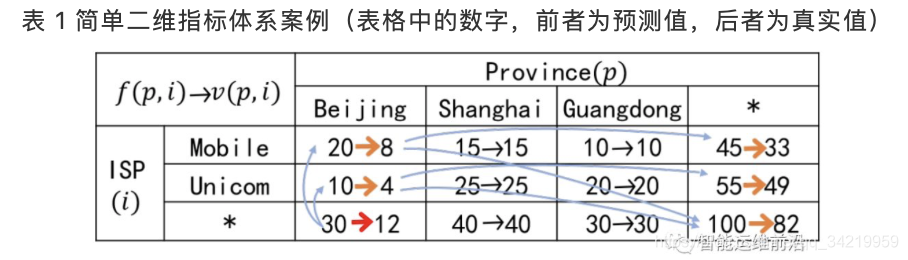
提出了解释力(Explanatory power)和惊奇性(Surprise)来量化根因的定义。通过计算维度的惊奇性(维度内所有元素惊奇性之和)对维度进行排序,确定根因所在的维度(例如省份)。在维度内部计算每个元素的解释力,当元素的解释力之和(例如北京+上海)超过阈值时,这些元素就被认为是根因。
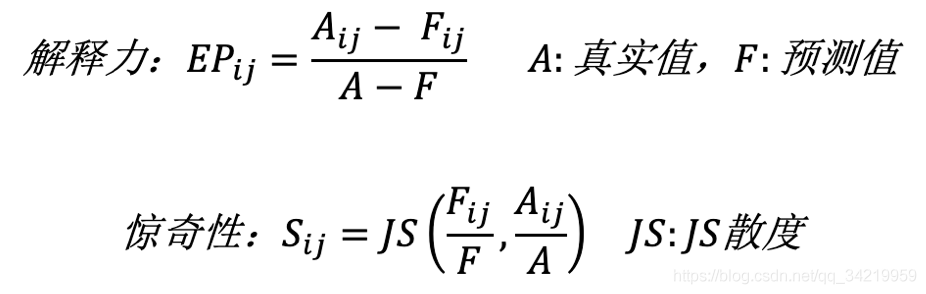
- 缺点:
(1)上述是针对基本类型的KPI的计算公式(例如PV、交易量),对于派生类型的KPI(多个基本类型KPI计算得到,例如成功率)就不太适用了
(2)将根因限定在一维的假设不太符合我们的实际场景,同时用解释性和惊奇性的大小来衡量根因也不完全合理。因为其没有考虑到维度之间的相互影响以及「外部根因」的可能
(3)Adtributor的根因分析严重依赖于整体KPI的变化情况,对于整体变化不大,但是内部波动较为剧烈的数据表现不好
MSRA iDice:多维指标突变定位
- 分析:
(1)issue本身数量要多
(2)issue变化要大
(3)尽可能是最根本原因(冗余低) - iDice:
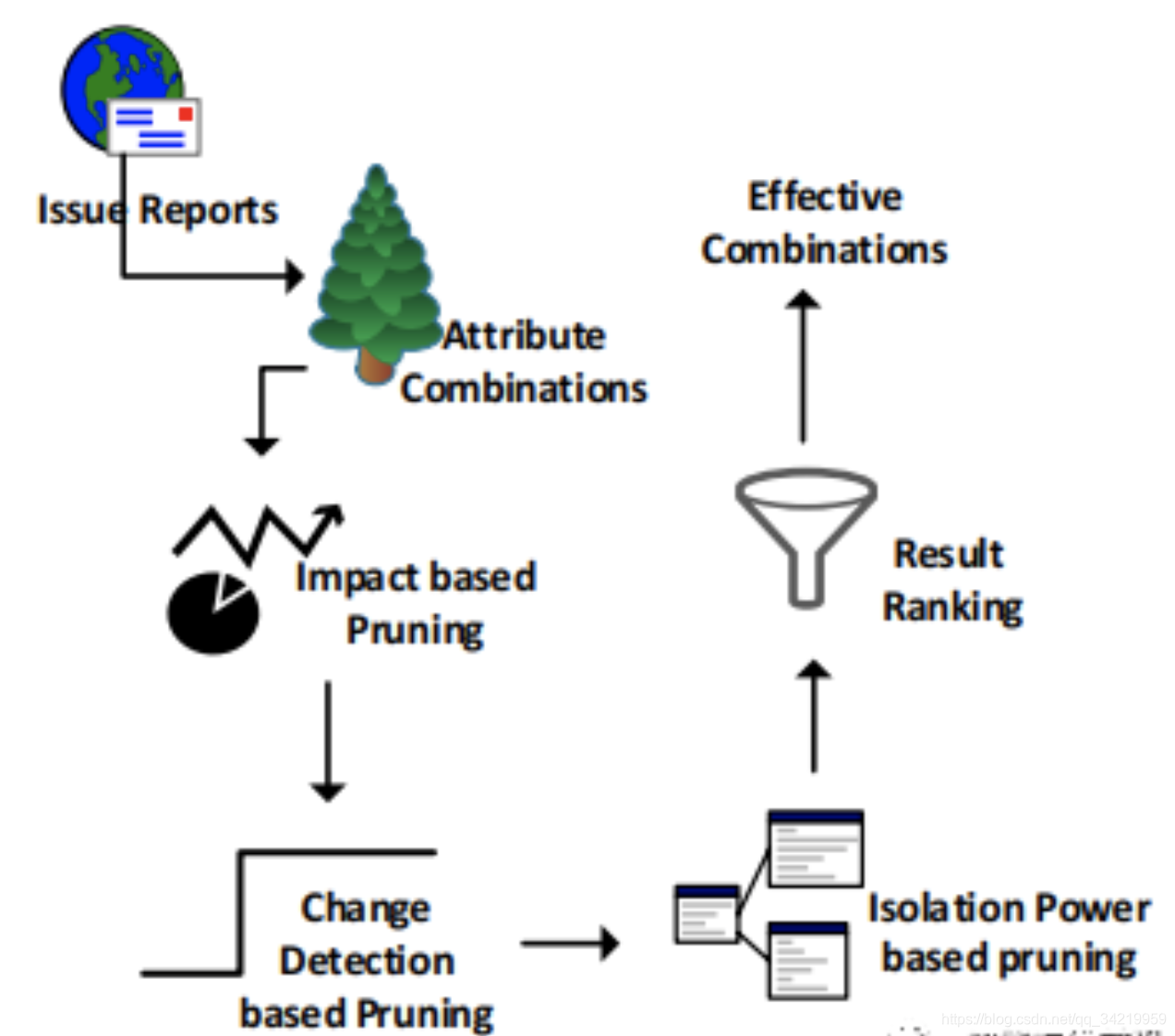
(1)只考虑issue report数量大的组合,数量不足直接剪枝。iDice通过采用数据挖掘算法、计算支持度、设定阈值。
(2)找出与问题报告数量显著增加相对应的组合。用GLR检测变化,剪枝变化小的。
(3)提出Isolation Power如下,当发现 一个combination节点的IP值 既大于它的子节点IP值,又大于它的父节点的IP值,则可将其子节点与父节点剪枝删除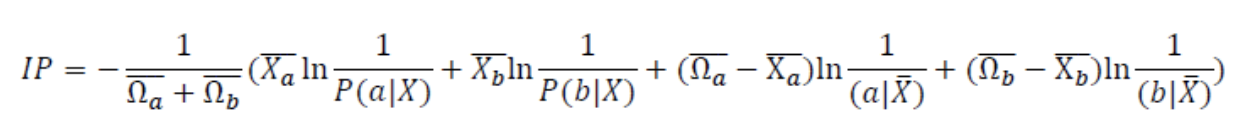
(4)根据这些combination的相对重要性对它们进行排序,R=pa*ln(pa/pb)
清华Hotspot:多维根因定位
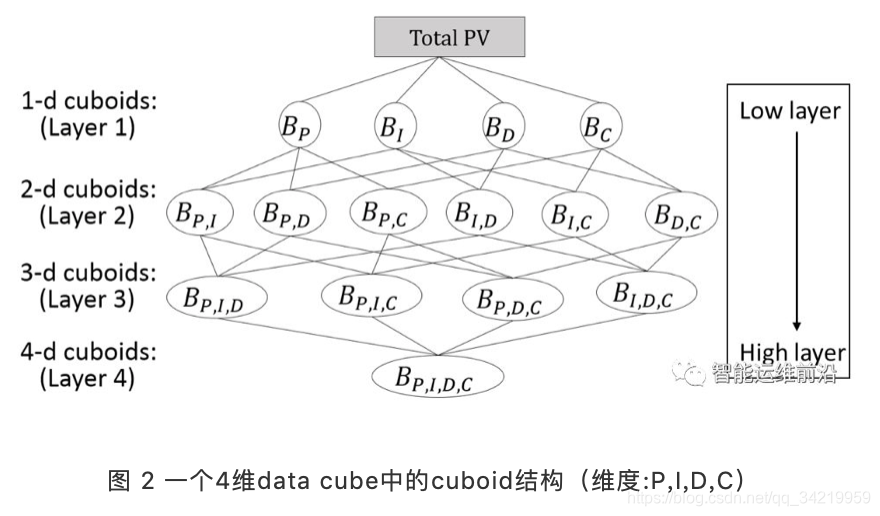
- 挑战:
(1)用一个指标评价一个元素/集合是根因的可能性程度
(2)搜索空间太大 - Hotspot:
(1)Ripple effect
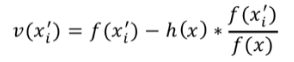
(2)Potential score
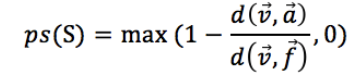
(3)MCTS算法
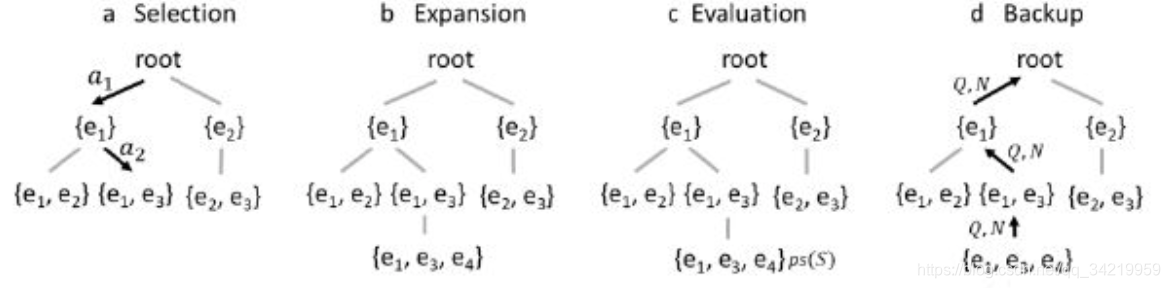
(4)分层剪枝:对于前一层中ps过小的元素,将其在本层中的子元素剪枝去掉
智能变更
清华FUNNEL:评估变更影响
- 背景:软件变更发生后,快速、准确地评估软件变更的影响,是Web服务运维中亟待解决的重要课题
如果变更不好,Web服务、部署的服务器的 KPI 曲线会出现剧变。包括Web用户感知的问题(如用户点击时延)、服务性能(如用户点击量)、服务器硬件健康状况(如CPU使用率、内存使用率)等。因此,检测KPI曲线的剧变可以检测Web服务性能的变化 - 难点:
(1)同时满足低检测时延和高准确性要求
(2)KPI数量巨大
(3)KPI类型多样:稳定型、周期型、多变型
(4)KPI曲线剧变可能由其他因素导致:网络硬件故障、恶意攻击 - FUNNEL
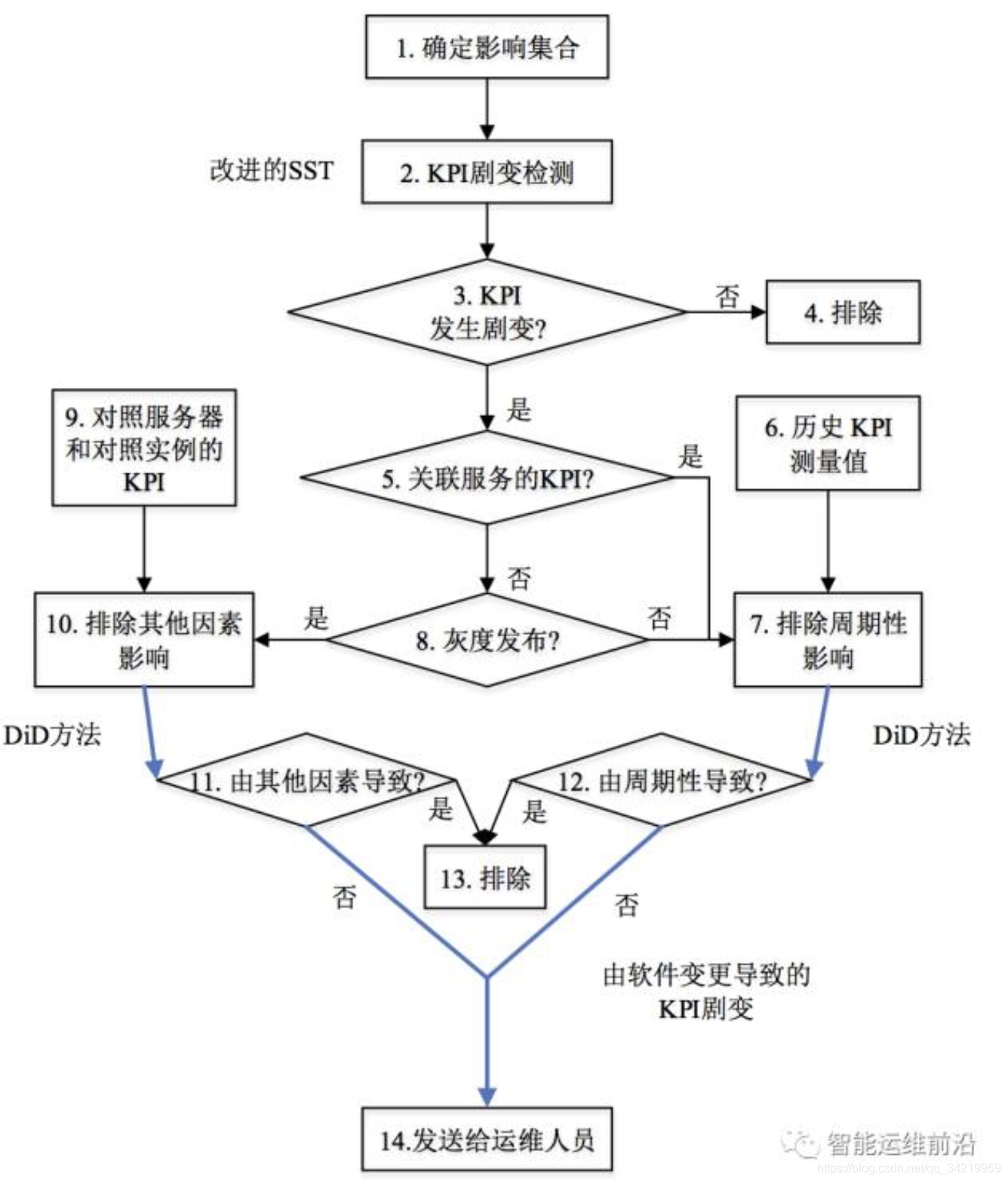
检测异常用的改进SST:通过使用前置矩阵更多信息的方法,提高了SST的鲁棒性。使用矩阵压缩和隐式内积计算的方法,降低了SST算法的计算复杂度。
异常检测
雅虎EGADS:KPI异常检测框架
-
介绍:
EGADS主要包含了3个模块,分别是 时间序列建模模块 (TMM), 异常检测模块 (ADM),报警模块 (AM)。给定一个时间序列,TMM会算出期望值,ADM通过期望值给出可能为异常的概率。对于不重要的异常,AM会自动过滤掉,而对于重要的异常,AM会给出预警 -
实现的功能:
目前EGADS能够检测出3种类型的异常,它们分别是:
(1)Outliers:对于一段时间序列而言, Xt是t时刻的观察值,E(Xt)是在t时刻的期望值,如果 Xt和E(Xt)存在着较大的差异,那么可以认为Xt是一个Outliers。
(2)Change points:对于一个给定的时刻t,如果数据点在t之前以及之后的行为和t时刻的行为有较大的差异,那么该时刻t被称为Change point。Change point和Outliers最大的不同之处是前者往往意味着长时间的变化和异常,而后者往往是反复无常,不稳定的。
(3)Anomalous time-series:Anomalous time-series是定义在时间片段上的,如果某个时间片段的特征和其他的时间片段有明显的不同,那么该时间片段被定义为Anomaylous time-series。
清华Opprentice:KPI自动化异常检测
- 背景:异常检测系统的痛点就是异常检测算法的选择以及算法参数的调整。为KPI曲线选择合适的检测器和算法参数很耗费精力。
- 解决的问题:自动选择异常检测器和自动调节算法参数
- Opprentice:
(1)使用十几种不同类型的检测器提取出KPI曲线的特征,其中每种检测器都有多种不同的参数配置,因此最终会提取出上百个异常特征(包含冗余)
(2)随机森林训练模型,转换为二分类问题
清华DeepLog: 日志异常检测
- 挑战:
(1)非结构化日志,它们的格式和语义在不同系统之间有很大差异
(2)时效性
(3)异常类型多 - DeepLog:
(1) 执行路径异常检测。将异常检测问题转换成一个log key的多分类问题,使用LSTM对日志的log key序列建模,假设日志共有n个log key,DeepLog的输入为一个时间窗口内的log key序列,输出为所有的log key在该log key序列之后出现的概率的向量。也就是说,如果新来的一条日志对应的log key不是接下来出现概率较大的log key,则视为异常。
(2) 参数和性能异常检测。DeepLog将每一个log key对应的参数保存下来,作为异常检测的数据源。与执行路径异常检测的方法类似,参数和性能异常检测也会使用LSTM网络建模。它的输入为某个log key对应日志中近期历史的参数值向量,输出为下一个参数值的预测值。
(3)工作流异常检测。虽然工作流模型在异常检测的有效性上不如LSTM模型,但是工作流模型可以可视化地帮助运维工程师在发现异常后找出异常的原因。
清华StepWise:指标模式漂移后的准确异常检测
- 背景:训练好的检测器开始工作很好,但是准确率会随着时间的推移而显著降低,这是因为 KPI 发生了概念偏移。而这种变化一般是KPI曲线的阶跃(如图中所示的巨幅下降),或是缓慢的上升/下降(如内存泄露等逐渐恶化的场景)
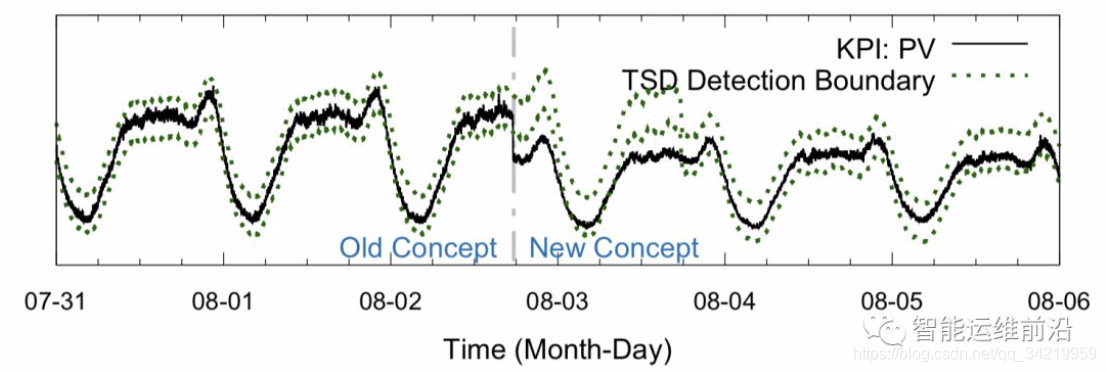
注意,概念偏移可能是符合预期的,符合预期的是由运维工程师主动操作或者业务实际增长导致的 KPI 剧变,而不符合预期意味着异常的突变。符合预期的概念偏移发生的次数更多,据统计在概念偏移总数中占比超过80%,比如扩容是把服务部署到更多的服务器上,单台服务器上的请求量就会明显下降,因为全部的请求量是稳定的,这种情况就是一个预期之中的概念偏移。 - StepWise:
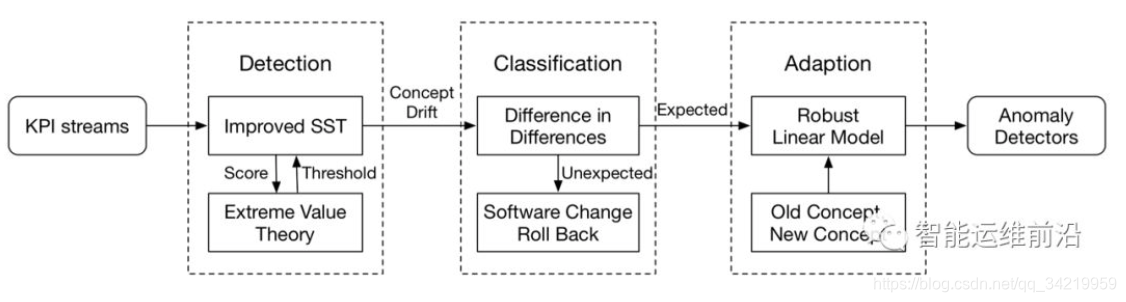
(1) 概念偏移的检测:SST+EVT。
(2) 区分概念偏移是否符合预期:DiD。
(3) 迅速适应符合预期的概念偏移:重新训练线性模型RLM。
故障预测
IBM: 磁盘故障预测
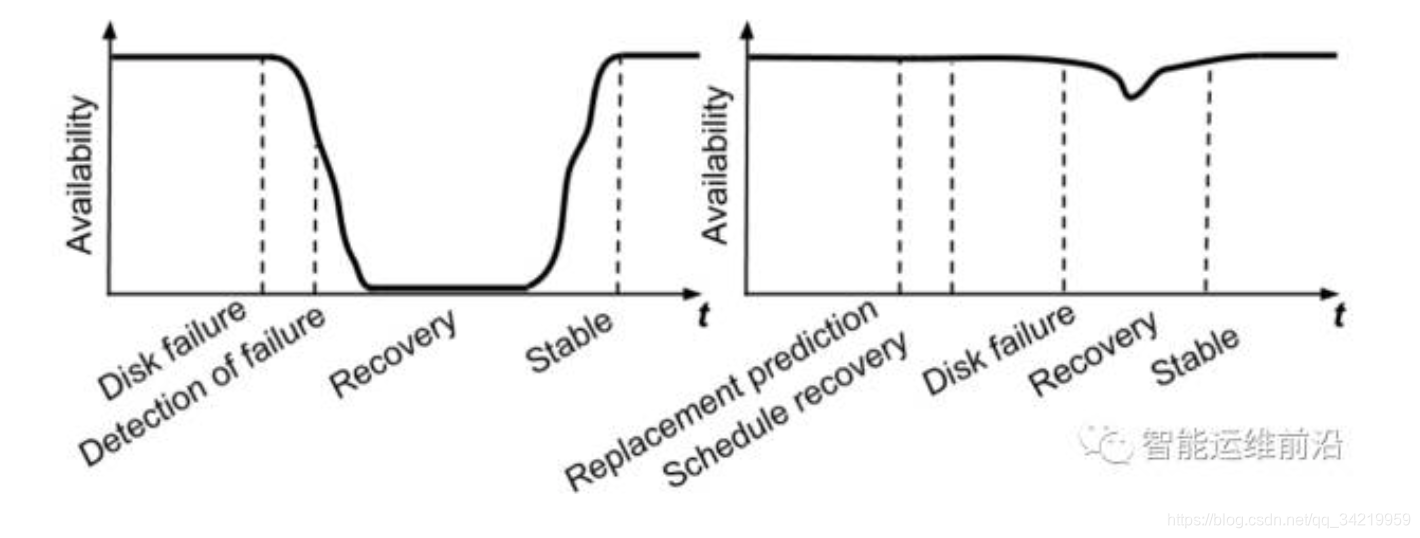
- 背景:左图代表的是传统的磁盘异常检测,磁盘状态开始变差后才检测到磁盘故障,这时的可用性已经降到了最低才开始更换磁盘。右图展示的是使用磁盘故障预测的情况,首先系统判断磁盘的状态即将要变差,然后工程师在磁盘可用性降低之前更换磁盘。通过这两个图的对比,我们可以看出提前预测磁盘故障可以降低故障对系统可用性的冲击
- 挑战:
(1)不是所有的SMART属性都与磁盘故障相关
(2)负样本太少
(3)不同类型的磁盘SMART存在差异 - 本文策略:
(1)选择SMART属性。使用突变点检测的方法对SMART属性分类,选择与磁盘替换相关的SMART属性。
(2)生成时间序列。使用指数平滑来生成简化但是信息丰富的时间序列。
(3)解决数据不平衡性。通过欠抽样选择具有代表性的健康磁盘的数据,然后用这些数据来代表全部的健康磁盘,从而使健康磁盘与替换磁盘的比例达到平衡。
(4)对磁盘状态分类。RGF是一个分类算法,可以将磁盘的状态分成0/1的状态,如果当前时间序列被分成1状态,则认为磁盘即将出现故障,需要更换磁盘。
(5)迁移学习。考虑到同一厂商生产的不同磁盘模型之间也存在一定差异,本文使用了迁移学习的方法,从而利用某种磁盘上训练的模型来预测同一厂商的其他磁盘的故障替换情况。
聚类
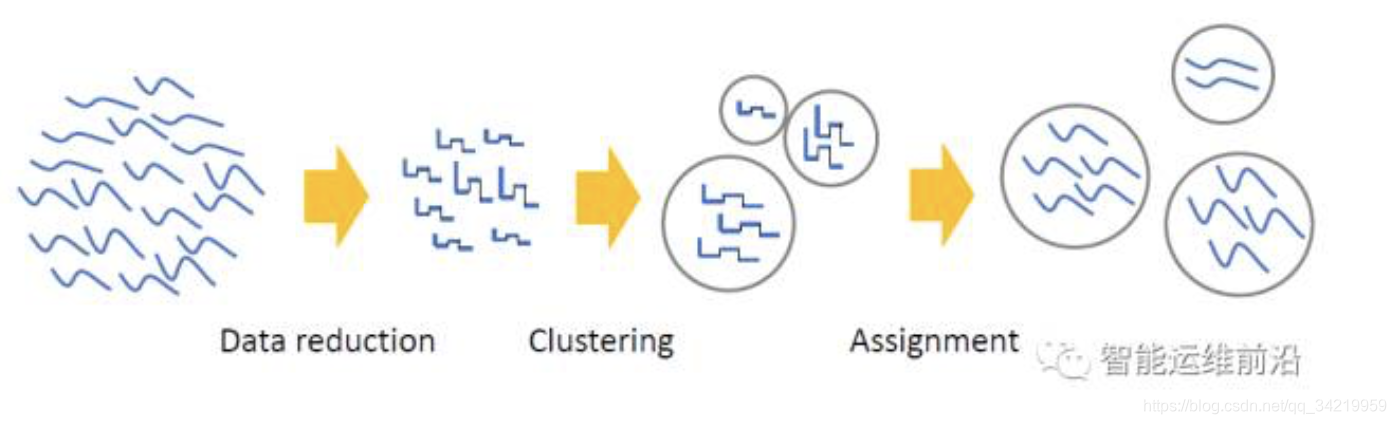
微软Yading:时序数据聚类算法
- 挑战:
(1)时序数据数量大、维度高
(2)时序数据实例间的相似性难以准确刻画
(3)聚类算法参数难以确定 - Yading:
(1)输入数据集采样。对大量的时序数据进行随机采样,并使用逐段聚集平均(PAA)算法缩减每条时序数据实例的维度。用采样后的数据集作为聚类算法的输入。
(2)在采样后的数据集上进行时序数据聚类。使用L1距离作为时序数据曲线间的相似性度量。在基于密度的聚类算法DBSCAN的基础上,设计出多密度的聚类算法Multi-DBSCAN,并使算法能够自动决定参数。
(3)**对大量数据采用分派策略进行分类。**对于采样中未被选择的大量时序数据曲线,采用分派策略将其分到与其L1距离最近的已聚类曲线所属的聚类簇中。同时建立了有序邻居图辅助计算时序数据实例之间的距离,提高分派算法的计算效率。
微软LogCluster:日志聚类
- 思路:从测试环境中学习聚类结果和日志的执行序列;再将线上系统的实际日志与学习的结果进行比对来发现可能的异常相关日志集合。
- LogCluster:
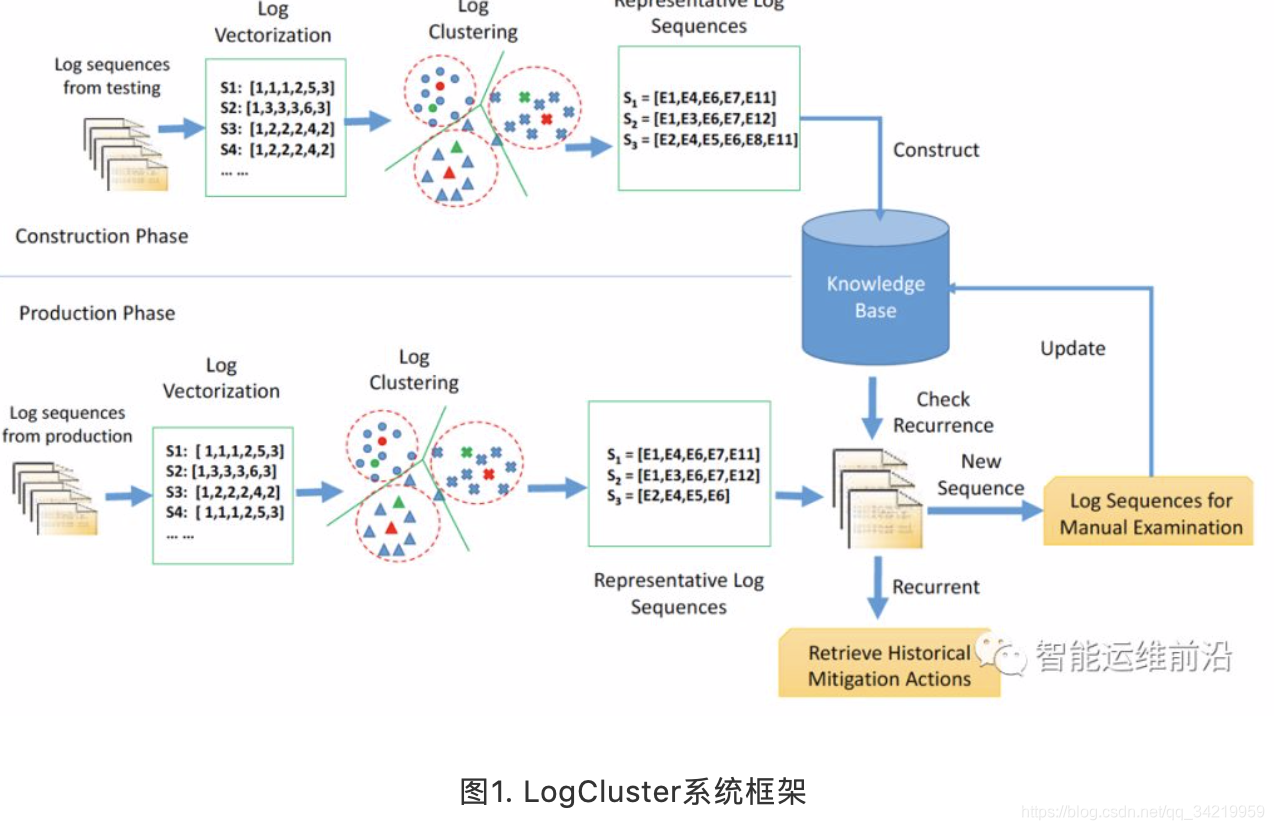
(1)日志向量化:将日志转化为向量形式并赋予相应的权重。将系统变量视为参数,语句视为常量字符串,可以将日志转化为抽象的日志事件。
(2)日志聚类:计算不同日志之间的相似程度,并通过AHC算法(Agglomerative Hierarchical Clustering)进行聚类。
(3)序列提取:在每一类中,提取代表性的日志序列。
(4)重复比对:对比生产环境的实际日志序列是否在知识库中已经出现。运维人员只需要人工关注那些新出现的事件。
清华FT-Tree:提取日志模板
- 背景:当前提出的模板提取方法或者在学习“正确” 模板集合时准确性较低,或者不支持增量式学习
- FT-tree :一种扩展的前缀树结构
(1)扫描一次DM, 得到单词出现频率的降序排列
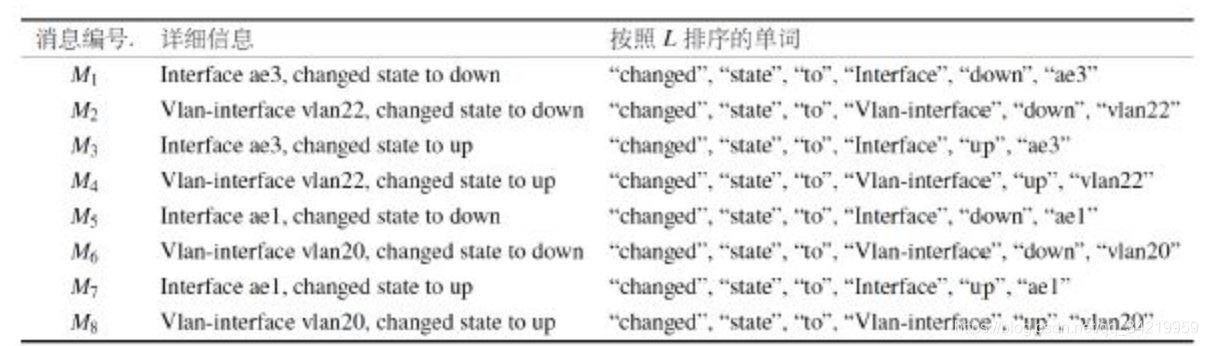
(2)构建树
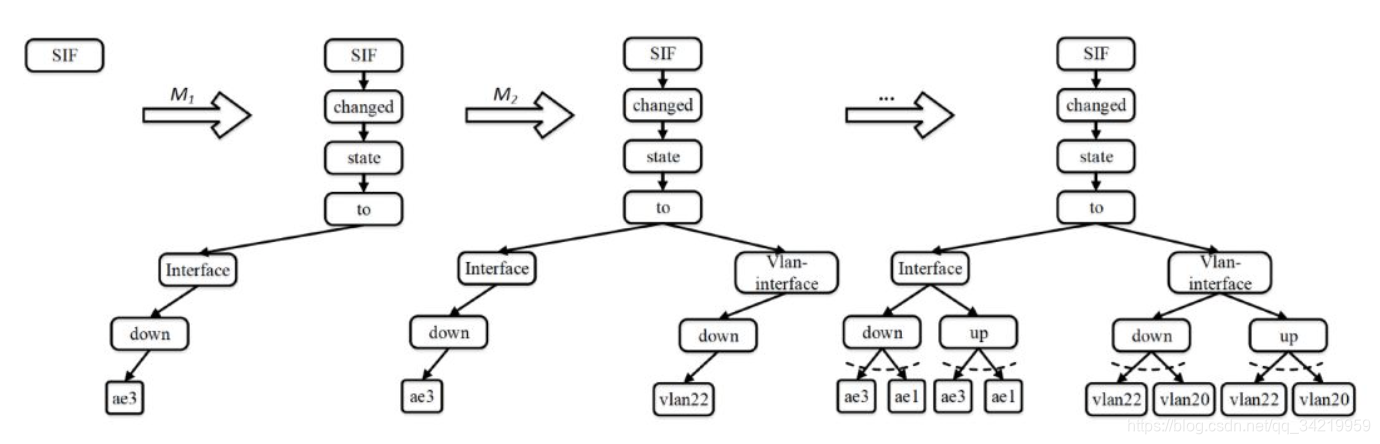
(3)修建树。如果FT-tree的一个节点有太多的子节点,那么它的所有子节点就从FT-tree 中删除。这样,该子节点就变成叶节点
(4)增量式模板学习:插入节点
清华ROCKA:KPI聚类
- 挑战:
(1)KPI曲线上的噪声、异常、相位偏差和振幅(量纲)差异通常会改变KPI曲线的形状
(2)一条KPI曲线通常包含上万个数据点 - ROCKA:
(1)预处理:对原始KPI数据进行标准化,消除振幅差异。
(2) 基线提取:去除曲线上的噪声和可能的异常点,提取基线来表示曲线的形状。
(3)相似性度量:采用基于形状的SBD距离作为相似性度量,消除曲线间的相位偏差影响。
(4)聚类与分派:对样本集中的KPI进行高效、鲁棒的聚类,为每个类别计算聚类中心表征该类别曲线形状。对于大量未分类曲线,利用聚类中心为其快速分派类别
对比:YADING仅采用简单的L1距离作为度量,且未做对异常点和相位偏差的处理















 1856
1856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









