









最近看过FCN的论文,自己来讲讲对他的理解!
首先我们得去github下载原码,下载适合caffe版本的FCN原码,我给个链接吧!那是我自己总结的让demo跑起来的过程,个人理解。
博客网址:http://blog.csdn.net/qq_34220460/article/details/70244725
论文下载地址:FullyConvolutional Networks forSemantic Segmentation
自己对这个模型的理解:首先从文章的标题就可以看出文章使用了全卷积网络,那意思是说相对之前的alexnet模型来说,把最后的几层全连接层改成卷积层,网络也就变成了全卷积网络,以segmentation 的 ground truth作为监督信息,训练一个端到端的网络,让网络做pixelwise的prediction,直接预测label map。
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN 可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样,它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。我们来看下FCN总体的网络结构:
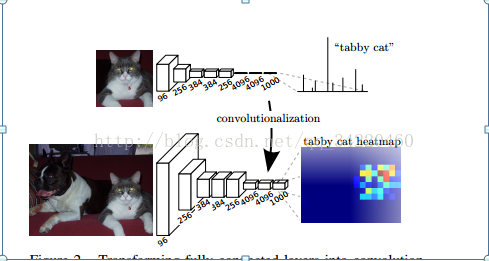
正如上段话所言,上面那个是alexnet的模型结构,下面那个是全卷积模型,可以看出区别了吧!其实他还没有全部画出来,我们还有反卷积层,也就是上采样层(文章说的是上采样层),这个时候就看我们是需要采用那个层的特征图了。
所以也就会有FCN-32s,FCN-16s,FCN-8s,文章中有这个结构,如图:
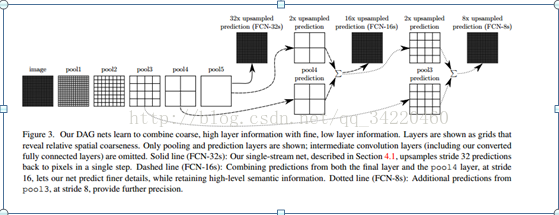
正如图中所看到的那样,省了后面的卷积层。
文章中有段话刚好可以解释这个图形,如下:
We add a 1 × 1 convolution layertop ofpool4 to produce additional class predictions. We fuse this output with thepredictions computedon top of conv7 (convolutionalized fc7) at stride 32byadding a 2× upsampling layer and summing6 both predictions. (See Figure 3).We initialize the 2× upsampling to
bilinear interpolation, but allow the parameters to be learned
as described in Section 3.3. Finally, the stride 16 predictions
are upsampled back to the image. We call this net FCN-16s.
FCN-16s is learned end-to-end, initialized with the parameters of the last,coarser net, which we now call FCN-32s.The new parameters acting on pool4 arezero-initialized sothat the net starts with unmodified predictions. Thelearningrate is decreased by a factor of 100.
这段话的意思是,我们首先添加了卷积核大小为1*1的卷积层在pool4上用来产生额外的类别预测,然后我们将这个输出和在fc7输出上上采样得到的预测进行融合,并且对预测进行求和。我们初始化这个上采样是线性内插,允许参数被学习。最后,融合后的预测进行上采样步伐为16回到原图像尺寸大小,我们现在叫做FCN-16s, FCN-16s被学习到端到端,参数最后被初始化,粗略网络也就是我们叫做的FCN-32s(也就是这个网络执行到底,在最后的输出特征图上进行步伐为32的上采样,这样所得到的结果就是FCN-32s)。添加在pool4上的卷积层参数被初始化为0,以至于网络在没改变的预测下开始训练。学习速录下降了100倍。
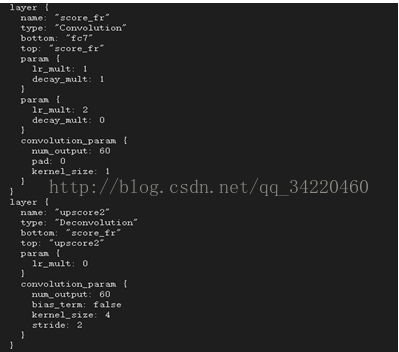
通过文章中的这段话我们可以解释那张图是怎样的一个流程,
FCN-32s:在最后的输出特征图上进行步伐为32的上采样,再进行像素分类。
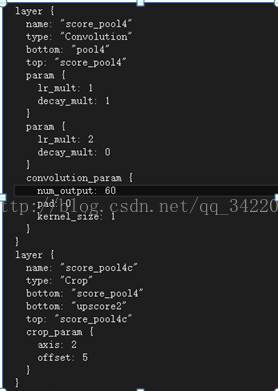
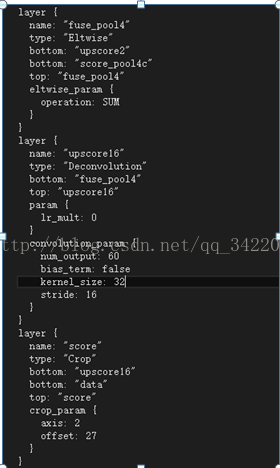
FCN-16s:先在pool4层添加一个卷积核大小为1*1的卷积层,产生一个额外的输出,然后在pool5(也就是网络执行过后的fc7输出)进行上采样步伐为2,让这个特征图回到pool4层所代表的信息,然后再把这两个输出进行融合,最后在融合后的结果上进行上采样步伐为16,这样就可以回到原图像尺寸大小,在这个特征图上进行像素分类。
FCN-8:就是先在pool3进行跟上面一样,添加卷积层产生额外的输出,然后再把fcn-16中融合的结果进行上采样步伐为2的上采样,这样在再把两个输出进行融合,接着是进行上采样步伐为8的上采样,最后再对这个预测进行分类。
其实说白了,在这个网络中卷积层的池化层步伐为2,使得图像大小缩小了两倍,然后我们一步一步的把最后的结果放大到原图像尺寸大小。这个也是文章所说的方法,skip_layert或者是combiningwhat and where,把深的粗糙的输出和浅的精细的输出结合起来。这是因为CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高。
现在我们也就来看看各层是怎么样的?
我们这里是以pascalcontext-fcn32s为例,前面5层应该是不用说的,都能看懂,到了fc-6-new层,对了有必要说明下,这个网络使用了迁移学习和小的卷积核,及他使用了已经训练好的模型来训练网络,文章里有说。使用小的卷积核,这样就可以把卷积层进行分层,就加快训练速度。你会发现后面几层的步伐都为1,那说明后面几层的卷积是不改变图像大小,是总的来说,细节不考虑了。在score_fr层后是deconvolution层,也就是反卷积层。你会发现步伐为32,卷积核为64,例:
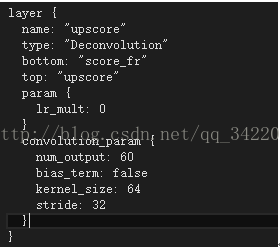
内核大小选择为64,?我个人认为是前面所有的卷积核大小外加扩充边缘之和就是64,不知道是不是这样理解!!!我为啥这样理解呢!我们不是有计算图像大小的公式吗?【img_size - filter_size+2*pad】/stride +1 =new_feture_size,因为池化的步伐都为2,卷积步伐为1,所以相当于每过一层就缩小2倍。
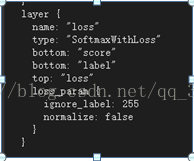
之后的Crop层就是的对图像大小的细节进行修补。最后在接个分类层。Ok!弄懂原理,看懂很简单。。
那么FCN-16s和FCN-8s也是如此!
Fcn-16s就如我上面所说:如:
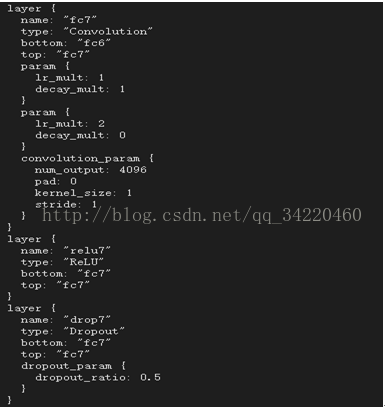
哎!就是上面所讲的步骤的实现!!!FCN-8上也是如此!!!
再来讲讲训练细节:用AlexNet,VGG16或者GoogleNet训练好的模型做初始化,在这个基础上做fine-tuning,全部都fine-tuning。采用whole image做训练,不进行选取某些位置进行训练,就是alexnet模型所讲的数据增益技术。实验证明直接用全图已经很有效。对classscore的卷积层做全零初始化。随机初始化在性能和收敛上没有优势。
对了还漏了一个细节!!!文章所说:
Final layer deconvolutional filters arefixed to bilinear interpolation, while intermediate upsampling layers areinitialized to bilinear upsampling, and then learned. 最后一层的反卷积滤波器被固定为双线性内插,然而中间的上采样层被初始化为双线性的上采样,可以被学习。
不知道这个在哪里可以看出来!我是看不出来哪里被固定为双线性内插?














 3882
3882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









