




 本文深入探讨SQL窗口函数,包括SYNTAX结构、PARTITION BY、ORDER BY、窗口定义及专用窗口和聚合函数。窗口函数提供了一种灵活的分组方式,能实现复杂逻辑,如平均值计算、排名、极值提取等。通过ROWS和RANGE定义窗口范围,可以针对行或值进行滑动。同时,文章介绍了各种窗口函数的使用场景,如AVG、COUNT、ROW_NUMBER、LEAD和LAG等。
本文深入探讨SQL窗口函数,包括SYNTAX结构、PARTITION BY、ORDER BY、窗口定义及专用窗口和聚合函数。窗口函数提供了一种灵活的分组方式,能实现复杂逻辑,如平均值计算、排名、极值提取等。通过ROWS和RANGE定义窗口范围,可以针对行或值进行滑动。同时,文章介绍了各种窗口函数的使用场景,如AVG、COUNT、ROW_NUMBER、LEAD和LAG等。
文章目录
- 一、前置
- 二、syntax
- 1.作为窗口函数使用的函数有两类:
- 2.PARTITION BY 表示将数据先按 part_list 进行分组, 如果不指定 PARTITION BY,则不对数据进行分组,换句话说,所有数据看作同一个分组。
- 3.窗口函数原则上只能写在select子句中,不用在where和group by子句中使用
- 4.ORDER BY 表示将各个分组内的数据按 order_list 进行排序。一般情况下都要指定,如果不指定 ORDER BY,则不对各分区做排序,通常用于那些顺序无关的窗口函数,例如SUM。order by子句中可以通过desc,asc指定降序或升序,如果省略,默认会按照升序asc排列
- 5.专用窗口函数括号中可以为空,不用指定参数。聚合函数作为窗口函数要指定参数。
- 6.窗口函数兼具分组和排序的功能,但是其分组并不具备group by子句的汇总功能,而是一行一个结论。
- 三、窗口的定义:WINDOW子句(灵活控制窗口)
- 四、专用窗口函数和聚合函数
- 五、case
一、前置
所谓分析,就是复杂到简单,大多数情况,都是多变少。基本思想就是分门别类、多条数据归纳出一条结论,也就是分组聚合。
而group by一个分组只能返回一条数据,太死板。窗口函数提供了一种灵活、强大的分组方式,配合聚合函数和窗口函数,能实现复杂的逻辑。
group by + 聚合函数每组只返回一行,因为它只能对组内的所有数据进行统计。
窗口函数会针对组内每行数据的窗口进行一次聚合计算,因为窗口子句指定了数据窗口大小,这个数据窗口包含的行会随着行的变化而滑动变化,可以在这个滑动窗口里进行计算并返回一个值。
- 即使是传统的avg,使用了窗口后也是每行返回一个结果
SELECT subject,avg(score) OVER(PARTITION BY subject) FROM scores;
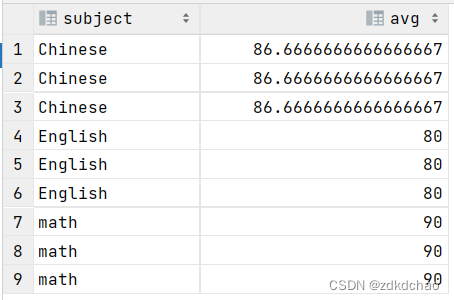
窗口这种可以随意设定范围的分组方式比group by这种一组返回一条、只能根据列来分组要强大的多,可以做到一行对应一个结果。group by能实现的,窗口函数都能实现
二、syntax
窗口函数包含2部分,over前面的窗口函数和[over,后面]的窗口子句(用来定义窗口)
窗口子句用来定义窗口,窗口函数用来定义在这些窗口上进行什么操作
分析函数名(参数) OVER (PARTITION BY子句 ORDER BY子句 ROWS/RANGE子句)
window_function (expression) OVER (
[ PARTITION BY part_list ]
[ ORDER BY order_list ]
[ { ROWS | RANGE } BETWEEN frame_start AND frame_end ] )
1.作为窗口函数使用的函数有两类:
- 专用窗口函数rank、dense_rank、row_number等
- 聚合函数(sum、avg、count、max、min)
2.PARTITION BY 表示将数据先按 part_list 进行分组, 如果不指定 PARTITION BY,则不对数据进行分组,换句话说,所有数据看作同一个分组。
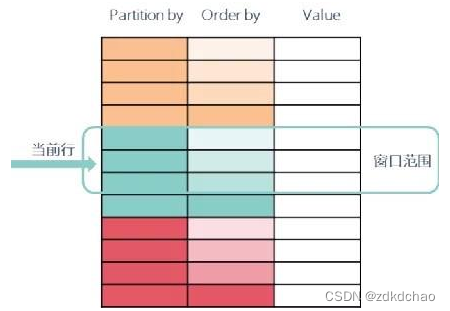
- 其中partition by可以省略。窗口函数的partition by子句不是必须的,即使省略也可以正常使用窗口函数,只是把所有数据作为一个组
3.窗口函数原则上只能写在select子句中,不用在where和group by子句中使用
4.ORDER BY 表示将各个分组内的数据按 order_list 进行排序。一般情况下都要指定,如果不指定 ORDER BY,则不对各分区做排序,通常用于那些顺序无关的窗口函数,例如SUM。order by子句中可以通过desc,asc指定降序或升序,如果省略,默认会按照升序asc排列
5.专用窗口函数括号中可以为空,不用指定参数。聚合函数作为窗口函数要指定参数。
6.窗口函数兼具分组和排序的功能,但是其分组并不具备group by子句的汇总功能,而是一行一个结论。
三、窗口的定义:WINDOW子句(灵活控制窗口)
待分析的数据是一个黑箱,开个窗口向外暴露,窗口可以滑动。
既然是滑动的,那就需要设置是按行滑动,还是根据对应列的值滑动,也就是锚点(滑轨)
既然是窗口那就需要设置窗口的大小,也就是步长。
1.步长
frame_extent指定帧的起止点,在其中也可以只用frame_start(结束位置就默认为当前行)和frame_between指定起点和终点。
frame_start和frame_end可以是以下几种:
CURRENT ROW: 当前行
UNBOUNDED:起点(一般结合PRECEDING,FOLLOWING使用)
UNBOUNDED PRECEDING 表示该窗口最前面的行(起点)
UNBOUNDED FOLLOWING:表示该窗口最后面的行(终点)
N PRECEDING: 当前行之前的N行,可以是数字,也可以是一个能计算出数字的表达式
N FOLLOWING:当前行之后的N行,可以是数字,也可以是一个能计算出数字的表达式
如果没指定帧的话,默认的frame取决于ORDER BY。
如果有ORDER BY,SQL会默认帧是区间内从第一行(UNBOUNDED PRECEDING)到当前行(CURRENTROW)
如果没有ORDER BY,SQL会默认帧是区间内从第一行(UNBOUNDED PRECEDING)到最后一行(UNBOUNDED FOLLOWING)
比如说:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(表示从起点到当前行)
ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING(表示往前2行到往后1行)
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW(表示往前2行到当前行)
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING(表示当前行到终点)
官网有一段话列出了哪些窗口函数是不支持window子句的,如下图所示:

2.锚点:ROWS/RANGE BETWEEN
通过ROWS与RANGE来限制窗口的行数
{1}ROWS 以行为锚点,按行的row_number来筛选行
例如 ROWS BETWEEN 3 PRECEDING AND 3 FOLLOWING 表示当前行往前数3行到往后 3 行,一共 7 行数据(或小于 7 行,如果碰到了边界)。所以ROWS是通过排序后的前后位置选取窗口范围。
{2}RANGE 根据目标列的值为滑轨,按值筛选行。表示的是具体的值,比这个值小n的行,比这个值大n的行
[1]那个根据那一列的值呢?
根据order by的列的值进行范围判断。
值相同的行会被合并成同一条数据再进行计算,相同行窗口计算时的结果也是相同的。
是否是相同行,是根据ORDER BY排序时的结果决定的。
有ORDER BY时:同行是说在ORDER BY排序时不唯一的行。【即具有相同数值的行】
不同行是说ORDER BY排序时具有不同的数值的行。
没有ORDER BY:那么就是当前分区的所有行都包含在框架中,因为所有行都会成为当前行的相同行。【特别要注意最后一句的意思】
[2]case
- RANGE BETWEEN 3 PRECEDING AND 3 FOLLOWING
表示选取取值在 [c-3,c+3]这个范围内的行(其中c 为当前行的值)。所以RANGE是通过数值的大小选取窗口范围。 - range between 4 preceding AND 7 following
如果当前值为10的话就取前后的值在6到17之间的数据。 - partition by userid order by date range between 3 preceding and current row
窗口大小设置为该分区内小于本记录date-3天的窗口 - sum(close) range between 100 preceding and 200 following
则通过字段差值来进行选择。如当前行的 close 字段值是 200,那么这个窗口大小的定义就会选择分区中 close 字段值落在 100 至 400 区间的记录(行)。
{3}参考下图看看ROWS 和 RANGE的区别
1
表数据如下
i col
1 1
2 1
SELECT t.*,
SUM(col) OVER (ORDER BY col
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) as ROWSresult,
SUM(col) OVER (ORDER BY col
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) as RANGEresult
FROM t
i col rowsresult rangeresult
1 1 1 2
2 1 2 2
ROWS子句滑到第一行时,从第一行到当前行,也就是第一行到一行,所以rowsresult是sum(1)=1。
RANGE计算值符合范围的。col两行值相同因此第一次就计算了2行。
2
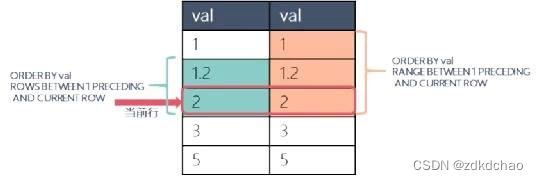
一个表只有一列val,当前行val列的值是2
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW指定的窗口就是前一行和当前行,共两行;
RANGE BETWEEN 1 PRECEDING AND CURRENT ROW指定的窗口是当前行val值2减去1到2这个范围内的数据,共包括1、1.2、2三行。
四、专用窗口函数和聚合函数
https://zhuanlan.zhihu.com/p/336545182
https://www.jianshu.com/p/12eaf61cf6e1
按照使用功能场景,可以分为以下 5类:
聚合(Aggregate):AVG(), COUNT(), MIN(), MAX(), SUM()…
排序(Ranking):
| - | - | - |
|---|---|---|
| ROW_NUMBER() | 123 | 连 |
| RANK() | 112 | 复连 |
| DENSE_RANK() | 113 | 跳 |
极值(Value):FIRST_VALUE(), LAST_VALUE()…
分组取最早、最迟函数可用于取用户的首次行为时间、最后一次行为时间,计算生命周期。
First_Value():分组内排序后,获得组内当前行往前的首个值;
Last_Value():分组内排序后,获得组内当前行往前的最后一个值。
位移(Shift):LEAD(), LAG()…
前后平移可快捷计算同比、环比值;
Lag(col, n, DEFAULT) 用于统计窗口内往上第n行值;
Lead(col, n, DEFAULT) 用于统计窗口内往下第n行值, 与LAG相反。
default省略,则默认为NULL; 不需显式进行手动分组排序,在使用函数 LAG/LEAD 时最终呈现记录为自动排序。
分析(Analytics):CUME_DIST、PERCENT_RANK…
Cume_Dist:小于等于当前值的行数/分组内总行数。应用场景统计,用于收入订单前多少的排名,或者订单数 pk 百分比。注意:没有 partition ,所有数据分到同一组。
Percent_Rank:分组内当前行的RANK值-1/分组内总行数-1。暂时没有想到应用场景。
分箱(Binning):
NTILE(n)
将指定窗口/子窗口中的数据均分为n份,多出的那一行放在第一个分区。
用于求TOP百分比或几分之几
不支持ROWS BETWEEN
select cookieid,createtime,pv,
ntile(3) over(partition by cookieid order by pv desc) as rn
from cookie
where rn = 1;


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









