







突发奇想,想看看各个高校自主招生的录取情况
在阳光高考上显示的名单不利于我们统计分析
不如用python写个爬虫来爬取这些数据吧
我们打开2017年的清华大学自主招生录取名单
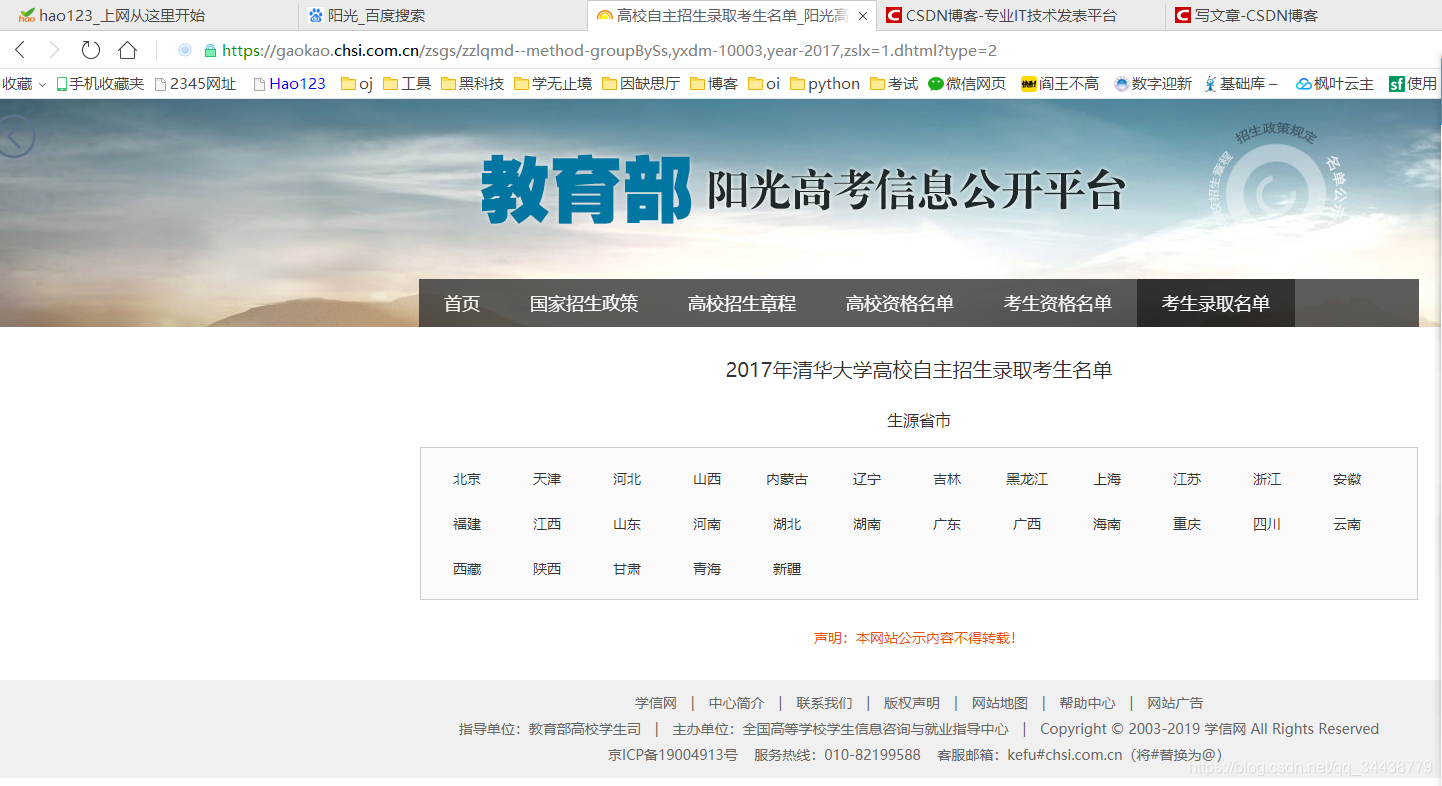
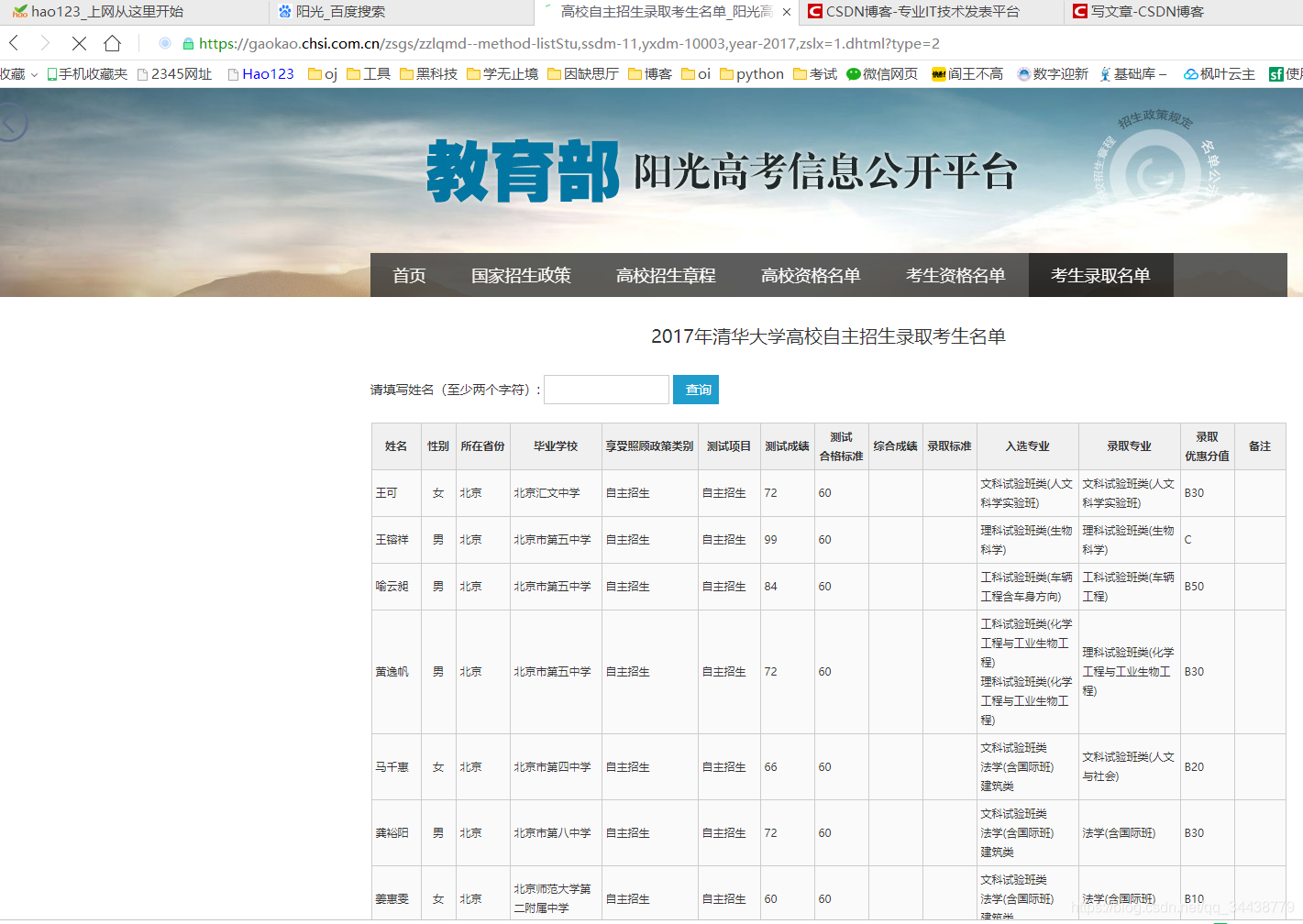
在上面的第二个图的地址栏,我们发现了一些参数
https://gaokao.chsi.com.cn/zsgs/zzlqmd--method-listStu,ssdm-14,yxdm-10003,year-2017,zslx=1.dhtml?type=2
ssdm:省市代码
yxdm:院校代码(神奇的拼音)
year:年份
type:招生计划
然后鼠标右键查看源代码
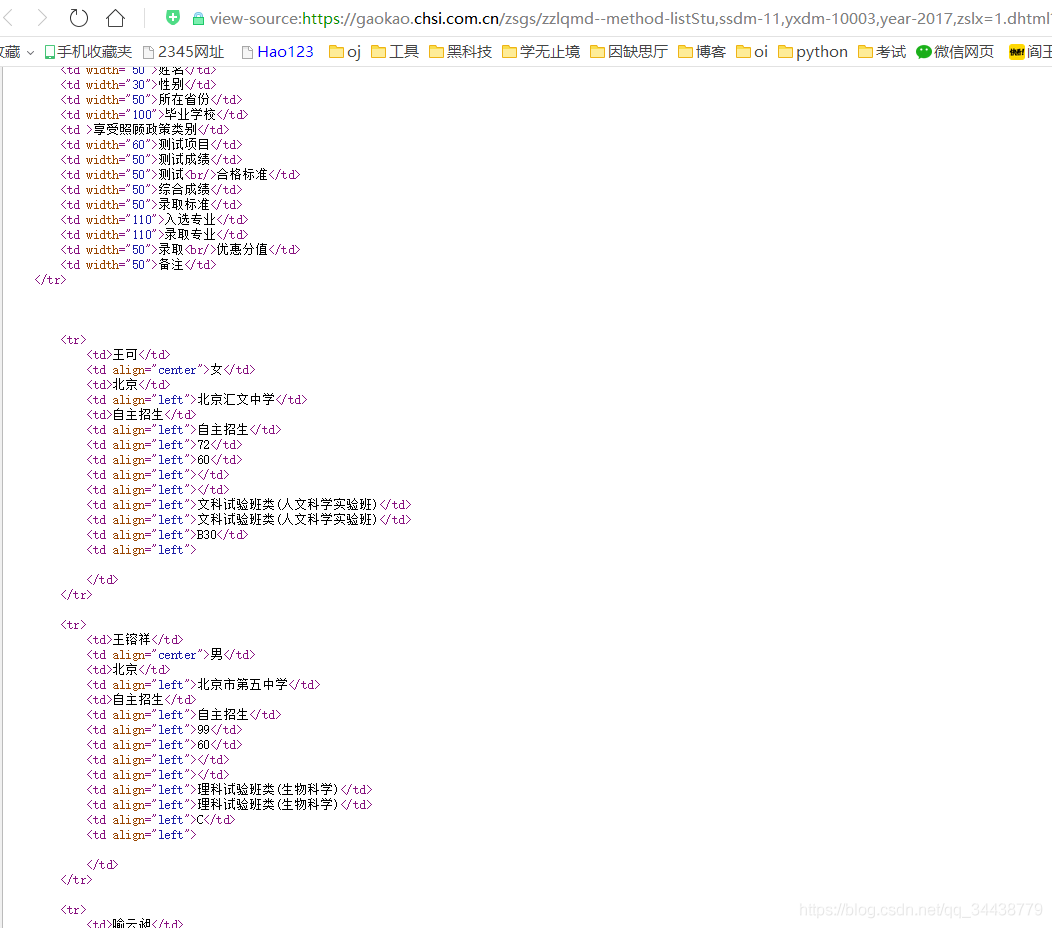
发现名单的数据是用表格的形式来存的
那么我们便可以得到整个解决方案了
- 用requsets 打开相关网页
- BeautifulSoup来把表格数据提取出来
这里我只贴出部分代码
#将某校某年的某省名单存在本地文件里
def get_list(school_code, year, province, file_name):
res = requests.get(constant.url_root + constant.url_list %
(province, school_code, year), headers=constant.headers)
if res.status_code == 200: #网页正常响应
files = open(file_name, "a", encoding='utf-8')
#提取表格部分
soup = BeautifulSoup(res.text)
tables = soup.findAll('table')
tab = tables[0]
first = True
for tr in tab.findAll('tr'):
# 表头不用
if first:
first = False
continue
i = 0
for td in tr.findAll('td'):
i = i + 1
if(is_need(i)):
files.write(td.getText()+' ')
# print (td.getText(),end=' ')
files.write('\n')
files.close()
else:
return None
院校代码和省份代码可百度














 1451
1451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









