



一、Ceph架构介绍
1.1 ceph简介
Ceph 是一个开源的统一的分布式存储系统,可以同时提供块存储、对象存储和文件存储。
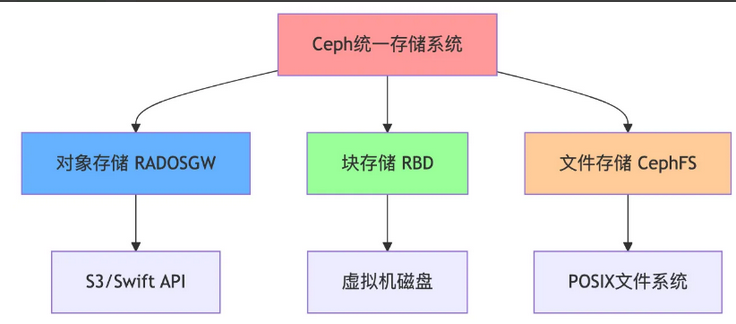
1.1.1 ceph的特性
1、接口统一:
①支持三种存储接口:块存储、文件存储、对象存储。②支持自定义接口,支持多种语言驱动。
2、高性能:多副本设置,在读写操作时候能够高度并行化
①摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。②Ceph客户端读写数据直接与存储设备OSD交互。在块存储和对象存储中无需元数据服务器③能够支持上千个存储节点的规模,支持TB到PB级的数据。
3、高可用性:支持多份强一致性副本,副本能够垮主机、机架、机房、数据中心存放
①副本数可以灵活控制,可以由管理员自行定义②通过CRUSH算法指定副本的物理存储位置以分隔故障域,支持数据强一致性③多种故障场景自动进行修复自愈。④没有单点故障,自动管理。
4、高可扩展性:包括系统规模和存储容量的可扩展,也包括随着系统节点增加进而数据访问带宽的线性增长
①去中心化,采用Crush和HASH环等方法解决中心化问题②Ceph本身并没有主控节点,扩展灵活③随着节点增加而线性增长。
1.2 ceph组成

Ceph存储集群至少需要一个Ceph Monitor、一个manager和OSD守护进程,在运行Ceph文件存储时,还需要ceph元数据服务ceph-mds。
Monitors:Ceph监视器(ceph-mon)维护集群状态的映射,包括监视器映射、管理器映射、OSD映射和 CRUSH 映射。这些映射是Ceph守护进程相互协调所需的关键集群状态。Monitor还负责管理守护进程和客户机之间的身份验证。为了冗余和高可用性,通常至少需要三个监视器。
Managers: Ceph管理进程(ceph-mgr)守护进程负责跟踪Ceph集群的运行指标和当前状态,包括存储利用率、当前性能指标和系统负载。Ceph Manager 守护进程还托管基于python的模块来管理和公开Ceph集群信息,包括基于web的Ceph dashboard 和 REST API 高可用通常需要至少两个管理器。
Ceph OSDs: 对象存储守护进程(ceph-osd)存储数据,处理数据复制,恢复,重新平衡并通过检查其他Ceph OSD 守护进程的心跳来为Ceph Monitor 和 Manager 提供一些监控信息.当 Ceph 集群设定有2个副本时,至少需要2个OSD守护进程,集群才能达到 active+clean 状态( Ceph 默认有3个副本,但你可以调整副本数),至少3 Ceph OSDs通常需要冗余和高可用性。简单理解,Ceph 是通过一个个 OSD 来存储数据的,Ceph 默认的OSD 是3个,但是可以手动设置为2个,最少2个才能使集群达到健康可用的状态,并且使用 OSD 可以实现数据的高可用。
MDSs:Ceph元数据服务器(MDS,ceph-mds)Ceph元数据服务器允许POSIX文件系统用户执行基本命令(如ls、find等),而不会给Ceph存储集群带来巨大的负担。
Ceph将数据作为对象存储在逻辑存储池中,使用 CRUSH算法,Ceph计算哪个对象应该被放置到哪个PG里,并进一步计算哪个Ceph OSD守护进程应该存放PG,CRUSH 算法使Ceph存储集群能够动态伸缩、再平衡和恢复
补充:ceph-osd是后台的守护进程,每个OSD都对应一个独立的ceph-osd,通过与同一PG组的其他的osd交换心跳信号,检测状态将结果上报给MON,MON负责接受OSD的状态报告,更新集群的OSD Map,维护集群状态的一致性。
1.3 ceph 架构
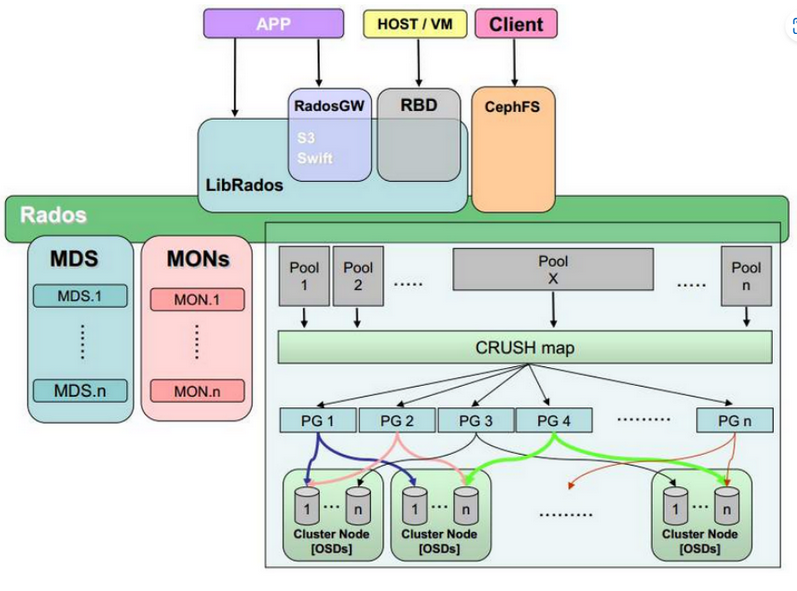
Monitor:一个 Ceph 集群需要多个 Monitor 组成的小集群,它们通过 Paxos 同步数据,用来保存 OSD 的元数据。
OSD:OSD 全称 Object Storage Device,也就是负责响应客户端请求返回具体数据的进程,一个Ceph集群一般有很多个OSD。
CRUSH:CRUSH 是 Ceph 使用的数据分布算法,类似一致性哈希,让数据分配到预期的位置。
PG:PG全称 Placement Groups,是一个逻辑的概念,一个PG 包含多个 OSD 。引入 PG 这一层其实是为了更好的分配数据和定位数据。
Object:Ceph 最底层的存储单元是 Object对象,每个 Object 包含元数据和原始数据。
RADOS:实现数据分配、Failover 等集群操作。
Libradio:Libradio 是RADOS提供库,因为 RADOS 是协议,很难直接访问,因此上层的 RBD、RGW和CephFS都是通过libradios访问的,目前提供 PHP、Ruby、Java、Python、C 和 C++的支持。
MDS:MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
RBD:RBD全称 RADOS Block Device,是 Ceph 对外提供的块设备服务。
RGW:RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
CephFS:CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。
1.4 三种存储类型
1.4.1 块存储(RBD - RADOS Block Device)

Ceph提供的分布式块设备服务,基于RADOS分布式存储系统,将RADOS存储池中的数据以块的形式抽象为可挂载、可读写的虚拟设备,可像本地硬盘一样格式化和挂载。
可支持精简配置,按需占用物理存储;支持快照、克隆、多副本/纠删码,保障数据高可用;提供内核级和用户态驱动,适配不同性能需求。
librbd和KRBD是RBD的两种核心访问方式,分别对应用户态API和内核态驱动。
数据组织方式:每个RBD镜像被分割为固定大小的对象(默认4MB),通过CRUSH算法发布到OSD上,元数据存储到RADOS的专属pool中。
优点:
a. 通过 Raid 与 LVM 等手段,对数据提供了保护。
b. 多块廉价的硬盘组合起来,提高容量。
c. 多块磁盘组合出来的逻辑盘,提升读写效率。
缺点:
a. 采用 SAN 架构组网时,光纤交换机,造价成本高。
b. 主机之间无法共享数据。
适用场景
云计算虚拟机磁盘:如 OpenStack Cinder、Kubernetes Rook。
数据库存储:需低延迟、高吞吐的持久化块设备(如 MySQL、PostgreSQL)。
备份与克隆:利用快照快速创建虚拟机副本。
1.4.2 文件存储(CephFS - Ceph File System)
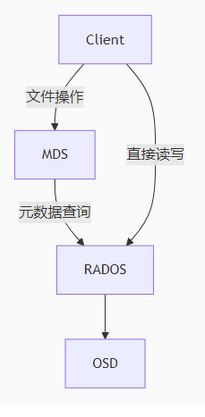
CephFS(Ceph File System)是 Ceph 分布式存储系统提供的POSIX 兼容的分布式文件系统,它基于 Ceph 底层的 RADOS(可靠自主分布式对象存储)架构,提供高可用、高扩展、高性能的文件存储服务。与 Ceph 的另外两种存储服务(块存储 RBD 和对象存储 RGW)相比,CephFS 专注于提供类传统文件系统的层级结构访问,支持目录、文件、权限控制等标准文件系统特性,同时具备分布式系统的横向扩展能力。
MDS,CephFS 的核心组件,专门负责元数据管理(目录结构、文件属性、权限等),是 CephFS 区别于其他 Ceph 服务的关键。
元数据(Metadata)是描述文件 / 目录的信息(如名称、路径、大小、权限、创建时间等),对于传统的分布式文件系统来说,元数据管理的瓶颈限制了其扩展性。
而CephFS 通过 MDS 解决这一问题:
元数据集中管理:MDS 专门处理元数据请求(如ls、mkdir、stat等),避免数据存储节点(OSD)承担额外负载。
元数据分片(Sharding):支持多 MDS 部署,将元数据分片到不同 MDS 节点,实现元数据服务的横向扩展。
元数据缓存:MDS 缓存热点元数据,加速访问;客户端也会缓存元数据,减少重复请求。
适用场景
共享文件系统:企业 NAS、HPC(高性能计算)存储。
容器持久化存储:Kubernetes PVC 通过 CSI 驱动挂载 CephFS。
日志与文档管理:多节点并发读写(如 NFS 替代方案)。
1.4.3 对象存储 (RGW - RADOS Gateway)

RGW 是兼容 Amazon S3 和 OpenStack Swift API 的 RESTful 对象存储网关,将 HTTP 请求转换为 RADOS 对象操作。
其中:
①对象是数据的基本存储单元,由三部分组成:
数据本身:文件内容(如一张图片、一段视频);
元数据(Metadata):描述数据的属性信息(如创建时间、大小、格式、自定义标签等),支持扩展(可添加业务相关信息,如图片分辨率、视频编码等);
唯一标识符(UUID):全球唯一的字符串,用于定位和访问对象,替代传统文件系统的路径。
②存储桶(Bucket):用于组织和管理对象的容器,相当于 “顶级目录”,但无层级嵌套关系(扁平结构)。每个桶有唯一名称(全局或区域内唯一),可设置访问权限、生命周期规则等。
③API 接口:通常通过 RESTful API(如 HTTP/HTTPS 的 GET、PUT、DELETE 等)访问,无需挂载文件系统,适合跨网络、跨平台访问。
工作原理:
数据写入流程
①客户端通过 API(如PUT /bucket/object)发送数据到对象存储服务;
②系统生成唯一 UUID 标识该对象,将数据、元数据与 UUID 关联;
③数据被分割为固定大小的块(如 128MB),分布式存储在后端节点,并可能复制多份(确保高可用);
④元数据被存储在专门的元数据服务中,记录对象的位置、属性等信息。
数据读取流程
①客户端通过 UUID 或 “桶 + 对象名”(如GET /bucket/object)发起请求;
②元数据服务查找对象的存储位置;
③系统从后端节点读取数据并返回给客户端。
核心特性:
海量存储与高扩展性
采用分布式架构,可通过增加节点线性扩展存储容量(从 TB 到 EB 级),无需担心传统文件系统的目录数、文件数限制。
强一致性与高可用性
数据默认多副本存储(如 3 副本),单个节点故障不影响数据访问;部分系统支持跨区域复制,实现异地灾备。
灵活的元数据管理
元数据可自定义扩展,支持基于元数据的快速检索(如按 “创建时间”“文件类型” 筛选),适合复杂业务场景。
按需付费与低成本
支持 “按需扩容”,按实际存储容量和访问量计费;可通过纠删码(Erasure Coding)替代部分副本,降低存储成本(如 15.3 纠删码仅需 30% 额外空间,远低于 3 副本的 200%)。
适合非结构化数据
针对图片、视频、日志等非结构化数据优化,不适合需要频繁随机读写的场景(如数据库)。
适用场景:
云原生存储:替代 AWS S3 构建私有云存储(如 MinIO 竞品)。
大数据分析:Hadoop 通过 S3A 接口访问 RGW。
备份归档:结合生命周期策略自动迁移冷数据。
| 维度 | RBD(块存储) | CephFS(文件存储) | RGW(对象存储) |
|---|---|---|---|
| 数据模型 | 线性地址空间 | 目录树结构 | 扁平命名空间(Bucket/Object) |
| 扩展性 | 单客户端独占 | 多客户端共享 | 高并发 HTTP 访问 |
| 典型场景 | 虚拟机磁盘、数据库 | 共享文件系统、HPC | 云存储、大数据湖 |
| 接口协议 | 块设备(/dev/rbd) | POSIX 文件系统 | S3/Swift REST API |
| 元数据管理 | 无(直接操作块) | MDS 集群动态分区 | RGW 内置管理(RADOS 存储) |
二、OSD及相关存储类型与配置介绍
2.1 osd介绍
OSD 是运行在服务器上的后台进程(ceph-osd),每个 OSD 进程通常对应一块独立的存储介质(如 SSD、HDD),负责将介质格式化为 Ceph 支持的存储格式(如 BlueStore),并接管该介质的所有数据读写操作。
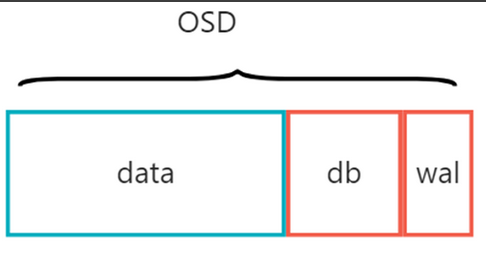
osd主要分为三个组成部分,分别是data,db,wal。这三个部分可以使用不同的存储介质。
其中:
WAL:WAL(预写日志)是一块顺序写入的日志区域,用于临时记录 OSD 收到的写请求。在数据真正写入 Data 区之前,所有修改操作会先写入 WAL—— 这是一种 “先写日志,再写数据” 的可靠性保障机制,类似数据库中的事务日志。主要作用是防止数据丢失。
DB:DB 是存储元数据(Metadata) 的数据库分区,基于 RocksDB(一种嵌入式 KV 数据库)实现。元数据包括:①对象的属性(如大小、创建时间、所有者);②对象与 PG 的映射关系;③数据块的物理位置(在 Data 区的偏移量);④校验和(Checksum)信息(用于数据完整性校验)。主要作用是加速数据访问。
Data:Data 区是 OSD 中最大的分区,用于存储对象的实际数据(如文件内容、块设备数据等)。Ceph 将数据拆分为固定大小的对象(默认 4MB),这些对象的二进制内容最终都保存在 Data 区。主要特点是大容量、低IOPS敏感。
当客户端向 OSD 写入一个对象时,WAL、DB、Data 的交互流程如下:
写 WAL:OSD 先将 “写入对象” 的操作记录到 WAL(顺序写,速度快),确保操作不丢失;
写 DB:同时,将该对象的元数据(如 OID、大小、在 Data 区的预期位置)写入 DB 的 RocksDB(先写 RocksDB 的内存缓存,再异步刷盘,依赖 WAL 保障);
写 Data 区:OSD 在 Data 区分配物理空间,将对象的实际数据写入(可通过缓存优化,批量刷盘);
完成确认:当数据成功写入 Data 区后,OSD 删除 WAL 中对应的记录(日志使命完成),并向客户端返回 “写入成功”。
在资源有限的情况下,尽可能将性能需求高的部分放在最快的存储介质上。因此就会有多种组合方式,例如:
WAL(NVME),DB(NVME),Data(NVME)
WAL(NVME),DB(NVME),Data(NVME)
WAL(NVME),DB(NVME),Data(NVME)
......
2.2 存储类型介绍
基于硬盘的配置,可以根据实际的性能需求将OSD的不同部分放在不同的存储介质上,可以获得不同的收益。SoveCloud管理平台预设了四种存储类型:分别为归档、标准、高性能、全闪,性能由低到高,全闪为最优性能。其中高性能在间歇性业务请求爆发的场景下可以做到性能接近全闪,但是成本远低于全闪。
性能越高的存储类型成本越高,四种存储类型可以灵活配置,搭配使用。
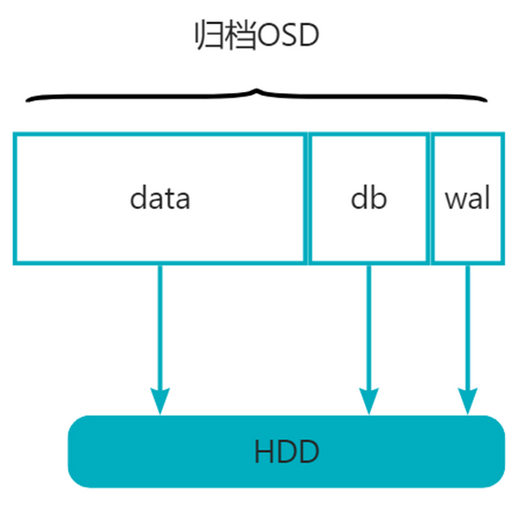
2.2.1 归档osd
归档osd只需要HDD,容量不限。
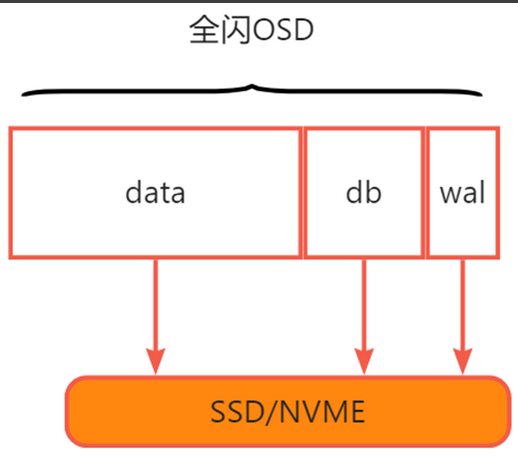
2.2.2 全闪OSD
全闪osd只需要SSD/NVME,容量不限。
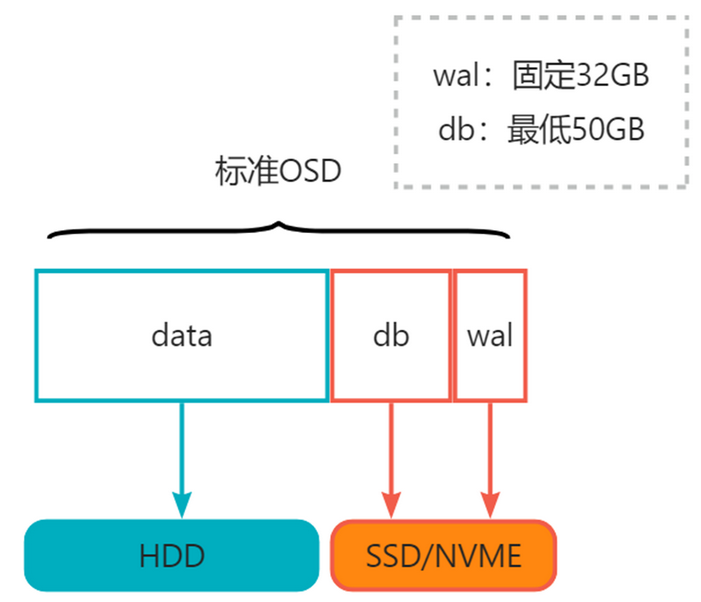
2.2.3 标准OSD
标准类型OSD中SSD/NVME最低需要82GB,HDD容量不限;建议db/data大小不超过4%。
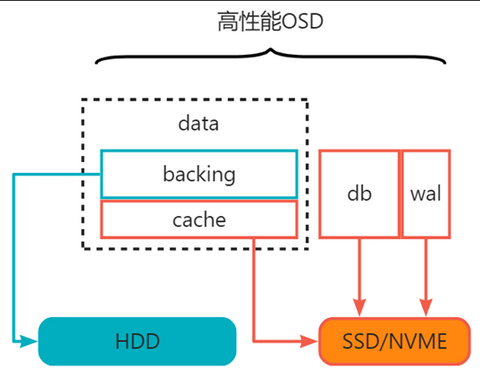
2.2.4 高性能OSD
在高性能类型OSD中,SSD/NVME与HDD类型硬盘之间存在比值关系,
其中WAL固定大小32GB,
DB分为两种情况:①最低容量:DB/HDD = 2%,且满足最低大小50GB; ②最大容量:DB/HDD = 4%(多出的SSD容量补充道data-cache中)
data-cache也分为两种情况:①最低容量:data-cache/HDD = 5%; ② 最大容量:data-cache/HDD < 100%
其中高性能OSD计算规则为:
(1)DB部分满足DB/HDD = 2%,才能继续创建data-cache部分;
(2)如果SSD容量充足,采用多于容量的分配方式:
①优先将DB部分空间补足为DB/HDD = 4%
②多出的SSD容量全部留给data-cache部分
三、推荐方案——高性能
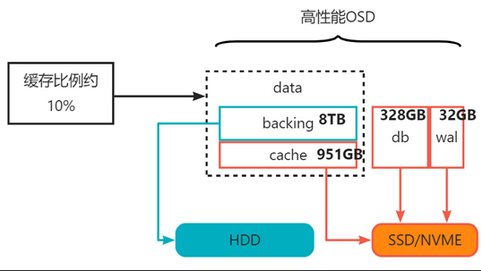
3.84TB SSD/NVME对应3个8TB HDD,计算SSD/NVME占比如下所示:
1、分成3个OSD,每个OSD容量: 3.84TB / 3 * 1024 ≈1311GB
2、db+data-cache:1311-32=1279GB
3、 db:HDD 最大占用:8TB10240.04 ≈ 328GB
4、剩余容量分给data-cache:1279-328≈951GB,缓存比例为951GB/(8TB*1024)≈10%
你的点赞、收藏和关注这是对我最大的鼓励。

















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









