






使用用词袋(a bag of words)模型提取频繁项
文本分析的主要目标之一是将文本转化为数值形式。以便使用机器进行学习。我们考虑下,数以百万计的单词文档,为了去分析这些文档,我们需要提取文本 并且将其转化为数值符号。
机器学习算法需要处理数值的数据,以便他们能够分析数据并且提取有用的信息。用词袋模型从文档的所有单词中提取特征单词,并且用这些特征项矩阵建模。这就使得我们能够将每一份文档描述成一个用词袋。我们只需要记录单词的数量,语法和单词的顺序都可以忽略。
那么一份文档的单词矩阵是怎样的呢。一个文档的单词矩阵是一个记录出现在文档中的所有单词的次数。因此 一份文档能被描述成各种单词权重的组合体。我们能够设置条件,筛选出更有意义的单词。顺带,我们能构建出现在文档中所有单词的频率柱状图,这就是一个特征向量。这个特征向量将被用在文本分类。
思考一下几句话:
- 句1:the children are playing in the hall
- 句2:The hall has a lot of space
- 句3:Lots of children like playing in an open space
the、children 、are 、playing、in 、hall、has 、a、lot、of、space、like、an、open
我们可以用出现在每句话中的单词次数为每一句话构建一个柱状图。每一个特征矩阵都将有14维,因为有14个不同的单词:
句1:[2 1 1 1 1 1 0 0 0 0 0 0 0 0]
句2:[1 0 0 0 0 1 1 1 1 1 1 0 0 0]
句3:[0 1 0 1 1 0 0 0 1 1 1 1 1 1]
既然我们已经提取这些特征向量,我们能够使用机器学习算法分析这些数据
如何使用NLTK构建用词袋模型呢?创建一个python程序 ,导入如下包
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from nltk.corpus import brown读入布朗语料库文本,我们将读入5400个单词,你能按照自己的意愿输入
# Read the data from the Brown corpus
input_data = ' '.join(brown.words()[:5400])# Number of words in each chunk
chunk_size = 800定义分块函数:
#将输入的文本分块,每一块含有N个单词
def chunker(input_data,N):
input_words = input_data.split(' ')
output=[]
cur_chunk = []
count = 0
for word in input_words:
cur_chunk.append(word)
count+=1
if count==N:
output.append(' '.join(cur_chunk))
count,cur_chunk =0,[]
output.append(' '.join(cur_chunk))
return output 对输入文本分块
text_chunks = chunker(input_data, chunk_size)将所分的块转换为字典项
# Convert to dict items
chunks = []
for count, chunk in enumerate(text_chunks):
d = {'index': count, 'text': chunk}
chunks.append(d)max_df:可以设置为范围在[0.0 1.0]的float,也可以设置为没有范围限制的int,默认为1.0。这个参数的作用是作为一个阈值,当构造语料库的关键词集的时候,如果某个词的document frequence大于max_df,这个词不会被当作关键词。如果这个参数是float,则表示词出现的次数与语料库文档数的百分比,如果是int,则表示词出现的次数。如果参数中已经给定了vocabulary,则这个参数无效
min_df:类似于max_df,不同之处在于如果某个词的document frequence小于min_df,则这个词不会被当作关键词
# Extract the document term matrix
count_vectorizer = CountVectorizer(min_df=7, max_df=20)
document_term_matrix = count_vectorizer.fit_transform([chunk['text'] for chunk in chunks])提取词汇并显示。单词引用于之前步骤所提取的并去重的一系列单词。
# Extract the vocabulary and display it
vocabulary = np.array(count_vectorizer.get_feature_names())
print("\nVocabulary:\n", vocabulary)
创建显示列:
# Generate names for chunks
chunk_names = []
for i in range(len(text_chunks)):
chunk_names.append('Chunk-' + str(i+1))输出文档项矩阵:
# Print the document term matrix
print("\nDocument term matrix:")
formatted_text = '{:>12}' * (len(chunk_names) + 1)
print('\n', formatted_text.format('Word', *chunk_names), '\n')
for word, item in zip(vocabulary, document_term_matrix.T):
# 'item' is a 'csr_matrix' data structure
output = [word] + [str(freq) for freq in item.data]
print(formatted_text.format(*output))
完整代码如下:
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from nltk.corpus import brown
#将输入的文本分块,每一块含有N个单词
def chunker(input_data,N):
input_words = input_data.split(' ')
output=[]
cur_chunk = []
count = 0
for word in input_words:
cur_chunk.append(word)
count+=1
if count==N:
output.append(' '.join(cur_chunk))
count,cur_chunk =0,[]
output.append(' '.join(cur_chunk))
return output
# Read the data from the Brown corpus
input_data = ' '.join(brown.words()[:5400])
# Number of words in each chunk
chunk_size = 800
text_chunks = chunker(input_data, chunk_size)
# Convert to dict items
chunks = []
for count, chunk in enumerate(text_chunks):
d = {'index': count, 'text': chunk}
chunks.append(d)
# Extract the document term matrix
count_vectorizer = CountVectorizer(min_df=7, max_df=20)
document_term_matrix = count_vectorizer.fit_transform([chunk['text'] for chunk in chunks])
# Extract the vocabulary and display it
vocabulary = np.array(count_vectorizer.get_feature_names())
print("\nVocabulary:\n", vocabulary)
# Generate names for chunks
chunk_names = []
for i in range(len(text_chunks)):
chunk_names.append('Chunk-' + str(i+1))
# Print the document term matrix
print("\nDocument term matrix:")
formatted_text = '{:>12}' * (len(chunk_names) + 1)
print('\n', formatted_text.format('Word', *chunk_names), '\n')
for word, item in zip(vocabulary, document_term_matrix.T):
# 'item' is a 'csr_matrix' data structure
output = [word] + [str(freq) for freq in item.data]
print(formatted_text.format(*output))
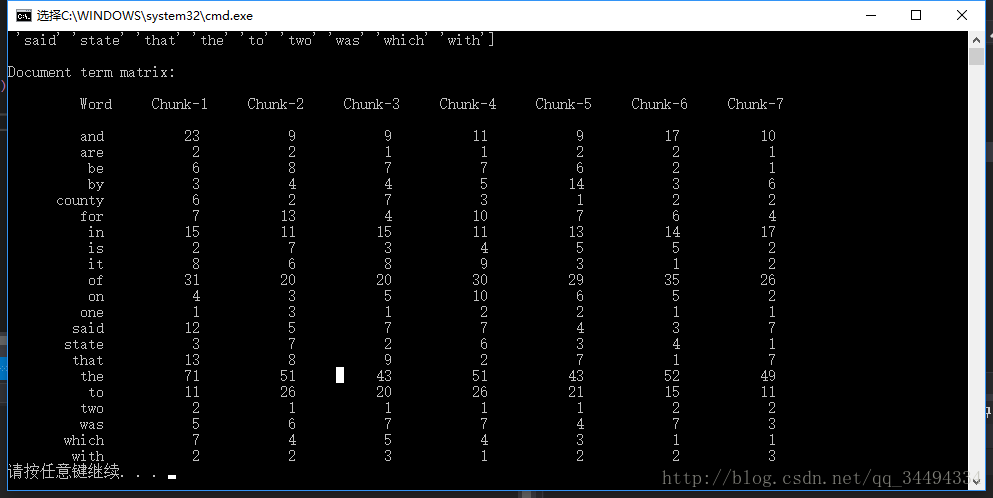
我们能够看到所有的文档单词矩阵和每个单词在每一块的出现次数
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









