






0 前言
大家好,我是小林!
本篇文章是 Spark 系列的第三篇文章。前两篇文章可以看这里:

本文概览
在第二篇文章中,小林讲到一个 Spark 任务首先要生成数据依赖图,也就是 Job 的逻辑执行图,然后根据一定的规则转化成 Job 的物理执行图,才能真正的执行。并且在第一篇文章中举了一个 word count 的例子,你可以回顾下这两张图,理解一下第二篇讲的逻辑执行图到物理执行图的转换:
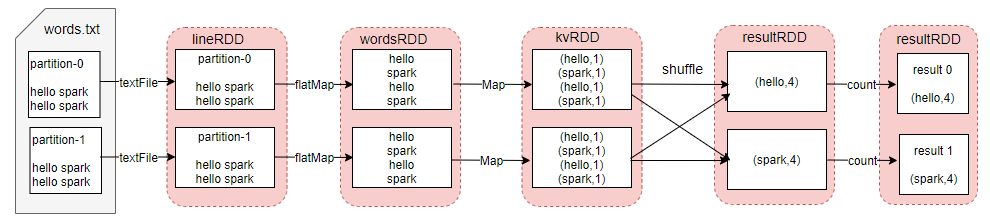
wordcount 逻辑执行图
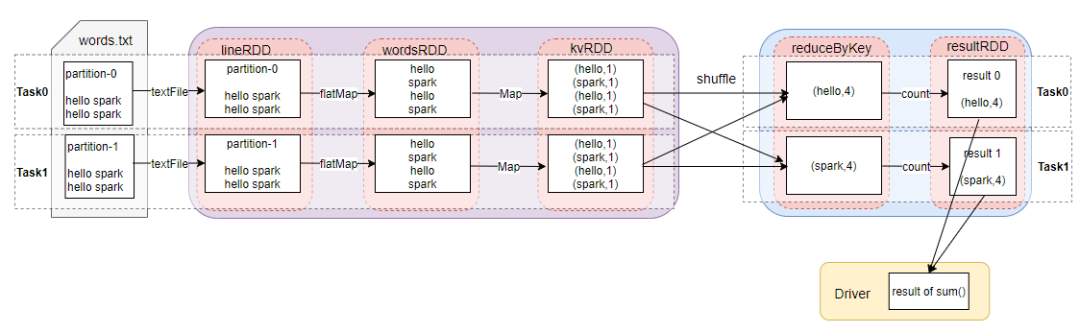
wordcount 物理执行图
上面第一张图描述的是数据依赖关系,是一种抽象的流程图,而第二张图是实际可以执行的一个个任务流图,每条 task 流水线都会有数据集抽象,供于计算。所以,前者是一个总览的流程图,后者是一个实实在在可以执行的任务流程图。他们之间的联系就是,Job 物理执行图会根据逻辑执行转换成物理执行。
你可能会很好奇,小林为什么一直在提 Job 物理执行图会根据逻辑执行转换成实际的物理执行?原因是分布式的精髓,在于如何把抽象的计算流图,转化为实实在在的分布式计算任务,然后以并行计算的方式交付执行。
本文,小林跟大家聊聊,Spark 内部有哪些进程,它们是如何协作实现分布式计算?
在企业里有哪些 Spark 部署方式?
Spark 任务的提交方式有哪些?
1 Spark 有哪些进程?
小林先给出一张总体的部署图,来熟悉下,Spark 系统中有哪些角色和进程。
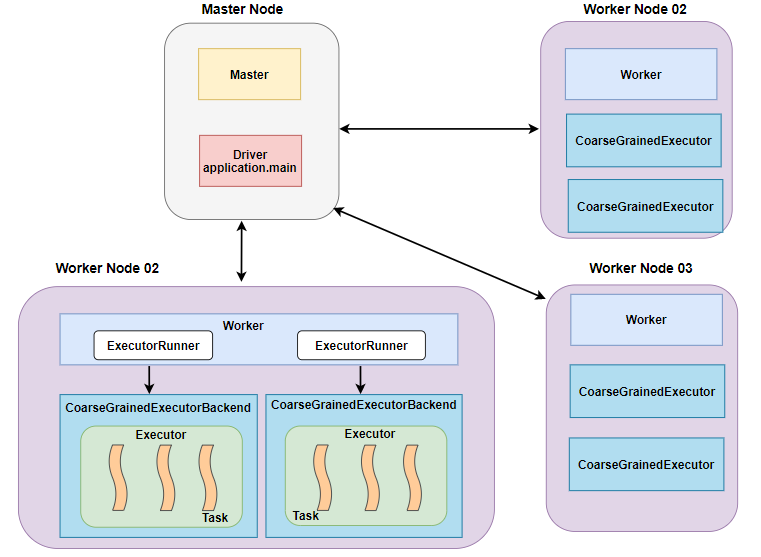
从上述架构图中可以看到 :
-
整个 Spark 集群中分为 Master 节点和 Worker 节点,相当于 Hadoop 的 Master 和 Slave 节点。
-
Master 节点上常驻 Master 守护进程,负责管理全部的 Worker 节点。
-
Worker 节点上常驻 Worker 守护进程,负责与 Master 节点通信并管理 executors。
-
Driver 官方解释是 “The process running the main function of the application and creating the SparkContext”,SparkContext 包罗万象,它在提供 Spark 运行时上下文的同时(包括调度系统,存储系统,内存管理,RPC 通信),也可以为为我们提供创建、转换、计算分布式数据集的开发 API。
Application 就是用户自己写的 Spark 程序(driver program),比如 WordCount.scala。如果 driver program 在 Master 上运行,比如在 Master 上 执行以下命令:
./bin/run SparkPi 10
那么 SparkPi 就是 Master 上的 Driver。如果是 YARN 集群,那么 Driver 可能被调度到 Worker 节点上运行。
-
每个 Worker 上存在一个或者多个 ExecutorBackend 进程。每个进程包含一个 Executor 对象,该对象 持有一个线程池,每个线程可以执行一个 task。
-
每个 application 包含一个 driver 和多个 executors,每个 executor 里面运行的 tasks 都属于 同一个 application。在 Standalone 版本中,ExecutorBackend 被实例化成 CoarseGrainedExecutorBackend 进程。
-
Worker 通过持有 ExecutorRunner 对象来控制 CoarseGrainedExecutorBackend 的启停。
总结一下就是,在 Spark 集群中,一共有 4 种进程。Master 和 Worker 进程,属于资源调度进程,Master 负责整个集群中的资源监控及调度,Worker 负责某台节点的资源调度,它会通过与 Master 通信汇报当台节点的资源使用情况;Driver 和 Executor 进程,是任务调度进程,Driver 主要作用是解析用户代码,构建数据依赖图,然后将数据依赖图转换为分布式任务,并把任务分发到集群中的 Executor 执行,Executor 则是属于真正执行任务的进程,并且会把任务进展向 Driver 进行汇报。
2 Spark 分布式环境部署
Spark 支持很多种分布式部署模式,其中包括,Standalone、YARN、Mesos 以及 Kubernetes。Standalone 是 Spark 自带的资源调度框架,YARN、Mesos以及 Kubernetes 是独立的第三方资源调度框架。本文根据生产中使用较多的两种场景,讲解 Standalone 集群搭建和 Spark on YARN 配置。
Standalone 集群搭建
Standalone 在资源调度层面,采取的是一主多从的架构,Master 在集群中有且仅有一个,worker 可以有多个。所有的 Worker 节点周期性的向 Master 汇报当前节点资源状态,Master 负责统筹整个集群的资源,并对于 Driver 的资源请求做出响应。
对于学习的话,小林建议搭建 3 台 Standalone 集群,1 台 Master节点,2 台 worker 节点。我在 VMware 准备了 4 台虚拟机,为了讲解后续不同的任务提交方式,特意多准备了一台客户端节点。节点规划如下:

第一步,为了保证集群中各个节点间的免密钥通信,在 4 台节点间配置免密钥通信环境;
#1.在每台节点上,使用非对称加密算法,生成各自的私钥、公钥对
ssh-keygen -t rsa
#2.读取各个节点间公钥内容
cat /home/centos/.ssh/id_rsa.pub
#3.将每个节点的公钥内容,追加到其它 3 台节点
vim ~/.ssh/authorized
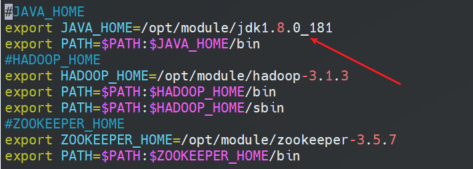
第二步,在安装 Spark 前,需要先安装 Java ,并配置 JAVA_HOME;
#安装配置 Java 环境,将官网下载好的 Java 安装包,上传到虚拟机
vi /etc/profile
#配置JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_181
#重新生效 profile 文件
source /etc/profile
第三步,我们安装 Spark。先在官网上:spark.apache.org 下载安装包,小林下载的是 spark-2.3.1-bin-hadoop2.6.tgz 压缩包,将下载好的压缩包上传到 Master 节点。在 Master 节点上按照如下步骤操作:
#1.解压上传的安装包
tar -zxvf ./spark-2.3.1-bin-hadoop2.6.tgz
#2.进入到安装包的 conf 目录下,配置 slaves.template 中的 worker 节点
mv slaves.template slaves
vi slaves
输入以下内容:

#3.配置 spark-env.sh.template 文件
mv spark-env.sh.template spark-env.sh
#4.配置如下内容:
export SPARK_MASTER_HOST=node1 #master的 ip
export SPARK_MASTER_PORT=7077 #提交任务的端口,默认是7077
export SPARK_WORKER_MEMORY=3g #每个 worker 能够支配的内存数
export SPARK_WORKER_CORES=2 #每个worker 从节点能够支配的 core 的个数
export JAVA_HOME=/opt/module/jdk1.8.0_181 #依赖的 Java 环境
#5.同步该安装包到其它节点上,node2 和 node3
scp -r ./spark-2.3.1-bin-hadoop2.6 node2:`pwd`
scp -r ./spark-2.3.1-bin-hadoop2.6 node3:`pwd`
#6.启动集群,进入 sbin 目录下,执行命令
./start-all.sh
至此, Spark 集群,Standalone 模式已经搭建完毕!细心的小伙伴可能已经发现,不是还有 client 要搭建嘛,怎么步骤中没有看到?搭建客户端很简单,只需要将下载的 Spark 安装包,原封不动的上传到 node04 节点即可。
Spark on YANR 配置
在讲 Spark on YARN 的前提是,小林已经把 Hadoop 集群给配置好了。由于 Hadoop 集群配置不是本文的重点,本文不讲 YARN 的配置,默认 YARN 已经配置好了。Spark 基于 YARN 进行任务调度,只需要在 Spark 客户端(node04)做如下配置即可:

至此,Spark 分布式环境已经部署完。我们可以使用 Spark pi 任务测试,standalone 环境部署是否成功。
standalone 提交命令:
./spark-submit --master spark://node1:7077 --class
org.apache.spark.examples.SparkPi /opt/module/spark-2.3.1-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.3.1.jar 100
Spark on YARN 提交命令:
./spark-submit --master yarn --class
org.apache.spark.examples.SparkPi ../examples/jars/spark- examples_2.11-2.3.1.jar 100
如果出现 pi 的计算结果为 3.14,说明分布式集群已经部署成功。
3 Spark 任务提交方式有哪些?
基于 Standalone 模式一共有 2 种提交任务的方式,分别是 cluster 提交和 client 提交。下面分别叙述两种任务的提交方式。
standalone-client 提交任务方式
./spark-submit --master spark://mynode1:7077
--deploy-mode client
--class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11- 2.3.1.jar 100
其执行流程如图所示:
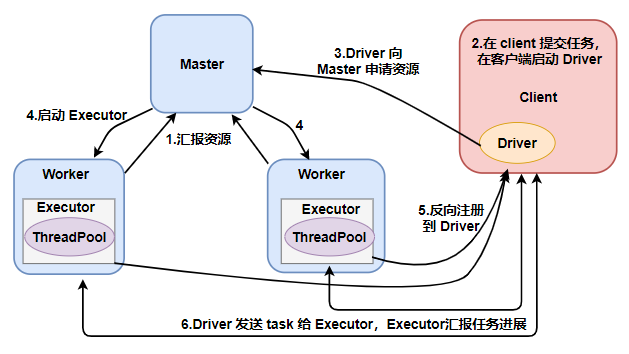
client 任务提交
standalone-cluster 提交任务方式
./spark-submit --master spark://mynode1:7077
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11- 2.3.1.jar 100
为了方便理解,我也画了 集群模式提交任务的流程:
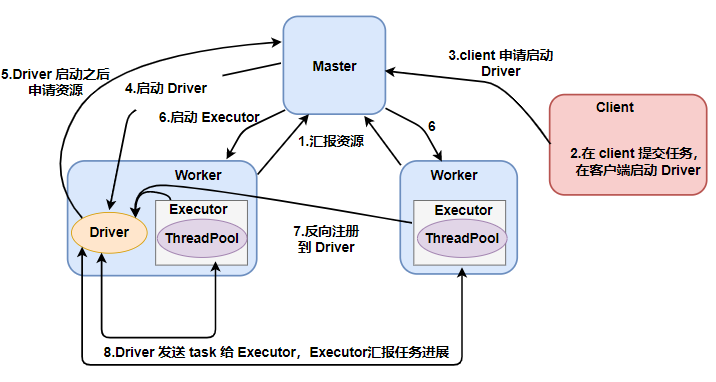
cluster任务提交
对比下 client 和 cluster 两种提交任务的方式,发现 Driver 进程所启动的位置不一样。对于 standalone-client 提交任务方式,Driver 进程会在客户端启动,这里的客 户端就是指提交应用程序的当前节点。在 Driver 端可以看到 task 执行的情 况。
生产环境下建议不要使用 client 模式,是因为:假设要提交 100 个 Application 到集群运行,Driver 每次都会在 client 端启动,那么就会导致 客户端 100 次网卡流量暴增的问题。client 模式适用于程序测试,不适用于生产环境,在客户端可以看到 task 的执行和
对于 standalone-cluster 提交任务方式,Driver 进程是在集群某一台 Worker 上启动的,在客户端是无法查看 task 的执行情况的。假设要提交 100 个 Application 到集群运行,每次 Driver 会 随机在集群中某一台 Worker 上启动,那么这 100 次网卡流量暴增的问题 就散布在集群上。
所以,生产环境中,建议使用 cluster 模式提交任务。
4 总结
本文提到,分布式计算的核心在于,如何把抽象的逻辑执行图(数据依赖图),转化为实实在在的分布式计算任务,之后并行计算。聊到了 Spark 的进程,Master 和 Worker 进程,属于资源调度进程,Driver 和 Executor 属于任务调度进程。Driver 和 Executors 进行协作,完成一个 Spark 应用程序的执行。
其中 Driver 主要解析用户代码,构建数据依赖图,然后将数据依赖图转换为分布式任务,并通过 RPC 发给集群中的 Executors 执行。Executor 在收到任务后,会调用内部线程池,结合之前分配好的数据分片,并发执行任务代码。
Executor 会负责处理 RDD 的一个数据分片子集,并且 Executor 在执行过程中,会向 Driver 汇报任务状态,Driver 在收到任务状态后,会依据 Job 的物理执行图上划分的 Stage,依次有序的将下一阶段任务再次发给集群中的 Executor 执行,直到 Application 中所有的任务完成。
最后,我们介绍了 Spark 的 Standalone 模式的分布式环境搭建,并给出了详细具体的实操步骤,阐述了客户端和集群 2 中提交任务方式的区别,你重点要掌握分布式集群环境的搭建过程。
好了,这期的文章就到这里,我们下期再见!欢迎,点赞,在看分享!














 5928
5928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









